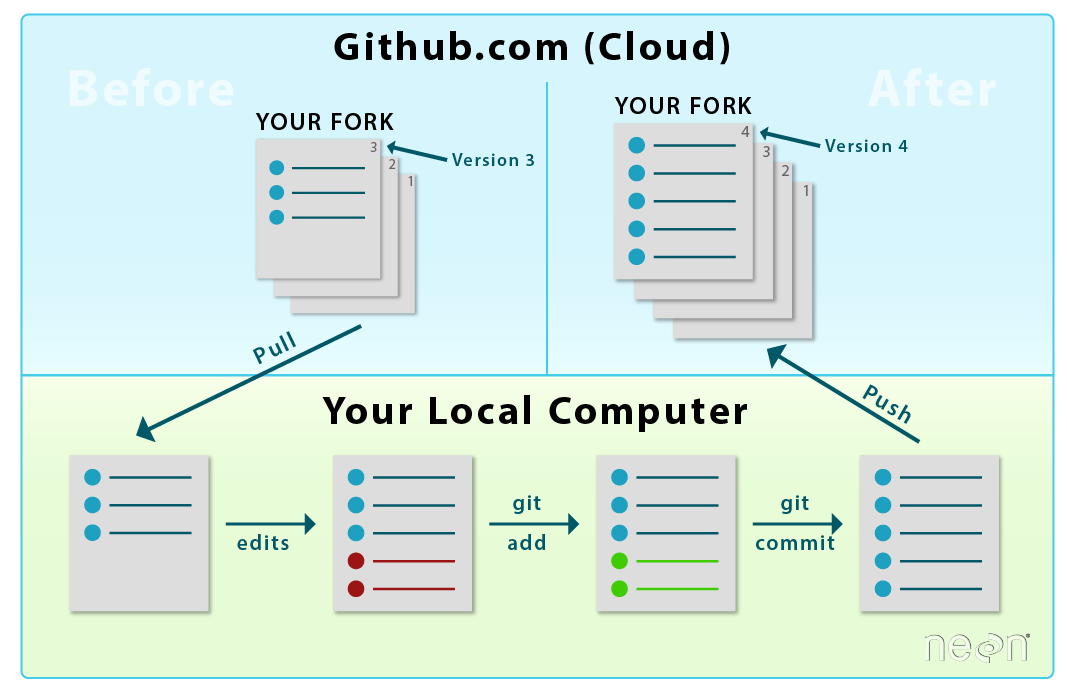
This tutorial covers how to set up a Central Repo as a remote to your local repo
in order to update your local fork with updates. You want to do this every time
before starting new edits in your local repo.
Learning Objectives
At the end of this activity, you will be able to:
Explain why it is important to update a local repo before beginning edits.
Update your local repository from a remote (upstream) central repo.
We've forked (made an individual copy of) the NEONScience/DI-NEON-participants repo to
our github.com account.
We've cloned the forked repo - making a copy of it on our local computers.
We've added files and content to our local copy of the repo and committed
the changes.
We've pushed those changes back up to our forked repo on github.com.
We've completed a Pull Request to update the central repository with our
changes.
Once you're all setup to work on your project, you won't need to repeat the fork
and clone steps. But you do want to update your local repository with any changes
other's may have added to the central repository. How do we do this?
We will do this by directly pulling the updates from the central repo to our
local repo by setting up the local repo as a "remote". A "remote" repo is any
repo which is not the repo that you are currently working in.
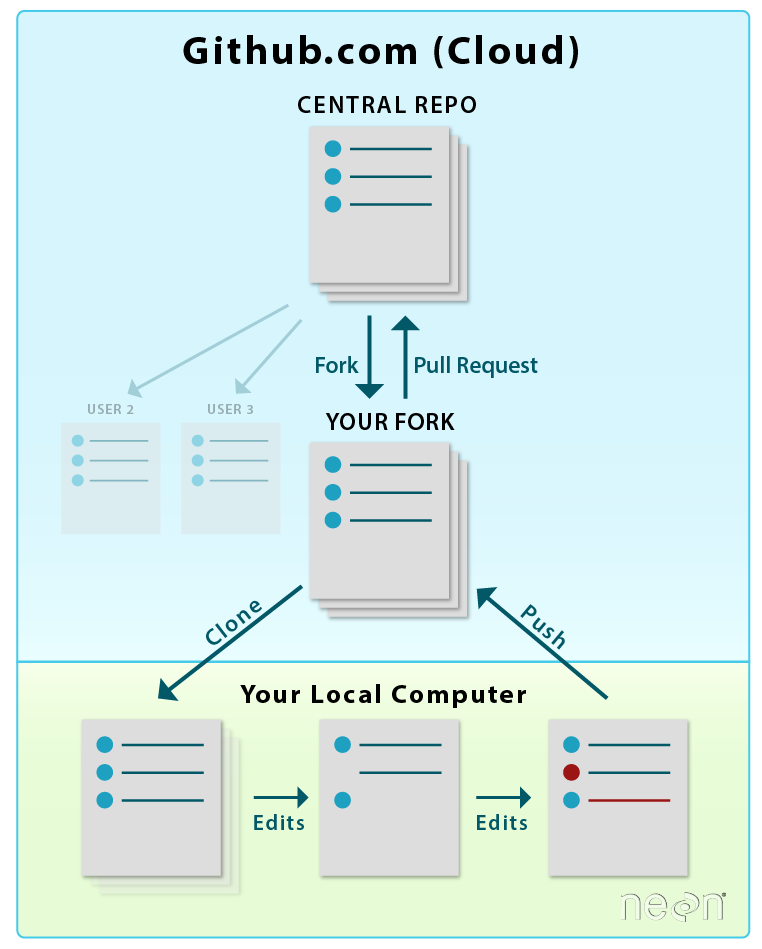
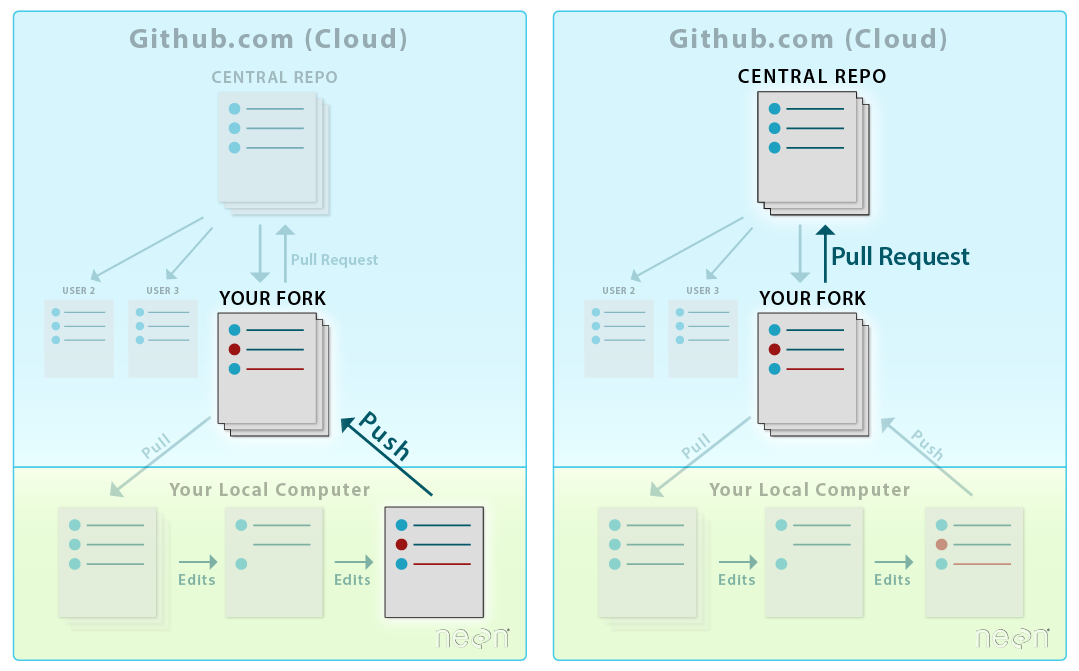
LEFT: You will fork and clone a repo only once . RIGHT: After that,
you will update your fork from the central repository by setting
it up as a remote and pulling from it with git pull .
Source: National Ecological Observatory Network (NEON)
Update, then Work
Once you've established working in your repo, you should follow these steps
when starting to work each time in the repo:
Update your local repo from the central repo (git pull upstream master).
Make edits, save, git add, and git commit all in your local repo.
Push changes from local repo to your fork on github.com (git push origin master)
Update the central repo from your fork (Pull Request)
Repeat.
Notice that we've already learned how to do steps 2-4, now we are completing
the circle by learning to update our local repo directly with any changes from
the central repo.
The order of steps above is important as it ensures that you incorporate any
changes that have been made to the NEON central repository into your forked & local
repos prior to adding changes to the central repo. If you do not sync in this order,
you are at greater risk of creating a merge conflict.
What's A Merge Conflict?
A merge conflict
occurs when two users edit the same part of a file at the same time. Git cannot
decide which edit was first and which was last, and therefore which edit should
be in the most current copy. Hence the conflict.
Merge conflicts occur when the same part of a script or
document has been changed simultaneously and Git can’t determine which change should be
applied. Source: Atlassian
Set up Upstream Remote
We want to directly update our local repo with any changes made in the central
repo prior to starting our next edits or additions. To do this we need to set
up the central repository as an upstream remote for our repo.
Step 1: Get Central Repository URL
First, we need the URL of the central repository. Navigate to the central
repository in GitHub NEONScience/DI-NEON-participants. Select the
green Clone or Download button (just like we did when we cloned the repo) to
copy the URL of the repo.
Step 2: Add the Remote
Second, we need to connect the upstream remote -- the central repository to
our local repo.
Make sure you are still in you local repository in bash
Here you are identifying that is is a git command with git and then that you
are adding an upstream remote with the given URL.
Step 3: Update Local Repo
Use git pull to sync your local repo with the forked GitHub.com repo.
Second, update local repo using git pull with the added directions of
upstream indicating the central repository and master specifying which
branch you are pulling down (remember, branches are a great tool to look into
once you're comfortable with Git and GitHub, but we aren't going to focus on
them. Just use master).
Understand the output: The output will change with every update, several
things to look for in the output:
remote: …: tells you how many items have changed.
From https:URL: which remote repository is data being pulled from. We set up
the central repository as the remote but it can be lots of other repos too.
Section with + and - : this visually shows you which documents are updated
and the types of edits (additions/deletions) that were made.
Now that you've synced your local repo, let's check the status of the repo.
$ git status
Step 4: Complete the Cycle
Now you are set up with the additions, you will need to add and commit those changes.
Once you've done that, you can push the changes back up to your fork on
github.com.
$ git push origin master
Now your commits are added to your forked repo on github.com and you're ready
to repeat the loop with a Pull Request.
git pull upstream master - pull down any changes and sync the local repo with the central repo
make changes, git add and git commit
git push origin master - push your changes up to your fork
Repeat
Have questions? No problem. Leave your question in the comment box below.
It's likely some of your colleagues have the same question, too! And also
likely someone else knows the answer.
In this tutorial, you will learn how to efficiently read in hdf5 reflectance data and metadata, plot a single band and Red-Green-Blue (RGB) band combinations of a reflectance data tile using Python functions created for working with and visualizing NEON AOP hyperspectral data.
After completing this tutorial, you will be able to:
Work with custom Python modules and functions for AOP data
Download and read in tiled NEON AOP reflectance hdf5 data and associated metadata
Plot a single band of reflectance data
Stack and plot 3-band combinations to visualize true color and false color images
Things you'll need to complete this tutorial
Python
You will need a current version of Python (3.9+) to complete this tutorial. We also recommend the Jupyter Notebook IDE to follow along with this notebook.
Install Python Packages
h5py
gdal
neonutilities
pandas
python-dotenv
requests
scikit-image
Data
Data and additional scripts required for this lesson are downloaded programmatically as part of the tutorial. The data used in this lesson were collected over NEON's
Disney Wilderness Preserve (DSNY) field site in 2023. The dataset can also be downloaded from the NEON Data Portal.
Note: for this lesson, we have set up the token as an environment variable, following "Option 2: Set token as environment variable" in the linked tutorial above.
Additional Resources
If you are new to AOP hyperspectral data, we recommend exploring the following tutorial series:
We can combine any three bands from the NEON reflectance data to make an RGB image that will depict different information about the Earth's surface. A natural color image, made with bands from the red, green, and blue wavelengths looks close to what we would see with the naked eye. We can also choose band combinations from other wavelenghts, and map them to the red, blue, and green colors to highlight different features. A false color image is made with one or more bands from a non-visible portion of the electromagnetic spectrum that are mapped to red, green, and blue colors. These images can display other information about the landscape that is not easily seen with a natural color image.
The NASA Goddard Media Studio video "Peeling Back Landsat's Layers of Data" gives a good quick overview of natural and false color band combinations. Note that the Landsat multispectral sensor collects information from 11 bands, while NEON AOP hyperspectral data captures information spanning 426 bands!
First, import the required packages and the neon_aop_hyperspectral module, which includes functions that we will use to read in and visualize the hyperspectral hdf5 data.
import dotenv
import h5py
import matplotlib.pyplot as plt
import neonutilities as nu
import numpy as np
import os
import requests
import sys
import time
This next function is a handy way to download the Python module that we will be use in this lesson. This uses the requests package.
# function to download data stored on the internet in a public url to a local file
def download_url(url,download_dir):
if not os.path.isdir(download_dir):
os.makedirs(download_dir)
filename = url.split('/')[-1]
r = requests.get(url, allow_redirects=True)
file_object = open(os.path.join(download_dir,filename),'wb')
file_object.write(r.content)
Download the module from its location on GitHub, add the ../python_modules directory to the path and import the neon_aop_hyperspectral.py module as neon_hs.
module_url = "https://raw.githubusercontent.com/NEONScience/NEON-Data-Skills/main/tutorials/Python/AOP/aop_python_modules/neon_aop_hyperspectral.py"
download_url(module_url,'../python_modules')
# os.listdir('../python_modules') #optionally show the contents of this directory to confirm the file downloaded
sys.path.insert(0, '../python_modules')
# import the neon_aop_hyperspectral module
import neon_aop_hyperspectral as neon_hs
The first function we will use is aop_h5refl2array. We encourage you to look through the code to understand what it is doing behind the scenes. This function automates the steps required to read AOP hdf5 reflectance files into a Python numpy array. This function also cleans the data: it sets any no data values within the reflectance tile to nan (not a number) and applies the reflectance scale factor so the final array that is returned represents unitless scaled reflectance, with values ranging between 0 and 1 (0-100%).
Data Tip: If you forget the inputs to a function or want to see more details on what the function does, you can use help() or ? to display the associated docstrings.
help(neon_hs.aop_h5refl2array)
# neon_hs.aop_h5refl2array? #uncomment for an alternate way to show the help
Help on function aop_h5refl2array in module neon_aop_hyperspectral:
aop_h5refl2array(h5_filename, raster_type_: Literal['Cast_Shadow', 'Data_Selection_Index', 'GLT_Data', 'Haze_Cloud_Water_Map', 'IGM_Data', 'Illumination_Factor', 'OBS_Data', 'Radiance', 'Reflectance', 'Sky_View_Factor', 'to-sensor_Azimuth_Angle', 'to-sensor_Zenith_Angle', 'Visibility_Index_Map', 'Weather_Quality_Indicator'], only_metadata=False)
read in NEON AOP reflectance hdf5 file and return the un-scaled
reflectance array, associated metadata, and wavelengths
Parameters
----------
h5_filename : string
reflectance hdf5 file name, including full or relative path
raster : string
name of raster value to read in; this will typically be the reflectance data,
but other data stored in the h5 file can be accessed as well
valid options:
Cast_Shadow (ATCOR input)
Data_Selection_Index
GLT_Data
Haze_Cloud_Water_Map (ATCOR output)
IGM_Data
Illumination_Factor (ATCOR input)
OBS_Data
Reflectance
Radiance
Sky_View_Factor (ATCOR input)
to-sensor_Azimuth_Angle
to-sensor_Zenith_Angle
Visibility_Index_Map: sea level values of visibility index / total optical thickeness
Weather_Quality_Indicator: estimated percentage of overhead cloud cover during acquisition
Returns
--------
raster_array : ndarray
array of reflectance values
metadata: dictionary
associated metadata containing
bad_band_window1 (tuple)
bad_band_window2 (tuple)
bands: # of bands (float)
data ignore value: value corresponding to no data (float)
epsg: coordinate system code (float)
map info: coordinate system, datum & ellipsoid, pixel dimensions, and origin coordinates (string)
reflectance scale factor: factor by which reflectance is scaled (float)
wavelengths: array
wavelength values, in nm
--------
Example Execution:
--------
refl, refl_metadata = aop_h5refl2array('NEON_D02_SERC_DP3_368000_4306000_reflectance.h5','Reflectance')
Now that we have an idea of how this function works, let's try it out. First, we need to download a reflectance file. We can download a single 1 km x 1 km reflectance data tile for the DSNY site using the neonutilitiesby_tile_aop function as shown below. This downloads to a data folder specified in savepath. Before downloading a tile, let's take a quick look at when data were collected (and are avaiable) at this site using the list_available_dates function.
# display dates of available data for the directional and bidirectional reflectance data at DNSY
print('Directional reflectance data availability:')
nu.list_available_dates('DP3.30006.001','DSNY') # directional reflectance data ends with .001
print('\nBidirectional reflectance data availability:')
nu.list_available_dates('DP3.30006.002','DSNY') # BRDF and topographic corrected reflectance data ends with .002
Directional reflectance data availability:
RELEASE-2025 Available Dates: 2014-05, 2016-09, 2017-09, 2018-10, 2019-04, 2021-09
Bidirectional reflectance data availability:
PROVISIONAL Available Dates: 2023-04
Next we can also look at the tile extents so we can roughly determine the valid values to enter for the easting and northing, which are input parameters to the by_tile_aop function. First, let's set our NEON token as follows:
# display the first and last UTM coordinates of the DSNY site:
print('First 3 coordinates:\n',dsny_bounds[:3])
print('Last 3 coordinates:\n',dsny_bounds[-3:])
First 3 coordinates:
[(451000, 3103000), (451000, 3104000), (451000, 3105000)]
Last 3 coordinates:
[(463000, 3112000), (464000, 3108000), (464000, 3111000)]
Set up the data directory where we want to download our data.
Data Tip: If you are working from a Windows Operating System (OS), there may be a path length limitation which might cause an error in downloading, since the neon download function maintains the full folder structure the data, as it is stored on Google Cloud Storage (GCS). If you see the following warning: "UserWarning: Filepaths on Windows are limited to 260 characters. Attempting to download a filepath that is 291 characters long. Set the working or savepath directory to be closer to the root directory or enable long path support in Windows.", you will either need to enable long path support in Windows (a quick online search will show you how to do this) or set the savepath directory so that it is shorter. You can use os.path.abspath to see the full path, if you have specified a relative path. For this example, we will set a short savepath by creating a neon_data directly directly under the home directory as follows:
home_dir = os.path.expanduser('~')
data_dir = os.path.join(home_dir,'neon_data')
# optionally display the full path to the data_dir as follows:
# os.path.abspath(data_dir)
Provisional NEON data are included. To exclude provisional data, use input parameter include_provisional=False.
Continuing will download 2 NEON data files totaling approximately 713.3 MB. Do you want to proceed? (y/n) y
Define some functions that will help us explore the files that were downloaded. You can also look in the File Explorer (Windows) or Finder (Mac) to check out the contents more interactively.
def list_data_subfolders(data_dir):
"""
Recursively finds and lists subfolders within a directory that contain data (files)
and excludes subfolders that only contain other subfolders.
Args:
data_dir: The path to the root directory to search.
Returns:
A list of paths to the subfolders containing data.
"""
data_subfolders = []
for root, dirs, files in os.walk(data_dir):
# Check if the current directory has both subdirectories and files
if dirs and files:
# Iterate through subdirectories to find those that contain files
for dir_name in dirs:
dir_path = os.path.join(root, dir_name)
if any(os.path.isfile(os.path.join(dir_path, f)) for f in os.listdir(dir_path)):
data_subfolders.append(dir_path)
# If the current directory has no subdirectories, but has files, we still want to keep the directory.
elif files:
if root != data_dir: # Avoid adding the root directory itself if it has files
data_subfolders.append(root)
return data_subfolders
def list_data_files(data_dir):
"""
Lists all files within a specified directory and its subdirectories.
Args:
data_dir (str): The path to the data directory to start the search from.
Returns:
list: A list of full paths to all files found.
"""
all_files = []
for root, _, files in os.walk(data_dir):
for file in files:
full_path = os.path.join(root, file)
all_files.append(full_path)
return all_files
We can use these functions to explore the contents of the data that were downloaded. You can also go into File Explorer (Windows) or Finder (Mac) to explore the contents in a more interactive way.
neon_data_subfolders = list_data_subfolders(data_dir)
# display the paths starting with `neon_data` to shorten:
neon_subfolders_short = [f.replace(home_dir,'') for f in neon_data_subfolders]
neon_subfolders_short
Data were downloaded into two nested subfolders. The reflectance data is saved in the path 2023\FullSite\D03\2023_DSNY_7\L3\Spectrometer\Reflectance. This is the standard format where you can expect to find L3 data. Note that before 2023 there is a neon-aop-provisional-products folder. This is because the DSNY data from 2023 is available provisionally. If the data were released, it would be found under neon-aop-products.
Next let's use the list_data_files function to see the actual files that we downloaded. If you included a larger range of points in the Easting and Northing, or used by_file_aop, this list could be much longer.
downloaded_refl_files = list_data_files(data_dir)
# display the files starting with `neon_data` to shorten:
downloaded_refl_files_short = [f.replace(home_dir,'') for f in downloaded_refl_files]
downloaded_refl_files_short
# read the h5 reflectance file (including the full path) to the variable h5_file_name
# h5_file_name = data_url.split('/')[-1]
h5_tiles = [f for f in downloaded_refl_files if f.endswith('.h5')]
h5_tile = h5_tiles[0]
# print(f'h5_tile: {h5_tile}')
Now that we've specified our reflectance tile, we can call aop_h5refl2array to read in the reflectance tile as a python array called refl, the metadata into a dictionary called refl_metadata, and the wavelengths into an array. Let's read it it and then take a quick look at the metadata and the first 5 wavelength values.
# read in the reflectance data using the aop_h5refl2array function, this may also take a bit of time
start_time = time.time()
refl, refl_metadata, wavelengths = neon_hs.aop_h5refl2array(h5_tile,'Reflectance')
print("--- It took %s seconds to read in the data ---" % round((time.time() - start_time),0))
Reading in C:\Users\bhass\neon_data\DP3.30006.002\neon-aop-provisional-products\2023\FullSite\D03\2023_DSNY_7\L3\Spectrometer\Reflectance\NEON_D03_DSNY_DP3_454000_3113000_bidirectional_reflectance.h5
--- It took 23.0 seconds to read in the data ---
# display the reflectance metadata dictionary contents
refl_metadata
We can use the shape method to see the dimensions of the array we read in. Use this method to confirm that the size of the reflectance array makes sense given the hyperspectral data cube, which is 1000 meters x 1000 meters x 426 bands.
refl.shape
(1000, 1000, 426)
Plot a single band
Next we'll use the function plot_aop_refl to plot a single band of the reflectance data. You can use help to understand the required inputs and data types for each of these; only the band and spatial extent are required inputs, the rest are optional inputs. If specified, these optional inputs allow you to set the range color values, specify the axis, add a title, colorbar, colorbar title, and change the colormap (default is to plot in greyscale).
band56 = refl[:,:,55]
neon_hs.plot_aop_refl(band56/refl_metadata['scale_factor'],
refl_metadata['extent'],
colorlimit=(0,0.3),
title='DSNY Tile Band 56',
cmap_title='Reflectance',
colormap='gist_earth')
RGB Plots - Band Stacking
It is often useful to look at several bands together. We can extract and stack three reflectance bands in the red, green, and blue (RGB) spectrums to produce a color image that looks like what we see with our eyes; this is your typical camera image. In the next part of this tutorial, we will learn to stack multiple bands and make a geotif raster from the compilation of these bands. We can see that different combinations of bands allow for different visualizations of the remotely-sensed objects and also conveys useful information about the chemical makeup of the Earth's surface.
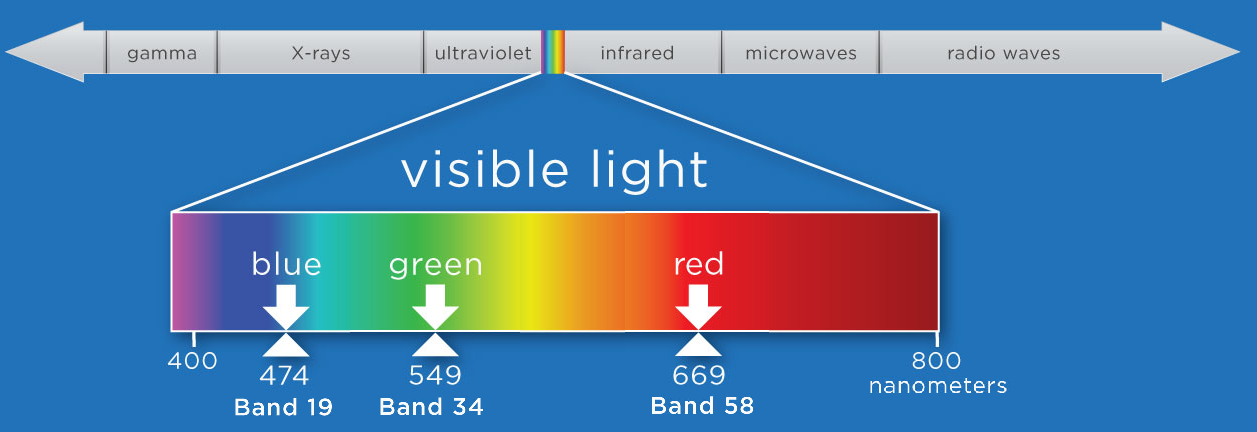
We will select bands that fall within the visible range of the electromagnetic spectrum (400-700 nm) and at specific points that correspond to what we see as red, green, and blue.
NEON Imaging Spectrometer bands and their respective wavelengths. Source: National Ecological Observatory Network (NEON)
For this exercise, we'll first use the function stack_rgb to extract the bands we want to stack. This function uses splicing to extract the nth band from the reflectance array, and then uses the numpy function stack to create a new 3D array (1000 x 1000 x 3) consisting of only the three bands we want.
# pull out the true-color band combinations
rgb_bands = (58,34,19) # set the red, green, and blue bands
# stack the 3-band combinations (rgb and cir) using stack_rgb function
rgb_unscaled = neon_hs.stack_rgb(refl,rgb_bands)
# apply the reflectance scale factor
rgb = rgb_unscaled/refl_metadata['scale_factor']
We can display the red, green, and blue band center wavelengths, whose indices were defined above. To confirm that these band indices correspond to wavelengths in the expected portion of the spectrum, we can print out the wavelength values in nanometers.
Center wavelengths:
Band 58: 669.3 nm
Band 33: 549.1 nm
Band 19: 474.0 nm
Plot an RGB band combination
Next, we can use the function plot_aop_rgb to plot the band stack as follows:
# plot the true color image (rgb)
neon_hs.plot_aop_rgb(rgb,
refl_metadata['extent'],
plot_title='DSNY Reflectance RGB Image')
False Color Image - Color Infrared (CIR)
We can also create an image from bands outside of the visible spectrum. An image containing one or more bands outside of the visible range is called a false-color image. Here we'll use the green and blue bands as before, but we replace the red band with a near-infrared (NIR) band.
For more information about non-visible wavelengths, false color images, and some frequently used false-color band combinations, refer to NASA's Earth Observatory page.
cir_bands = (90,34,19)
print('Band 90 Center Wavelength = %.1f' %(wavelengths[89]),'nm')
print('Band 34 Center Wavelength = %.1f' %(wavelengths[33]),'nm')
print('Band 19 Center Wavelength = %.1f' %(wavelengths[18]),'nm')
cir = neon_hs.stack_rgb(refl,cir_bands)
neon_hs.plot_aop_rgb(cir,
refl_metadata['extent'],
ls_pct=20,
plot_title='DSNY Color Infrared Image')
Band 90 Center Wavelength = 829.6 nm
Band 34 Center Wavelength = 549.1 nm
Band 19 Center Wavelength = 474.0 nm
Recap
Congratulations! You have successfully downloaded a NEON reflectance tile using the neonutilitiesby_tile_aop function. You have also pulled in some pre-defined functions and used these to read in and visualize the reflectance data. You are now well poised to start carrying out more in-depth analysis using the hyperspectral data with Python.
In this tutorial you will learn how to open a .tiff file in Jupyter Notebook and learn about kernels.
The goal of the activity is simply to ensure that you have basic
familiarity with Jupyter Notebooks and that the environment, especially the
gdal package is correctly set up before you pursue more programming tutorials. If you already
are familiar with Jupyter Notebooks using Python, you may be able to complete the
assignment without working through the instructions.
This will be accomplished by:
*Create a new Jupyter kernel
*Download a GEOTIFF file
*Import file onto Jupyter Notebooks
*Check the raster size
Assignment: Open a Tiff File in Jupyter Notebook
Set up Environment
First, we will set up the environment as you would need for each of the live
coding sections of the Data Institute. The following directions are copied over
from the Data Institute Set up Materials.
In your terminal application, navigate to the directory (cd) that where you
want the Jupyter Notebooks to be saved (or where they already exist).
We need to create a new Jupyter kernel for the Python 3.8 conda environment
(py38) that Jupyter Notebooks will use.
In your Command Prompt/Terminal, navigate to the directory (cd) that you
created last week in the GitHub materials. This is where the Jupyter Notebook
will be saved and the easiest way to access existing notebooks.
###Open Jupyter Notebook
Open Jupyter Notebook by typing into a command terminal:
jupyter notebook
Once the notebook is open, check which version of Python you are in.
# Check what version of Python. Should be 3.8.
import sys
sys.version
To ensure that the correct kernel will operate, navigate to Kernel in the menu,
select Kernel/Restart Kernel And Clear All Outputs.
To ensure that the correct kernel will operate, navigate to
Kernel in the menu, select "Restart/Restart & Clear Output".
Source: National Ecological Observatory Network (NEON)
Once downloaded, navigate through the folder to C:NEON-DS-Airborne-Remote-Sensing.zip\NEON-DS-Airborne-Remote-Sensing\SJER\DTM and save this file onto your own personal working directory.
.
###Open GEOTIFF file in Jupyter Notebooks using gdal
The gdal package that occasionally has problems with some versions of Python.
Therefore test out loading it using:
import gdal.
If you have trouble, ensure that 'gdal' is installed on your current environment.
Establish your directory
Place the downloaded dtm file in a repository of your choice (or your current
working directory). Navigate to that directory.
wd= '/your-file-path-here' #Input the directory to where you saved the .tif file
Import the TIFF
Import the NEON GeoTiFF file of the digital terrain model (DTM)
from San Joaquin Experimental Range. Open the file using the gdal.Open command.Determine the size of the raster and (optional) plot the raster.
#Use GDAL to open GEOTIFF file stored in your directory
SJER_DTM = gdal.Open(wd + 'SJER_dtmCrop.tif')>
#Determine the raster size.
SJER_DTM.RasterXSize
Add in both code chunks and text (markdown) chunks to fully explain what is done. If you would like to also plot the file, feel free to do so.
You can set up your notebook in several ways. Here we present the Anaconda Python
distribution method so as to follow the
Data Institute set up instructions.
Browser
First, make sure you have an updated browser on which to run the app. Both Mozilla
Firefox and Google Chrome work well.
Installation
Data Institute participants should have already installed Jupyter Notebooks
through the Anaconda installation during the
Data Institute set up instructions.
If you install Python using pip you can install the Jupyter package with the
following code.
We need to set up the Python environment that we will be working in for the Notebook.
This allows us to have different Python environments for different projects. The
following directions pertain directly to the set up for the 2018 Data Institute
on Remote Sensing with Reproducible Workflows, however, you can adapt them to
the specific Python version and packages you wish to work with.
If you haven't yet created a Python 3.8 environment (released October 2019), you'll need to do
that now. You can use the single line provided below, or refer back to the Python section of the installation instructions,
for more details. To create this Python 3.8 environment, you must first install Anaconda Navigator onto your computer, then open the Anaconda Prompt application (or your terminal) and type the following into the prompt window:
conda create -n p38 python=3.8 anaconda
And activate the Python 3.8 environment:
On Mac:
source activate p38
On Windows:
activate p38
In the terminal application, navigate to the directory (cd) where you
want the Jupyter Notebooks to be saved (or where they already exist).
Once here, we want to create a new Jupyter kernel for the Python 3.8 conda environment
(p38) that we'll be using with Jupyter Notebooks.
With the p38 environment activated, in your Command Prompt/Terminal, type:
This command tells Python to create a new ipy (aka Jupyter Notebook) kernel using
the Python environment we set up and called "p38". Then we tell it to use the display
name for this new kernel as "Python 3.8 NEON-RSDI". You will use this
name to identify the specific kernel you want to work with in the Notebook space,
so name it descriptively, especially if you think you'll be using several different
kernels.
Using Jupyter Notebooks
Launching the Application
To launch the application either launch it from the Anaconda Navigator or by
typing jupyter notebook into your terminal or command window.
If everything launched correctly, you should be able to see a screen which looks
something like this. Note that the home directory will be whatever directory you
have navigated to in your terminal before launching Jupyter Notebooks.
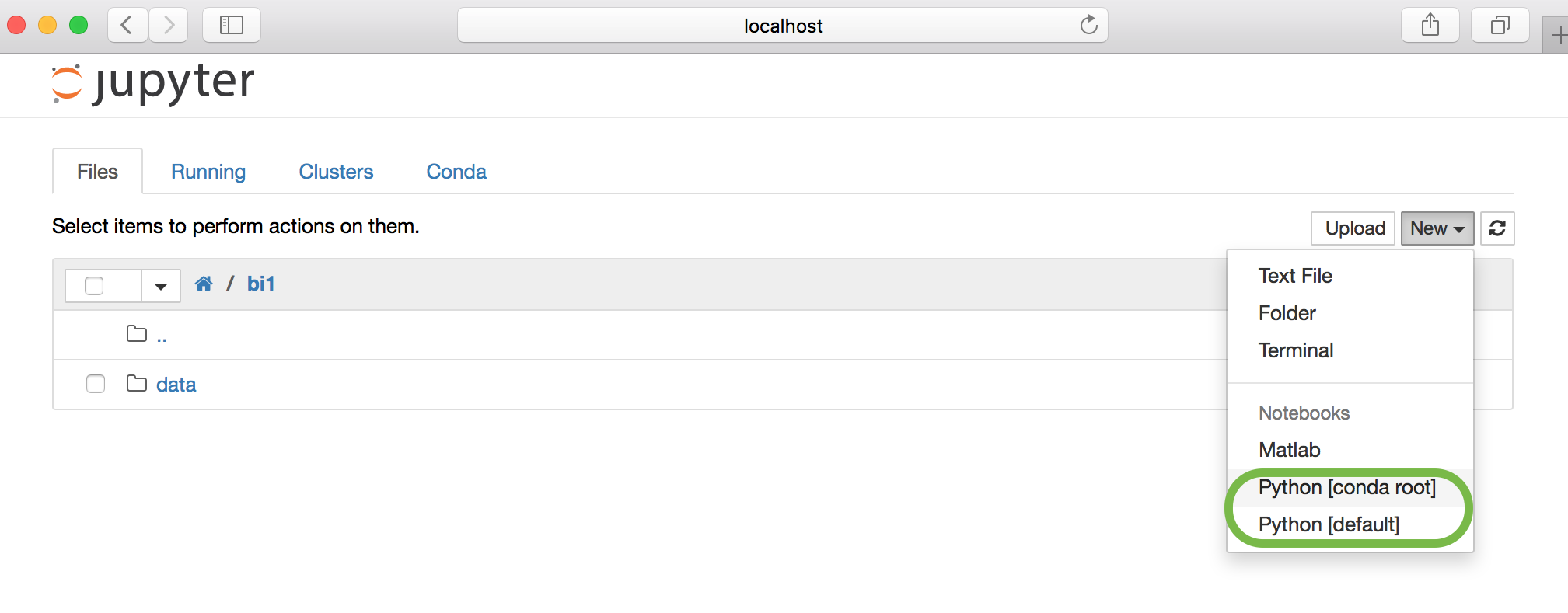
To start a new Python notebook, click on the right-hand side of the application
window and select New (the expanded menu is shown in the screen shot above).
This will give you several options for new notebook kernels depending on what
is installed on your computer. In the above screenshot, there are two available
Python kernels and one Matlab kernel. When starting a notebook, you should choose
Python 3 if it is available or conda(root) .
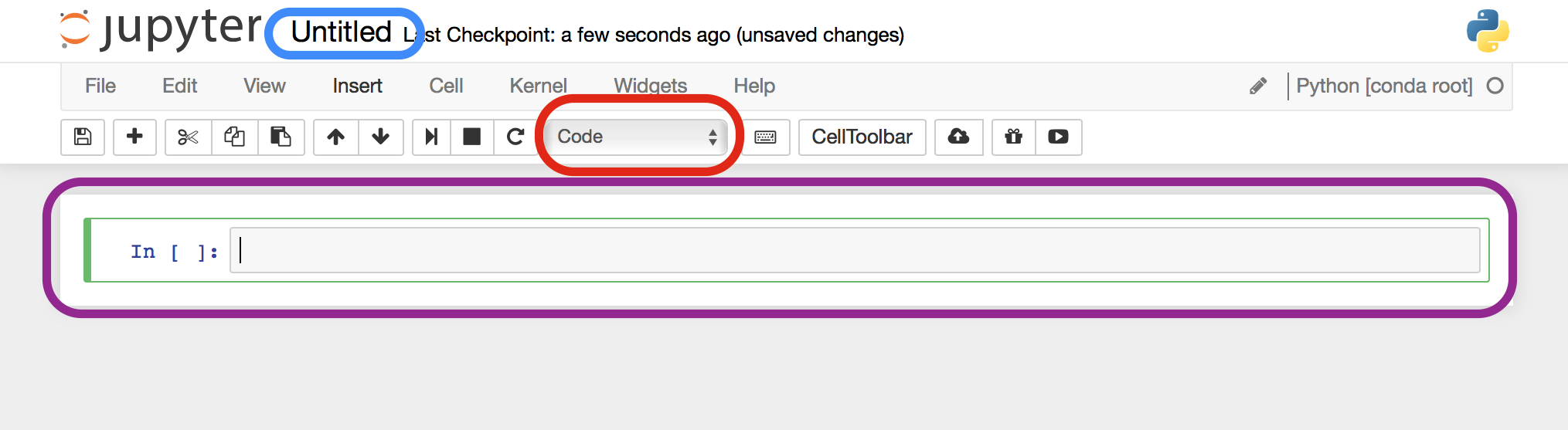
Once you start a new notebook, you will be brought to the following screen.
There are many available buttons for you to click. The three most important
components of the notebook are highlighted in colored boxes.
In blue is the name of the notebook. By clicking this, you can rename
the notebook.
In red is the cell formatting assignment. By default, it is registered
as code, but it can also be set to markdown as described later.
In purple, is the code cell. In this cell, you can type an execute
Python code as well as text that will be formatted in a nicely readable format.
Selecting a Kernel
A kernel is a server that enables you to run commands within Jupyter Notebook. It is visible via a prompt window that logs all your actions in the notebook, making it helpful to refer to when encountering errors. You'll be prompted to select a kernel when you open a new notebook, however, if
you are opening an existing notebook you will want to ensure that you are
using the correct kernel. The commands for selecting and changing kernels are in
the Kernel menu.
When you select or switch a kernel, you may want to use the navigate to Kernel in the menu,
select Restart/ClearOutlook. The Restart/ClearOutlook option ensures that
the correct kernel will operate.
You can always check what version of Python you are running by typing the following
into a code cell.
# Check what version of Python. Should be 3.5.
import sys
sys.version
All code you write in the notebook will be in the code cell. You can write
single lines, to entire loops, to complete functions. As an example, we can
write and evaluate a print statement in a code cell, as is shown below.
If you would like to write several lines of code, hit Enter to continue entering code into another line. To execute the code, we can simply hit Shift + Enter while our cursor is in the
code cell.
# This is a comment and is not read by Python
print('Hello! This is the print function. Python will print this line below')
Hello! This is the print function. Python will print this line below
We can also write a 'for' loop as an example of executing multiple lines of code at once.
# Write a basic for loop. In this case a range of numbers 0-4.
for i in range(5):
# Multiply the value of i by two and assign it to a variable.
temp_variable = 2 * i
# Print the value of the temp variable.
print(temp_variable)
0
2
4
6
8
There are two other useful keyboard shortcuts for running code:
Alt + Enter runs the current cell and inserts a new one below
Ctrl + Enter run the current cell and enters command mode.
**Data Tip:** Code cells can be executed in any
order. This means that you can overwrite your current variables by running
things out of order. When coding in notebooks, be cautious of the order in
which you run cells.
If you would like more details on running code in Jupyter Notebooks, please go through the
following short tutorial by
Running Code
by contributors to the Jupyter project. This tutorial touches on start and stopping
the kernel and using multiple kernels (e.g., Python and R) in one notebook.
Arguably the most useful component of the Jupyter Notebook is the ability to
interweave code and explanatory text into a single, coherent document. Through
out the Data Institute (and one's everyday workflow), we encourage all code and
plots should be accompanied with explanatory text.
Each cell in a notebook can exist either as a code cell or as a text-formatting
cell called a markdown cell. Markdown is a mark-up language that very easily
converts to other type-setting formats such as HTML and PDF.
Whenever you make a new cell, its default assignment will be a code cell.
This means when you want to write text, you will need to specifically change it
to a markdown cell. You can do this by clicking on the drop-down menu that reads code'
(highlighted in red in the second figure of this page) and selecting 'Markdown'.
You can then type in the code cell and all Python syntax highlighting will be
removed.
Jupyter notebooks are set up to autosave your work every 15 or so minutes.
However, you should not rely on the autosave feature! Save your work frequently
by clicking on the floppy disk icon located in the upper left-hand corner of the
toolbar.
To navigate back to the root of your Jupyter notebook server, you can click on
the Jupyter logo at any time.
To quit your Jupyter notebook, you can simply close the browser window and the
Jupyter notebook server running in your terminal.
Converting to HTML and PDF
In addition to sharing notebooks in the.ipynb format, it may useful to convert
these notebooks to highly-portable formats such as HTML and PDF.
To convert, you can either use the dropdown menu option
File -> download as -> ...
or via the command line by using the following lines:
jupyter nbconvert --to pdf notebook_name.ipynb
Where "notebook_name.ipynb" matches the name of the notebook you want to convert. Prior to
converting the notebook, you must be in the same working directory as your notebook or use
the correct file path from your current working directory.
Converting to PDF requires both Pandoc and LaTeX to be installed. You can find
out more in the ReadTheDoc for nbconvert.
If you prefer to convert to a different format, like HTML, you simply change the
file type.
jupyter nbconvert --to html notebook_name.ipynb
Read more on what formats you can convert to and more about the
nbconvert package .
“The Jupyter Notebook is an open-source web application that allows you to
create and share documents that contain live code, equations, visualizations and
explanatory text. Uses include: data cleaning and transformation, numerical
simulation, statistical modeling, machine learning and much more."
-- Jupyter Notebook documentation.
We use markdown syntax in Notebook documents to document workflows and
to share data processing, analysis and visualization outputs. We can also use it
to create documents that combine code in your language of choice, output and text.
The Jupyter Notebooks grew out of iPython. Jupyter is a close acronym meaning
Julia, Python, and R, which were the first languages outside Python that the Jupyter
application was designed for. Jupyter Notebooks now supports over
40 coding languages. You may still find some references to iPython in materials
related to Jupyter Notebooks. This series will focus on using Jupyter Notebooks with Python,
but the information presented can apply to other languages as well.
The Jupyter Notebooks application is a browser-based application. Therefore, you
need an updated browser (the Jupyter programmers recommend Mozilla Firefox or Google
Chrome, but not Microsoft Explorer). When installed on your computer, you can
always access the app even without internet access. You can also use Jupyter
installed on a remote server. For example, Jupyter runs a
training (temporary) server based version.
Why Jupyter Notebooks?
There are many advantages to using Jupyter Notebooks in your work:
Human readable syntax.
Simple syntax - it can be learned quickly.
All components of your work are clearly documented. You don't have to remember
what steps, assumptions, tests were used.
You can easily extend or refine analyses by modifying existing or adding new
code blocks.
Analysis results can be disseminated in various formats including HTML, PDF,
slideshows and more.
Code and data can be shared with a colleague to replicate the workflow.
Explore Examples of Notebooks
Before we jump into how to work with notebooks, check out a few shared notebooks.
As you look at these different notebooks, what aspects of the layout do you like,
what don't you like? Is there a place in your current workflow that these
notebooks would be useful?
This page outlines the tools and resources that you will need to install Git, Bash and Python applications onto your computer as the first step of our Python skills tutorial series.
Checklist
Detailed directions to accomplish each objective are below.
Adjusting your PATH environment:
Select "Use Git from the Windows Command Prompt" and click on "Next".
If you forgot to do this programs that you need for the event will not work properly.
If this happens rerun the installer and select the appropriate option.
Configuring the line ending conversions: Click on "Next".
Keep "Checkout Windows-style, commit Unix-style line endings" selected.
Configuring the terminal emulator to use with Git Bash:
Select "Use Windows' default console window" and click on "Next".
Configuring experimental performance tweaks: Click on "Next".
Completing the Git Setup Wizard: Click on "Finish".
This will provide you with both Git and Bash in the Git Bash program.
Install Bash for Mac OS X
The default shell in all versions of Mac OS X is bash, so no
need to install anything. You access bash from the Terminal
(found in
/Applications/Utilities). You may want to keep
Terminal in your dock for this workshop.
Install Bash for Linux
The default shell is usually Bash, but if your
machine is set up differently you can run it by opening a
terminal and typing bash. There is no need to
install anything.
Git Setup
Git is a version control system that lets you track who made changes to what
when and has options for easily updating a shared or public version of your code
on GitHub. You will need a
supported
web browser (current versions of Chrome, Firefox or Safari, or Internet Explorer
version 9 or above).
Git installation instructions borrowed and modified from
Software Carpentry.
Git for Windows
Git should be installed on your computer as part of your Bash install.
Install Git on Macs by downloading and running the most recent installer for
"mavericks" if you are using OS X 10.9 and higher -or- if using an
earlier OS X, choose the most recent "snow leopard" installer, from
this list.
After installing Git, there will not be anything in your
/Applications folder, as Git is a command line program.
**Data Tip:**
If you are running Mac OSX El Capitan, you might encounter errors when trying to
use git. Make sure you update XCODE.
Read more - a Stack Overflow Issue.
Git on Linux
If Git is not already available on your machine you can try to
install it via your distro's package manager. For Debian/Ubuntu run
sudo apt-get install git and for Fedora run
sudo yum install git.
Setting Up Python
Python is a popular language for
scientific computing and data science, as well as being a great for
general-purpose programming. Installing all of the scientific packages
individually can be a bit difficult, so we recommend using an all-in-one
installer, like Anaconda.
Regardless of how you choose to install it, **please make sure your environment
is set up with Python version 3.7 (at the time of writing, the gdal package did not work
with the newest Python version 3.6). Python 2.x is quite different from Python 3.x
so you do need to install 3.x and set up with the 3.7 environment.
We will teach using Python in the
Jupyter Notebook environment,
a programming environment that runs in a web browser. For this to work you will
need a reasonably up-to-date browser. The current versions of the Chrome, Safari
and Firefox browsers are all
supported
(some older browsers, including Internet Explorer version 9 and below, are not).
You can choose to not use notebooks in the course, however, we do
recommend you download and install the library so that you can explore this tool.
Windows
Download and install
Anaconda.
Download the default Python 3 installer (3.7). Use all of the defaults for
installation except make sure to check Make Anaconda the default Python.
Mac OS X
Download and install
Anaconda.
Download the Python 3.x installer, choosing either the graphical installer or the
command-line installer (3.7). For the graphical installer, use all of the defaults for
installation. For the command-line installer open Terminal, navigate to the
directory with the download then enter:
bash Anaconda3-2020.11-MacOSX-x86_64.sh (or whatever you file name is)
Linux
Download and install
Anaconda.
Download the installer that matches your operating system and save it in your
home folder. Download the default Python 3 installer.
Open a terminal window and navigate to your downloads folder. Type
bash Anaconda3-2020.11-Linux-ppc64le.sh
and then press tab. The name of the file you just downloaded should appear.
Press enter. You will follow the text-only prompts. When there is a colon at
the bottom of the screen press the down arrow to move down through the text.
Type yes and press enter to approve the license. Press enter to
approve the default location for the files. Type yes and press
enter to prepend Anaconda to your PATH (this makes the Anaconda
distribution the default Python).
Install Python packages
We need to install several packages to the Python environment to be able to work
with the remote sensing data
gdal
h5py
If you are new to working with command line you may wish to complete the next
setup instructions which provides and intro to command line (bash) prior to
completing these package installation instructions.
Windows
Create a new Python 3.7 environment by opening Windows Command Prompt and typing
conda create –n py37 python=3.7 anaconda
When prompted, activate the py37 environment in Command Prompt by typing
activate py37
You should see (py37) at the beginning of the command line. You can also test
that you are using the correct version by typing python --version.
Install Python package(s):
gdal: conda install gdal
h5py: conda install h5py
Note: You may need to only install gdal as the others may be included in the
default.
Mac OS X
Create a new Python 3.7 environment by opening Terminal and typing
conda create –n py37 python=3.7 anaconda
This may take a minute or two.
When prompted, activate the py37 environment in Command Prompt by typing
source activate py37
You should see (py37) at the beginning of the command line. You can also test
that you are using the correct version by typing python --version.
Install Python package(s):
gdal: conda install gdal
h5py: conda install h5py
Linux
Open default terminal application
(on Ubuntu that will be gnome-terminal).
Launch Python.
Install Python package(s):
gdal: conda install gdal
h5py: conda install h5py
Set up Jupyter Notebook Environment
In your terminal application, navigate to the directory (cd) that where you
want the Jupyter Notebooks to be saved (or where they already exist).
Open Jupyter Notebook with
jupyter notebook
Once the notebook is open, check which version of Python you are in by using the
prompts
# check what version of Python you are using.
import sys
sys.version
You should now be able to work in the notebook.
The gdal package that occasionally has problems with some versions of Python.
Therefore test out loading it using
During the NEON Data Institute, you will share the code that you create daily
with everyone on the NEONScience/DI-NEON-participants repo.
Through this week’s tutorials, you have learned the basic skills needed to
successfully share your work at the Institute including how to:
Create your own GitHub user account,
Set up Git on your computer (please do this on the computer you will be
bringing to the Institute), and
Create a Markdown file with a biography of yourself and the project you are
interested in working on at the Institute. This biography was shared with the
group via the Data Institute’s GitHub repo.
Checklist for this week’s Assignment:
You should have completed the following after Pre-institute week 2:
Fork & clone the NEON-DataSkills/DI-NEON-participants repo.
Create a .md file in the participants/2018-RemoteSensing/pre-institute2-git directory of the
repo. Name the document LastName-FirstName.md.
Write a biography that introduces yourself to the other participants. Please
provide basic information including:
name,
domain of interest,
one goal for the course,
an updated version of your Capstone Project idea,
and the list of data (NEON or other) to support the project that you created
during last week’s materials.
Push the document from your local computer to your GithHub repo.
Created a Pull Request to merge this document back into the
NEON-DataSkills/DI-NEON-participants repo.
NOTE: The Data Institute repository is a public repository, so all members of
the Institute, as well as anyone in the general public who stumbles on the repo,
can see the information. If you prefer not to share this information publicly,
please submit the same document but use a pseudonym (cartoon character names
would work well) and email us with the pseudonym so that we can connect the
submitted document to you.
Have questions? No problem. Leave your question in the comment box below.
It's likely some of your colleagues have the same question, too! And also
likely someone else knows the answer.
We've forked (made an individual copy of) the NEONScience/DI-NEON-participants repo to
our github.com account.
We've cloned the forked repo - making a copy of it on our local computers.
We've added files and content to our local copy of the repo and committed
the changes.
We've pushed those changes back up to our forked repo on github.com.
Once you've forked and cloned a repo, you are all setup to work on your project.
You won't need to repeat those steps.
When you want to add materials from your repo to the central repo,
you will use a Pull Request. LEFT: Initial workflow after you fork and clone
a repo. RIGHT: Typical workflow once a repo is established (see Git 07 tutorial). Both use pull
requests.
Source: National Ecological Observatory Network (NEON)
In this tutorial, we will learn how to transfer changes from our forked
repo in our github.com account to the central NEON Data Institute repo. Adding
information from your forked repo to the central repo in GitHub is done using a
pull request.
LEFT: To sync changes made and committed to the repo from your
local computer, you will first push the changes from your
local repo to your fork on github.com. RIGHT: Then, you will submit a
Pull Request to update the central repository.
Source: National Ecological Observatory Network (NEON)
**Data Tip:**
A pull request to another repo is similar to a "push". However it allows
for a few things:
It allows you to contribute to another repo without needing administrative
privileges to make changes to the repo.
It allows others to review your changes and suggest corrections, additions,
edits, etc.
It allows repo administrators control over what gets added to
their project repo.
The ability to suggest changes to ANY (public) repo, without needing administrative
privileges is a powerful feature of GitHub. In our case, you do not have privileges
to actually make changes to the DI-NEON-participants repo. However you can
make as many changes
as you want in your fork, and then suggest that NEON add those changes to their
repo, using a pull request. Pretty cool!
Adding to a Repo Using Pull Requests
Pull Requests in GitHub
Step 1 - Start Pull Request
To start a pull request, click the pull request button on the main repo page.
Location of the Pull Request button on a fork of the NEON
Data Institute participants repo (Note, screenshot shows a previous version of
the repo, however, the button is in the same location). Source: National Ecological Observatory
Network (NEON)
Alternatively, you can click the Pull requests tab, then on this new page click the
"New pull request" button.
Step 2 - Choose Repos to Update
Select your fork to compare with NEON central repo. When you begin a pull
request, the head and base will auto-populate as follows:
base fork: NEONScience/DI-NEON-participants
head fork: YOUR-USER-NAME/DI-NEON-participants
The above pull request configuration tells Git to sync (or update) the NEON repo
with contents from your repo.
Head vs Base
Base: the repo that will be updated, the changes will be added to this repo.
Head: the repo from which the changes come.
One way to remember this is that the “head” is always ahead of the base, so
we must add from the head to the base.
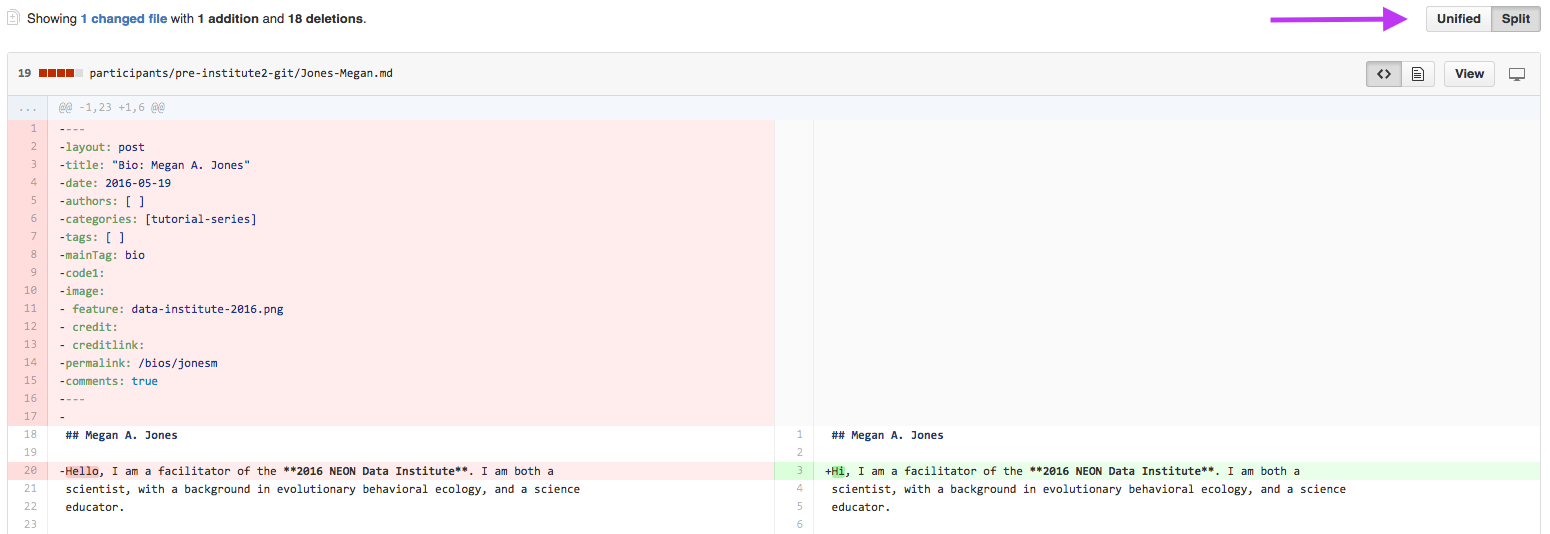
Step 3 - Verify Changes
When you compare two repos in a pull request page, git will provide an overview
of the differences (diffs) between the files (if the file is a binary file, like
code. Non-binary files will just show up as a fully new file if it had any changes).
Look over the changes and make sure nothing looks surprising.
In this split view, shows the differences between the older (LEFT)
and newer (RIGHT) document. Deletions are highlighted in red and additions
are highlighted in green.
Pull request diffs view can be changed between unified and split (arrow).
Source: National Ecological Observatory Network (NEON)
Step 4 - Create Pull Request
Click the green Create Pull Request button to create the pull request.
Step 5 - Title Pull Request
Give your pull request a title and write a brief description of your changes.
When you’re done with your message, click Create pull request!
All pull requests titles should be concise and descriptive of
the content in the pull request. More detailed notes can be left in the comments
box.
Source: National Ecological Observatory Network (NEON)
Check out the repo name up at the top (in your repo and in screenshot above)
When creating the pull request you will be automatically transferred to the base
repo. Since the central repo was the base, github will automatically transfer
you to the central repo landing page.
Step 6 - Merge Pull Request
In this final step, it’s time to merge your changes in the
NEONScience/DI-NEON-participants repo.
NOTE 1: You are only able to merge a pull request in a repo that you have
permissions to!
NOTE 2: When collaborating, it is generally poor form to merge your own Pull Request,
better to tag (@username) a collaborator in the comments so they know you want
them to look at it. They can then review and, if acceptable, merge it.
To merge, your (or someone else's PR click the green "Merge Pull Request"
button to "accept" or merge the updated commits in the central repo into your
repo. Then click Confirm Merge.
We now synced our forked repo with the central NEON Repo. The next step in working
in a GitHub workflow is to transfer any changes in the central repository into
your local repo so you can work with them.
Data Institute Activity: Submit Pull Request for Week 2 Assignment
Submit a pull request containing the .md file that you created in this
tutorial-series series. Before you submit your PR, review the
Week 2 Assignment page.
To ensure you have all of the required elements in your .md file.
To submit your PR:
Repeat the pull request steps above, with the base and head switched. Your base
will be the NEON central repo and your HEAD will be YOUR forked repo:
base fork: NEONScience/DI-NEON-participants
head fork: YOUR-USER-NAME/DI-NEON-participants
When you get to Step 6 - Merge Pull Request (PR), are you able to merge the PR?
Finally, go to the NEON Central Repo page in github.com. Look for the Pull Requests
link at the top of the page. How many Pull Requests are there?
Click on the link - do you see your Pull Request?
You can only merge a PR if you have permissions in the base repo that you are
adding to. At this point you don’t have contributor permissions to the NEON repo.
Instead someone who is a contributor on the repository will need to review and
accept the request.
After completing the pull request to upload your bio markdown file, be sure
to continue on to Git 07: Updating Your Repo by Setting Up a Remote
to learn how to update your local fork and really begin
the cycle of working with Git & GitHub in a collaborative manner.
Workflow Summary
Add updates to Central Repo with Pull Request
On github.com
Button: Create New Pull Request
Set base: central Institute repo, set head: your Fork
Make sure changes are what you want to sync
Button: Create Pull Request
Add Pull Request title & comments
Button: Create Pull Request
Button: Merge Pull Request - if working collaboratively, poor style to merge
your own PR, and you only can if you have contributor permissions
Have questions? No problem. Leave your question in the comment box below.
It's likely some of your colleagues have the same question, too! And also
likely someone else knows the answer.
This tutorial reviews how to add and commit changes to a Git repo.
## Learning Objectives
At the end of this activity, you will be able to:
Add new files or changes to existing files to your repo.
Document changes using the commit command with a message describing what has changed.
Describe the difference between git add and git commit.
Sync changes to your local repository with the repostored on GitHub.com.
Use and interpret the output from the following commands:
git status
git add
git commit
git push
Additional Resources
Diagram of Git Commands
-- this diagram includes more commands than we will
learn in this series but includes all that we use for our standard workflow.
Information on branches in Git
-- we do not focus on the use of branches in Git or GitHub, however, if you want
more information on this structure, this Git documentation may be of use.
In the previous lesson, we created a markdown (.md) file in our forked version
of the DI-NEON-participants central repo. In order for Git to recognize this
new file and track it, we need to:
Add the file to the repository using git add.
Commit the file to the repository as a set of changes to the repo (in this case, a new
document with some text content) using git commit.
Push or sync the changes we've made locally with our forked repo hosted on github.com
using git push.
After a Git repo has been cloned locally, you can now work on
any file in the repo. You use git pull to pull changes in your
fork on github.com down to your computer to ensure both repos are in sync.
Edits to a file on your computer are not recognized by Git until you
"add" and "commit" them as tracked changes in your repo.
Source: National Ecological Observatory Network (NEON)
Check Repository Status -- git status
Let's first run through some basic commands to get going with Git at the command
line. First, it's always a good idea to check the status of your repository.
This allows us to see any changes that have occurred.
Do the following:
Open bash if it's not already open.
Navigate to the DI-NEON-participants repository in bash.
Type: git status.
The commands that you type into bash should look like the code below:
# Change directory
# The directory containing the git repo that you wish to work in.
$ cd ~/Documents/GitHub/neon-data-repository-2016
# check the status of the repo
$ git status
Output:
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
Untracked files:
(use "git add <file>..." to include in what will be committed)
_posts/ExampleFile.md
Let's make sense of the output of the git status command.
On branch master: This tells us that we are on the master branch of the
repo. Don't worry too much about branches just yet. We will work on the master branch
throughout the Data Institute.
Changes not staged for commit: This lists any file(s) that is/are currently
being tracked by Git but have new changes that need to be added for Git to track.
Untracked file: These are all new files that have never been added to or
tracked by Git.
Use git status anytime to view any untracked changes that have occurred, what
is being tracked and what is not currently being tracked.
Add a File - git add
Next, let's add the Markdown file containing our bio and short project summary
using the command git add FileName.md. Replace FileName.md with the name
of your markdown file.
# add a file, so that changes are tracked
$ git add ExampleBioFile.md
# check status again
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: _posts/ExampleBioFile.md
Understand the output:
Changes to be committed: This lists the new files or files with changes that
have been added to the Git tracking system but need to be committed as actual changes
in the git repository history.
**Data Tip:** If you want to delete a file from your
repo, you can do so using `git rm file-name-here.fileExtension`. If you delete
a file in the finder (Mac) or Windows Explorer, you will still have to use
`git add` at the command line to tell git that a file has been removed from the
repo, and to track that "change".
Commit Changes - git commit
When we add a file in the command line, we are telling Git to recognize that
a change has occurred. The file moves to a "staging" area where Git
recognizes a change has happened but the change has not yet been formally
documented. When we want to permanently document those changes, we
commit the change. A single commit will work for all files that are currently
added to and in the Git staging area (anything in green when we check the status).
Commit Messages
When we commit a change to the Git version control system, we need to add a commit
message. This message describes the changes made in the commit. This commit
message is helpful to us when we review commit history to see what has changed
over time and when those changes occurred. Be sure that your message
covers the change.
**Data Tip:** It is good practice to keep commit messages to fewer than 50 characters.
# commit changes with message
$ git commit -m “new example file for demonstration”
[master e3cd622] new example file for demonstration
1 file changed, 56 insertions(+), 4 deletions(-)
create mode 100644 _posts/ExampleFile.md
Understand the output:
Each commit will look slightly different but the important parts include:
master xxxxxxx this is the unique identifier for this set of changes or
this commit. You will always be able to track this specific commit (this specific
set of changes) using this identifier.
_ file change, _ insertions(+), _ deletion (-) this tells us how many files
have changed and the number of type of changes made to the files including:
insertions, and deletions.
**Data Tip:**
It is a good idea to use `git status` frequently as you are working with Git
in the shell. This allows you to keep track of change that you've made and what
Git is actually tracking.
Why Add, then Commit?
You can think of Git as taking snapshots of changes over the
life of a project. git add specifies what will go in a snapshot (putting things
in the staging area), and git commit then actually takes the snapshot and
makes a permanent record of it (as a commit). Image and caption source:
Software Carpentry
To understand what is going on with git add and git commit it is important
to understand that Git has a staging area that we add items to with git add.
Changes are not actually documented and permanently tracked until we commit them. This allows
us to commit specific groups of files at the same time if we wish. For instance,
we may decide to add and commit all R scripts together. And Markdown files in another,
separate commit.
Transfer Changes (Commits) from a Local Repo to a GitHub Repo - git push
When we are done editing our files and have committed the changes locally, we
are ready to transfer or sync these changes to our forked repo on github.com. To
do this we need to push our changes from the local Git version control to the
remote GitHub repo.
To sync local changes with github.com, we can do the following:
Check the status of our repo using git status. Are all of the changes added
and committed to the repo?
Use git push origin master. origin tells Git to push the files to the
originating repo which in this case - is our fork on github.com which we originally
cloned to our local computer. master is the repo branch that you are
currently working on.
**Data Tip:**
Note about branches in Git: We won't cover branches in these tutorials, however,
a Git repo can consist of many branches. You can think about a branch, like
an additional copy of a repo where you can work on changes and updates.
Let's push the changes that we made to the local version of our Git repo to our
fork, in our github.com account.
# check the repo status
$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
# transfer committed changes to the forked repo
git push origin master
Counting objects: 1, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (6/6), 1.51 KiB | 0 bytes/s, done.
Total 6 (delta 4), reused 0 (delta 0)
To https://github.com/mjones01/DI-NEON-participants.git
5022aca..e3cd622 master -> master
NOTE: You may be asked for your username and password! This is your github.com
username and password.
Understand the output:
Pay attention to the repository URL - the "origin" is the
repository that the commit was pushed to, here https://github.com/mjones01/DI-NEON-participants.git.
Note that because this repo is a fork, your URL will have your GitHub username
in it instead of "mjones01".
**Data Tip:** You can use Git and connect to GitHub
directly in the RStudio interface. If interested, read
this R-bloggers How-To.
View Commits in GitHub
Let’s view our recent commit in our forked repo on GitHub.
Go to github.com and navigate to your forked Data Institute repo - DI-NEON-participants.
Click on the commits link at the top of the page.
Look at the commits - do you see your recent commit message that you typed
into bash on your computer?
Next, click on the <>CODE link which is ABOVE the commits link in github.
Is the Markdown file that you added and committed locally at the command
line on your computer, there in the same directory (participants/pre-institute2-git) that you saved it on your
laptop?
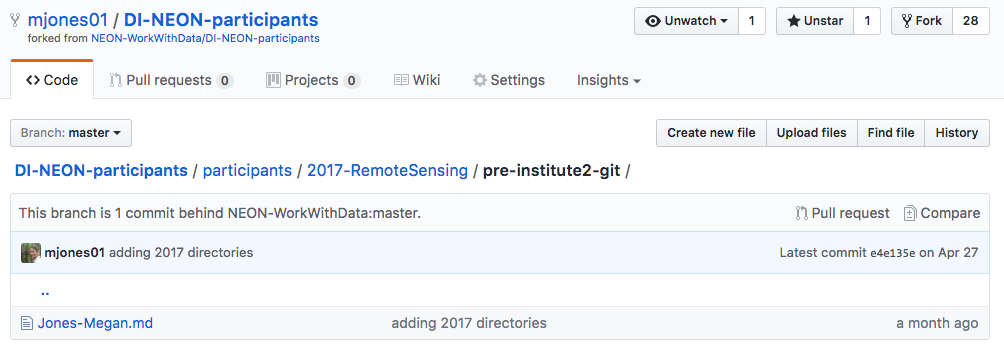
An example .md file located within the
participants/2017-RemoteSensing/pre-institute2-git of a Data Institute repo fork.
Source: National Ecological Observatory Network (NEON)
Is Your File in the NEON Central Repo Yet?
Next, do the following:
Navigate to the NEON central
NEONScience/DI-NEON-participants
repo. (The easiest method to do this is to click the link at the top of the page under your repo name).
Look for your file in the same directory. Is your new file there? If not, why?
Remember the structure of our workflow.
We’ve added changes from our local
repo on our computer and pushed them to our fork on github.com. But this fork
is in our individual user account, not NEONS. This fork is
separate from the central repo. Changes to a fork in our github.com account
do not automatically transfer to the central repo. We need to sync them! We will
learn how to sync these two
repos in the next tutorial
Git 06: Syncing GitHub Repos with Pull Requests .
Summary Workflow - Committing Changes
On your computer, within your local copy of the Git repo:
Create a new markdown file and edit it in your favorite text editor.
On your computer, in shell (at the command line):
git status
git add FileName
git status - make sure everything is added and ready for commit
`git commit -m “messageHere”
git push origin master
On the github.com website:
Check to make sure commit is added.
Check to see if the file that you added is visible online in your Git repo.
Have questions? No problem. Leave your question in the comment box below.
It's likely some of your colleagues have the same question, too! And also
likely someone else knows the answer.