This tutorial covers how to read in a NEON lidar Canopy Height Model (CHM) geotiff file into a Python rasterio object, shows some basic information about the raster data, and then ends with classifying the CHM into height bins.
Objectives
After completing this tutorial, you will be able to:
User rasterio to read in a NEON lidar raster geotiff file
Plot a raster tile and histogram of the data values
Create a classified raster object using thresholds
Install Python Packages
gdal
rasterio
requests
Download Data
For this lesson, we will read in a Canopy Height Model data collected at NEON's Lower Teakettle (TEAK) site in California. This data is downloaded in the first part of the tutorial, using the Python requests package.
In this tutorial, we will work with the NEON AOP L3 LiDAR ecoysystem structure (Canopy Height Model) data product. For more information about NEON data products and the CHM product DP3.30015.001, see the Ecosystem structure data product page on NEON's Data Portal.
First, let's import the required packages and set our plot display to be in-line:
import os
import copy
import requests
import numpy as np
import rasterio as rio
from rasterio.plot import show, show_hist
import matplotlib.pyplot as plt
%matplotlib inline
Next, let's download a file. For this tutorial, we will use the requests package to download a raster file from the public link where the data is stored. For simplicity, we will show how to download to a data folder in the working directory. You can move the data to a different folder, but be sure to update the path to your data accordingly.
# function to download data stored on the internet in a public url to a local file
def download_url(url,download_dir):
if not os.path.isdir(download_dir):
os.makedirs(download_dir)
filename = url.split('/')[-1]
r = requests.get(url, allow_redirects=True)
file_object = open(os.path.join(download_dir,filename),'wb')
file_object.write(r.content)
# public url where the CHM tile is stored
chm_url = "https://storage.googleapis.com/neon-aop-products/2021/FullSite/D17/2021_TEAK_5/L3/DiscreteLidar/CanopyHeightModelGtif/NEON_D17_TEAK_DP3_320000_4092000_CHM.tif"
# download the CHM tile
download_url(chm_url,'.\data')
# display the contents in the ./data folder to confirm the download completed
os.listdir('./data')
Open a GeoTIFF with rasterio
Let's look at the TEAK Canopy Height Model (CHM) to start. We can open and read this in Python using the rasterio.open function:
# read the chm file (including the full path) to the variable chm_dataset
chm_name = chm_url.split('/')[-1]
chm_file = os.path.join(".\data",chm_name)
chm_dataset = rio.open(chm_file)
Now we can look at a few properties of this dataset to start to get a feel for the rasterio object:
print('chm_dataset:\n',chm_dataset)
print('\nshape:\n',chm_dataset.shape)
print('\nno data value:\n',chm_dataset.nodata)
print('\nspatial extent:\n',chm_dataset.bounds)
print('\ncoordinate information (crs):\n',chm_dataset.crs)
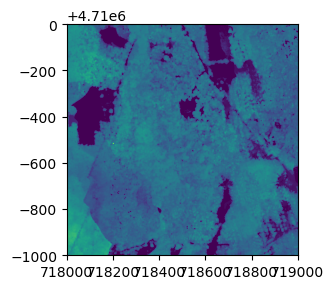
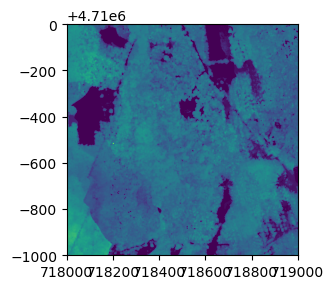
Plot the Canopy Height Map and Histogram
We can use rasterio's built-in functions show and show_hist to plot and visualize the CHM tile. It is often useful to plot a histogram of the geotiff data in order to get a sense of the range and distribution of values.
On your own, adjust the number of bins, and range of the y-axis to get a better sense of the distribution of the canopy height values. We can see that a large portion of the values are zero. These correspond to bare ground. Let's look at a histogram and plot the data without these zero values. To do this, we'll remove all values > 1 m. Due to the vertical range resolution of the lidar sensor, data collected with the Optech Gemini sensor can only resolve the ground to within 2 m, so anything below that height will be rounded down to zero. Our newer sensors (Riegl Q780 and Optech Galaxy) have a higher resolution, so the ground can be resolved to within ~0.7 m.
From the histogram we can see that the majority of the trees are < 60m. But the taller trees are less common in this tile.
Threshold Based Raster Classification
Next, we will create a classified raster object. To do this, we will use the numpy.where function to create a new raster based off boolean classifications. Let's classify the canopy height into five groups:
Class 1: CHM = 0 m
Class 2: 0m < CHM <= 15m
Class 3: 10m < CHM <= 30m
Class 4: 20m < CHM <= 45m
Class 5: CHM > 50m
We can use np.where to find the indices where the specified criteria is met.
When we look at this variable, we can see that it is now populated with values between 1-5:
chm_reclass
Lastly we can use matplotlib to display this re-classified CHM. We will define our own colormap to plot these discrete classifications, and create a custom legend to label the classes. First, to include the spatial information in the plot, create a new variable called ext that pulls from the rasterio "bounds" field to create the extent in the expected format for plotting.
In this tutorial, we will learn how to extract and plot a spectral profile from a single pixel of a reflectance band in a NEON hyperspectral HDF5 file.
After completing this tutorial, you will be able to:
Plot the spectral signature of a single pixel
Remove bad band windows from a spectra
Use a IPython widget to interactively view spectra of various pixels
Install Python Packages
gdal
h5py
requests
IPython
Data
Data and additional scripts required for this lesson are downloaded programmatically as part of the tutorial.
The hyperspectral imagery file used in this lesson was collected over NEON's Smithsonian Environmental Research Center field site in 2021 and processed at NEON headquarters.
In this exercise, we will learn how to extract and plot a spectral profile from a single pixel of a reflectance band in a NEON hyperspectral hdf5 file. To do this, we will use the aop_h5refl2array function to read in and clean our h5 reflectance data, and the Python package pandas to create a dataframe for the reflectance and associated wavelength data.
Spectral Signatures
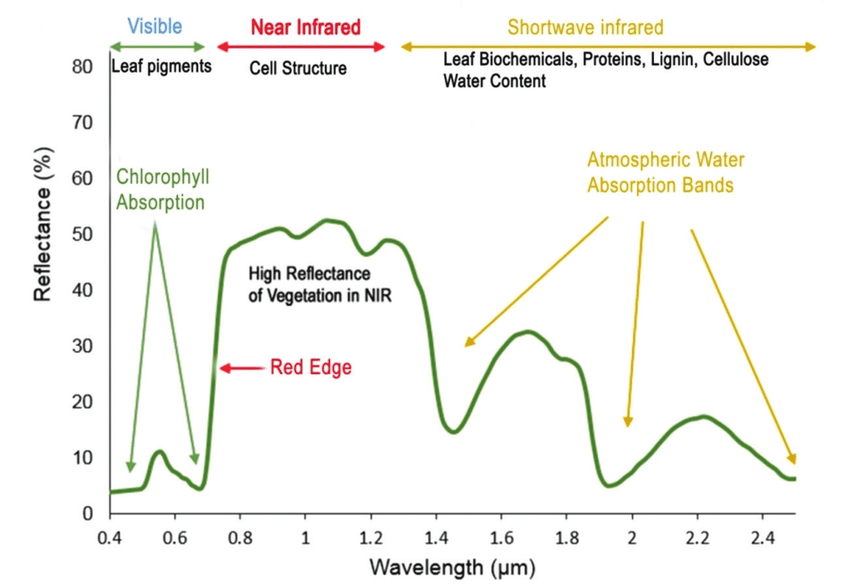
A spectral signature is a plot of the amount of light energy reflected by an object throughout the range of wavelengths in the electromagnetic spectrum. The spectral signature of an object conveys useful information about its structural and chemical composition. We can use these signatures to identify and classify different objects from a spectral image.
For example, vegetation has a distinct spectral signature.
Spectral signature of vegetation. Source: Roman, Anamaria & Ursu, Tudor. (2016). Multispectral satellite imagery and airborne laser scanning techniques for the detection of archaeological vegetation marks.
Vegetation has a unique spectral signature characterized by high reflectance in the near infrared wavelengths, and much lower reflectance in the green portion of the visible spectrum. For more details, please see Vegetation Analysis: Using Vegetation Indices in ENVI . We can extract reflectance values in the NIR and visible spectrums from hyperspectral data in order to map vegetation on the earth's surface. You can also use spectral curves as a proxy for vegetation health. We will explore this concept more in the next lesson, where we will caluclate vegetation indices.
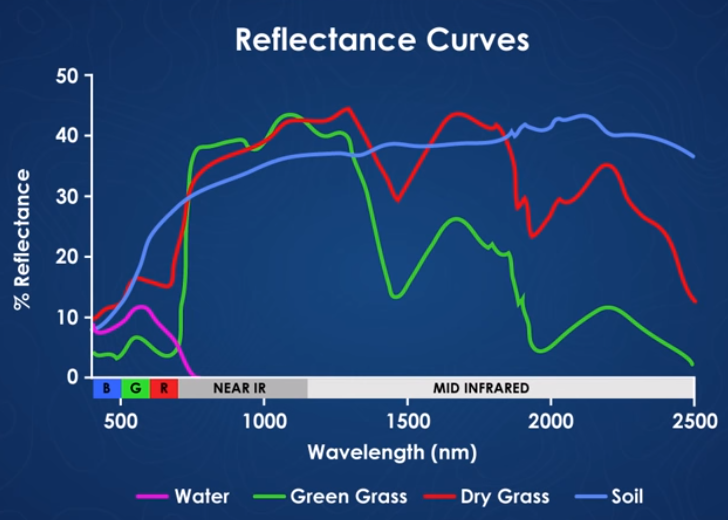
Example spectra of water, green grass, dry grass, and soil. Source: National Ecological Observatory Network (NEON)
import os, sys
import requests
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
This next function is a handy way to download the Python module and data that we will be using for this lesson. This uses the requests package.
# function to download data stored on the internet in a public url to a local file
def download_url(url,download_dir):
if not os.path.isdir(download_dir):
os.makedirs(download_dir)
filename = url.split('/')[-1]
r = requests.get(url, allow_redirects=True)
file_object = open(os.path.join(download_dir,filename),'wb')
file_object.write(r.content)
Download the module from its location on GitHub, add the python_modules to the path and import the neon_aop_hyperspectral.py module.
module_url = "https://raw.githubusercontent.com/NEONScience/NEON-Data-Skills/main/tutorials/Python/AOP/aop_python_modules/neon_aop_hyperspectral.py"
download_url(module_url,'../python_modules')
# os.listdir('../python_modules') #optionally show the contents of this directory to confirm the file downloaded
sys.path.insert(0, '../python_modules')
# import the neon_aop_hyperspectral module, the semicolon supresses an empty plot from displaying
import neon_aop_hyperspectral as neon_hs;
# define the data_url to point to the cloud storage location of the the hyperspectral hdf5 data file
data_url = "https://storage.googleapis.com/neon-aop-products/2021/FullSite/D02/2021_SERC_5/L3/Spectrometer/Reflectance/NEON_D02_SERC_DP3_368000_4306000_reflectance.h5"
# download the h5 data
download_url(data_url,'.\data')
# read the h5 reflectance file (including the full path) to the variable h5_file_name
h5_file_name = data_url.split('/')[-1]
h5_tile = os.path.join(".\data",h5_file_name)
# read in the data using the neon_hs module
serc_refl, serc_refl_md, wavelengths = neon_hs.aop_h5refl2array(h5_tile,'Reflectance')
Reading in .\data\NEON_D02_SERC_DP3_368000_4306000_reflectance.h5
Optionally, you can view the data stored in the metadata dictionary, and print the minimum, maximum, and mean reflectance values in the tile. In order to ignore NaN values, use numpy.nanmin/nanmax/nanmean.
for item in sorted(serc_refl_md):
print(item + ':',serc_refl_md[item])
print('\nSERC Tile Reflectance Stats:')
print('min:',np.nanmin(serc_refl))
print('max:',round(np.nanmax(serc_refl),2))
print('mean:',round(np.nanmean(serc_refl),2))
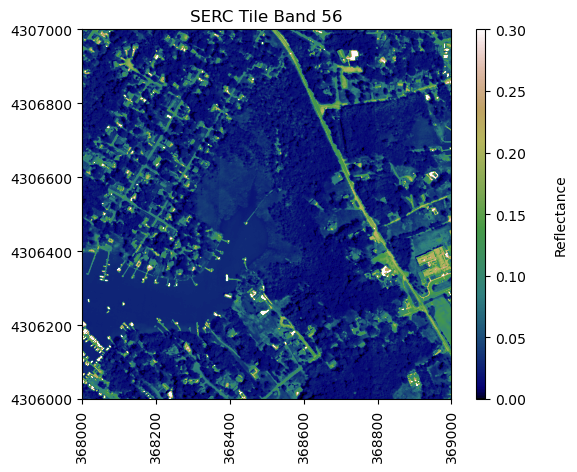
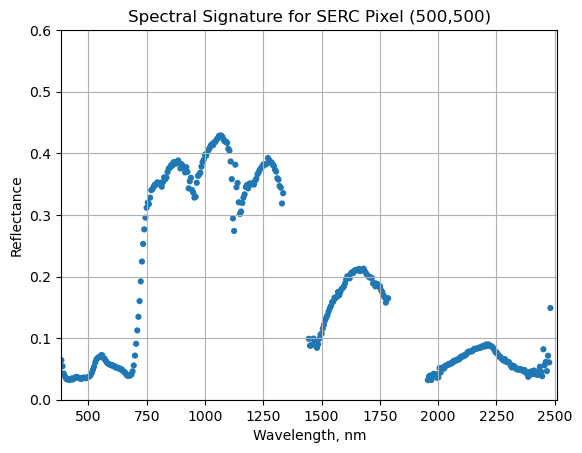
We can use pandas to create a dataframe containing the wavelength and reflectance values for a single pixel - in this example, we'll look at the center pixel of the tile (500,500). To extract all reflectance values from a single pixel, use splicing as we did before to select a single band, but now we need to specify (y,x) and select all bands (using :).
We can now plot the spectra, stored in this dataframe structure. pandas has a built in plotting routine, which can be called by typing .plot at the end of the dataframe.
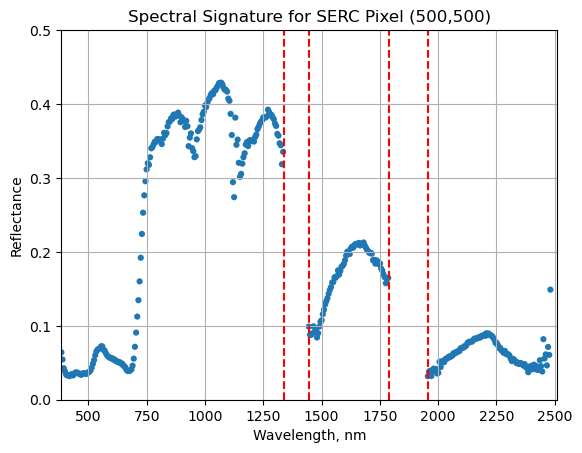
We can see from the spectral profile above that there are spikes in reflectance around ~1400nm and ~1800nm. These result from water vapor which absorbs light between wavelengths 1340-1445 nm and 1790-1955 nm. The atmospheric correction that converts radiance to reflectance subsequently results in a spike at these two bands. The wavelengths of these water vapor bands is stored in the reflectance attributes, which is saved in the reflectance metadata dictionary created with h5refl2array:
bbw1 = serc_refl_md['bad_band_window1'];
bbw2 = serc_refl_md['bad_band_window2'];
print('Bad Band Window 1:',bbw1)
print('Bad Band Window 2:',bbw2)
Bad Band Window 1: [1340 1445]
Bad Band Window 2: [1790 1955]
Below we repeat the plot we made above, but this time draw in the edges of the water vapor band windows that we need to remove.
serc_pixel_df.plot(x='wavelengths',y='reflectance',kind='scatter',edgecolor='none');
plt.title('Spectral Signature for SERC Pixel (500,500)')
ax1 = plt.gca(); ax1.grid('on')
ax1.set_xlim([np.min(serc_pixel_df['wavelengths']),np.max(serc_pixel_df['wavelengths'])]);
ax1.set_ylim(0,0.5)
ax1.set_xlabel("Wavelength, nm"); ax1.set_ylabel("Reflectance")
#Add in red dotted lines to show boundaries of bad band windows:
ax1.plot((1340,1340),(0,1.5), 'r--');
ax1.plot((1445,1445),(0,1.5), 'r--');
ax1.plot((1790,1790),(0,1.5), 'r--');
ax1.plot((1955,1955),(0,1.5), 'r--');
We can now set these bad band windows to nan, along with the last 10 bands, which are also often noisy (as seen in the spectral profile plotted above). First make a copy of the wavelengths so that the original metadata doesn't change.
w = wavelengths.copy() #make a copy to deal with the mutable data type
w[((w >= 1340) & (w <= 1445)) | ((w >= 1790) & (w <= 1955))]=np.nan #can also use bbw1[0] or bbw1[1] to avoid hard-coding in
w[-10:]=np.nan; # the last 10 bands sometimes have noise - best to eliminate
#print(w) #optionally print wavelength values to show that -9999 values are replaced with nan
Interactive Spectra Visualization
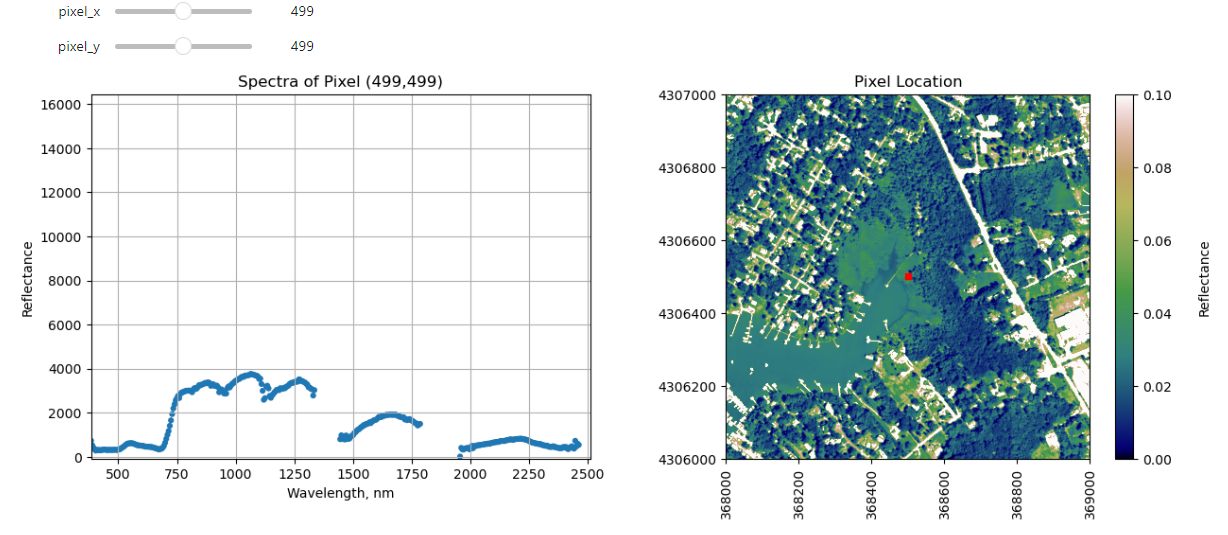
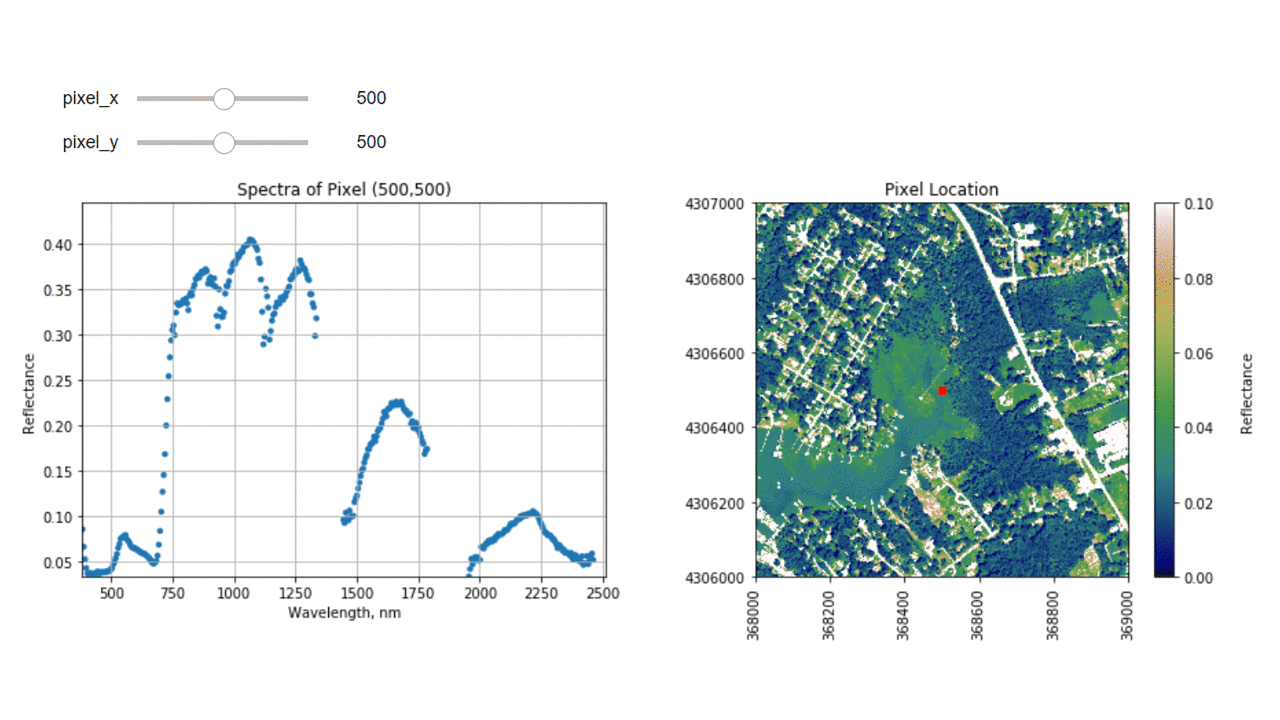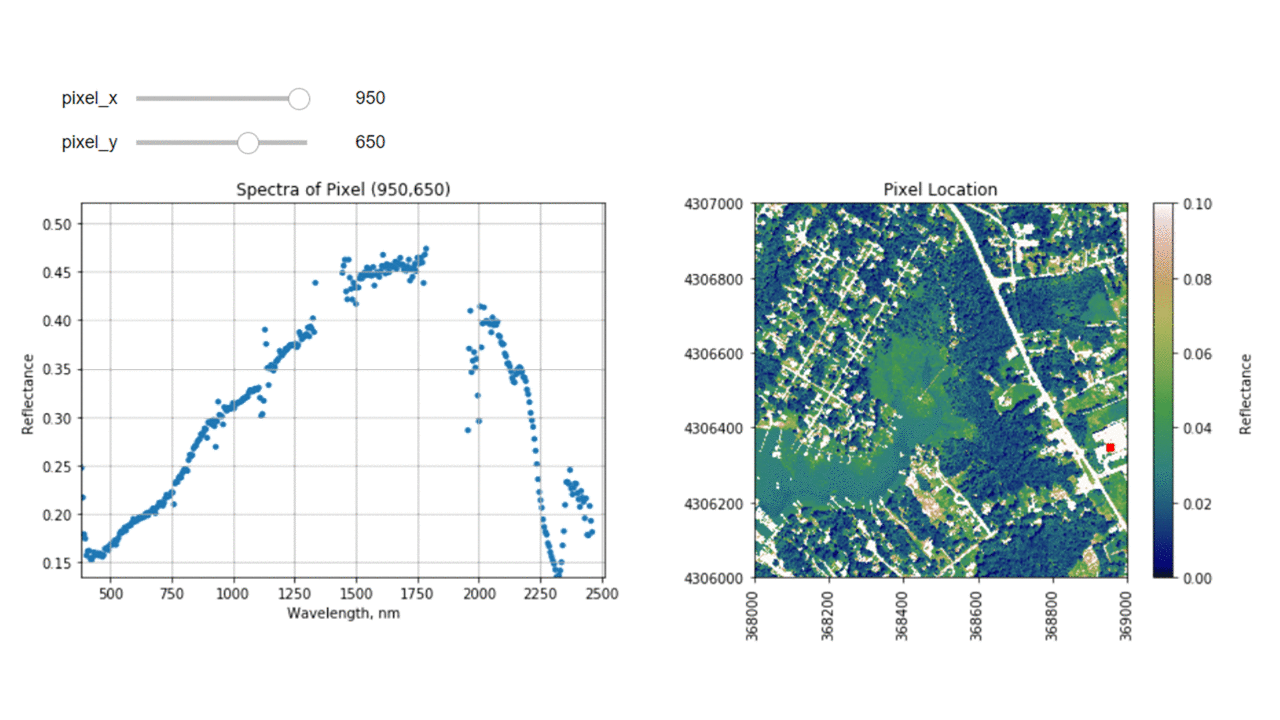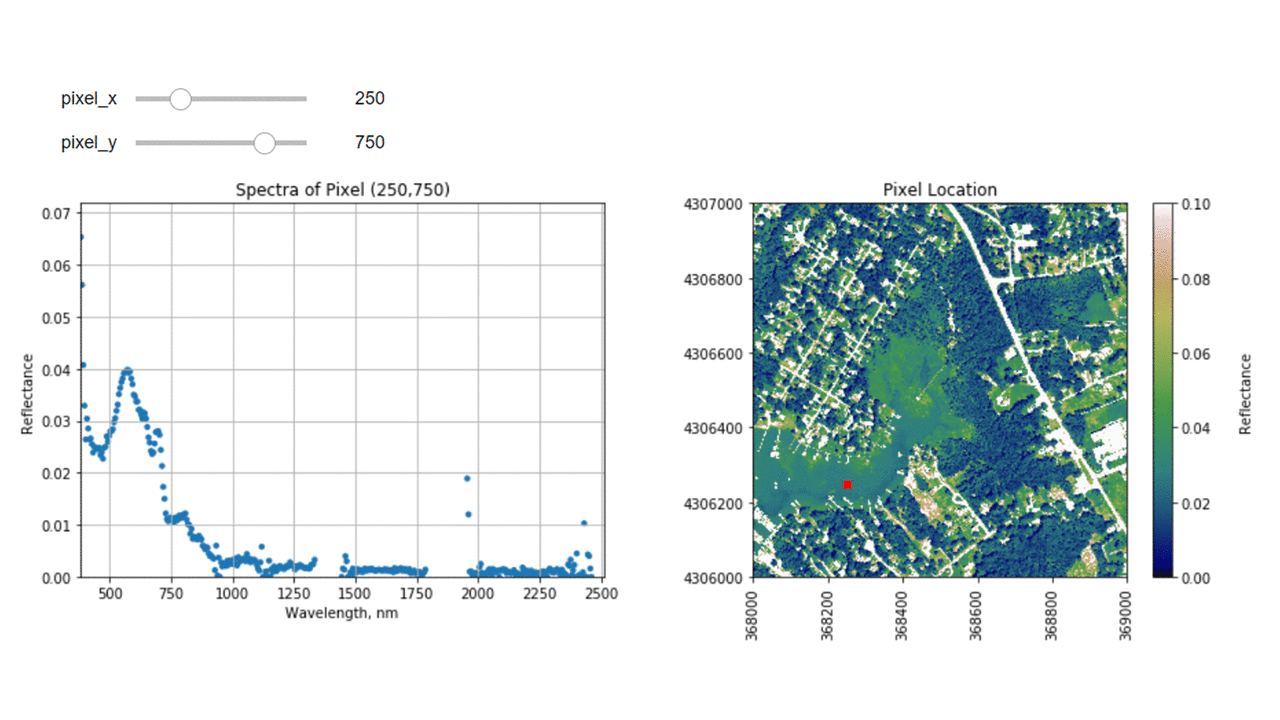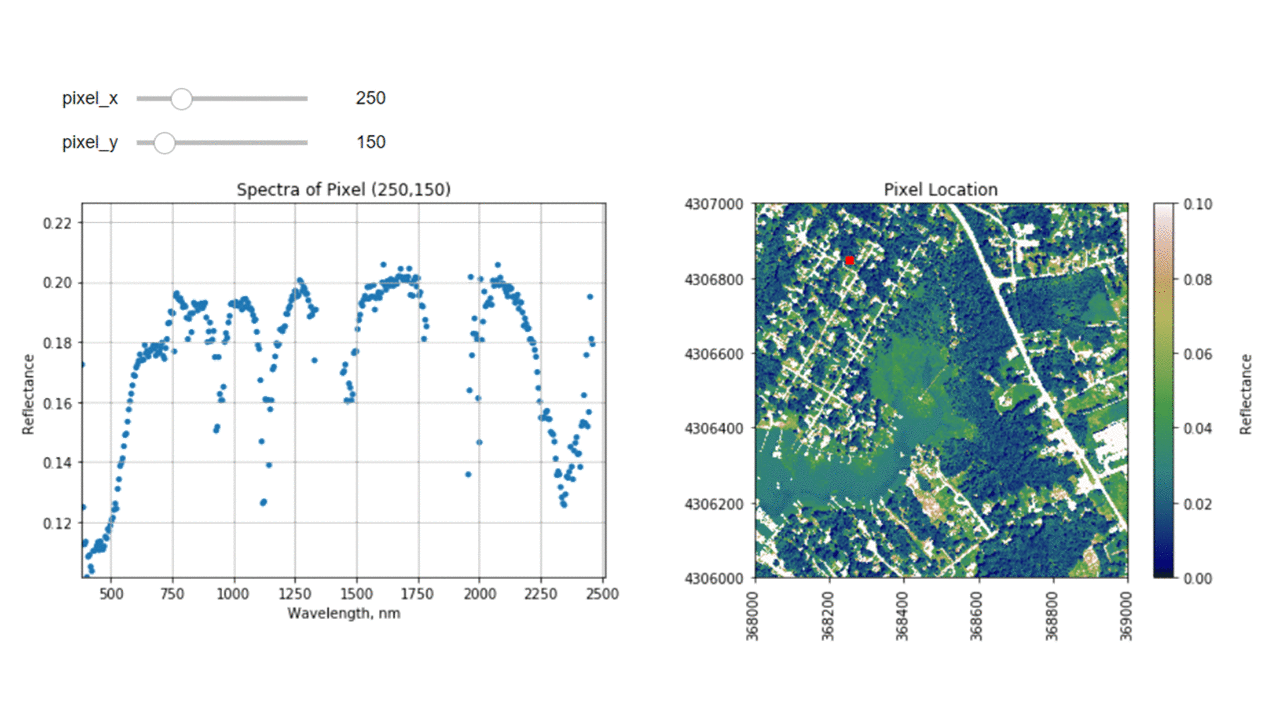
Finally, we can create a widget to interactively view the spectra of different pixels along the reflectance tile. Run the cell below, and select different pixel_x and pixel_y values to gain a sense of what the spectra look like for different materials on the ground.
#define refl_band, refl, and metadata, as copies of the original serc_refl data
refl_band = sercb56
refl = serc_refl.copy()
metadata = serc_refl_md.copy()
from IPython.html.widgets import *
def interactive_spectra_plot(pixel_x,pixel_y):
reflectance = refl[pixel_y,pixel_x,:]
pixel_df = pd.DataFrame()
pixel_df['reflectance'] = reflectance
pixel_df['wavelengths'] = w
fig = plt.figure(figsize=(15,5))
ax1 = fig.add_subplot(1,2,1)
# fig, axes = plt.subplots(nrows=1, ncols=2)
pixel_df.plot(ax=ax1,x='wavelengths',y='reflectance',kind='scatter',edgecolor='none');
ax1.set_title('Spectra of Pixel (' + str(pixel_x) + ',' + str(pixel_y) + ')')
ax1.set_xlim([np.min(wavelengths),np.max(wavelengths)]);
ax1.set_ylim([np.min(pixel_df['reflectance']),np.max(pixel_df['reflectance']*1.1)])
ax1.set_xlabel("Wavelength, nm"); ax1.set_ylabel("Reflectance")
ax1.grid('on')
ax2 = fig.add_subplot(1,2,2)
plot = plt.imshow(refl_band,extent=metadata['extent'],clim=(0,0.1));
plt.title('Pixel Location');
cbar = plt.colorbar(plot,aspect=20); plt.set_cmap('gist_earth');
cbar.set_label('Reflectance',rotation=90,labelpad=20);
ax2.ticklabel_format(useOffset=False, style='plain') #do not use scientific notation
rotatexlabels = plt.setp(ax2.get_xticklabels(),rotation=90) #rotate x tick labels 90 degrees
ax2.plot(metadata['extent'][0]+pixel_x,metadata['extent'][3]-pixel_y,'s',markersize=5,color='red')
ax2.set_xlim(metadata['extent'][0],metadata['extent'][1])
ax2.set_ylim(metadata['extent'][2],metadata['extent'][3])
interact(interactive_spectra_plot, pixel_x = (0,refl.shape[1]-1,1),pixel_y=(0,refl.shape[0]-1,1));
In this tutorial, we will learn how to extract and plot a spectral profile from a single pixel of a reflectance band in a NEON hyperspectral HDF5 file.
In this exercise, we will learn how to extract and plot a spectral profile from
a single pixel of a reflectance band in a NEON hyperspectral hdf5 file. To do
this, we will use the aop_h5refl2array function to read in and clean our h5
reflectance data, and the Python package pandas to create a dataframe for the
reflectance and associated wavelength data.
Spectral Signatures
A spectral signature is a plot of the amount of light energy reflected by an
object throughout the range of wavelengths in the electromagnetic spectrum. The
spectral signature of an object conveys useful information about its structural
and chemical composition. We can use these signatures to identify and classify
different objects from a spectral image.
Vegetation has a unique spectral signature characterized by high reflectance in
the near infrared wavelengths, and much lower reflectance in the green portion
of the visible spectrum. We can extract reflectance values in the NIR and visible
spectrums from hyperspectral data in order to map vegetation on the earth's
surface. You can also use spectral curves as a proxy for vegetation health. We
will explore this concept more in the next lesson, where we will caluclate
vegetation indices.
Example spectra of water, green grass, dry grass, and soil. Source: National Ecological Observatory Network (NEON)
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore') #don't display warnings
Import the hyperspectral functions file that you downloaded into the variable neon_hs (for neon hyperspectral):
import os
# Note: you will need to update this filepath according to your local machine
os.chdir("/Users/olearyd/Git/data/")
import neon_aop_hyperspectral as neon_hs
# Note: you will need to update this filepath according to your local machine
sercRefl, sercRefl_md = neon_hs.aop_h5refl2array('/Users/olearyd/Git/data/NEON_D02_SERC_DP3_368000_4306000_reflectance.h5')
Optionally, you can view the data stored in the metadata dictionary, and print the minimum, maximum, and mean reflectance values in the tile. In order to handle any nan values, use Numpynanminnanmax and nanmean.
for item in sorted(sercRefl_md):
print(item + ':',sercRefl_md[item])
print('SERC Tile Reflectance Stats:')
print('min:',np.nanmin(sercRefl))
print('max:',round(np.nanmax(sercRefl),2))
print('mean:',round(np.nanmean(sercRefl),2))
For reference, plot the red band of the tile, using splicing, and the plot_aop_refl function:
We can use pandas to create a dataframe containing the wavelength and reflectance values for a single pixel - in this example, we'll look at the center pixel of the tile (500,500).
import pandas as pd
To extract all reflectance values from a single pixel, use splicing as we did before to select a single band, but now we need to specify (y,x) and select all bands (using :).
We can now plot the spectra, stored in this dataframe structure. pandas has a built in plotting routine, which can be called by typing .plot at the end of the dataframe.
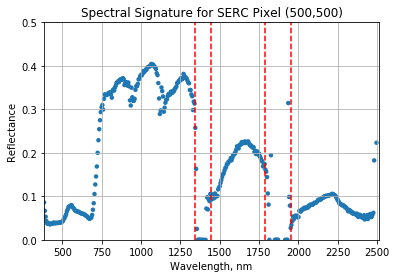
We can see from the spectral profile above that there are spikes in reflectance around ~1400nm and ~1800nm. These result from water vapor which absorbs light between wavelengths 1340-1445 nm and 1790-1955 nm. The atmospheric correction that converts radiance to reflectance subsequently results in a spike at these two bands. The wavelengths of these water vapor bands is stored in the reflectance attributes, which is saved in the reflectance metadata dictionary created with h5refl2array:
bbw1 = sercRefl_md['bad band window1'];
bbw2 = sercRefl_md['bad band window2'];
print('Bad Band Window 1:',bbw1)
print('Bad Band Window 2:',bbw2)
Bad Band Window 1: [1340 1445]
Bad Band Window 2: [1790 1955]
Below we repeat the plot we made above, but this time draw in the edges of the water vapor band windows that we need to remove.
serc_pixel_df.plot(x='wavelengths',y='reflectance',kind='scatter',edgecolor='none');
plt.title('Spectral Signature for SERC Pixel (500,500)')
ax1 = plt.gca(); ax1.grid('on')
ax1.set_xlim([np.min(serc_pixel_df['wavelengths']),np.max(serc_pixel_df['wavelengths'])]);
ax1.set_ylim(0,0.5)
ax1.set_xlabel("Wavelength, nm"); ax1.set_ylabel("Reflectance")
#Add in red dotted lines to show boundaries of bad band windows:
ax1.plot((1340,1340),(0,1.5), 'r--')
ax1.plot((1445,1445),(0,1.5), 'r--')
ax1.plot((1790,1790),(0,1.5), 'r--')
ax1.plot((1955,1955),(0,1.5), 'r--')
[<matplotlib.lines.Line2D at 0x81aaccb70>]
We can now set these bad band windows to nan, along with the last 10 bands, which are also often noisy (as seen in the spectral profile plotted above). First make a copy of the wavelengths so that the original metadata doesn't change.
import copy
w = copy.copy(sercRefl_md['wavelength']) #make a copy to deal with the mutable data type
w[((w >= 1340) & (w <= 1445)) | ((w >= 1790) & (w <= 1955))]=np.nan #can also use bbw1[0] or bbw1[1] to avoid hard-coding in
w[-10:]=np.nan; # the last 10 bands sometimes have noise - best to eliminate
#print(w) #optionally print wavelength values to show that -9999 values are replaced with nan
Interactive Spectra Visualization
Finally, we can create a widget to interactively view the spectra of different pixels along the reflectance tile. Run the two cells below, and interact with them to gain a better sense of what the spectra look like for different materials on the ground.
#define index corresponding to nan values:
nan_ind = np.argwhere(np.isnan(w))
#define refl_band, refl, and metadata
refl_band = sercb56
refl = copy.copy(sercRefl)
metadata = copy.copy(sercRefl_md)
This tutorial introduces NEON RGB camera images (Data Product DP3.30010.001) and uses the Python package rasterio to read in and plot the camera data in Python. In this lesson, we will read in an RGB camera tile collected over the NEON Smithsonian Environmental Research Center (SERC) site and plot the mutliband image, as well as the individual bands. This lesson was adapted from the rasterio plotting documentation.
Objectives
After completing this tutorial, you will be able to:
Plot a NEON RGB camera geotiff tile in Python using rasterio
Package Requirements
This tutorial was run in Python version 3.9, using the following packages:
rasterio
matplotlib
Download the Data
Download the NEON
camera (RGB) imagery tile
collected over the Smithsonian Environmental Research Station (SERC) NEON field site in 2021. Move this data to a desired folder on your local workstation. You will need to know the file path to this data.
You don't have to download from the link above; the tutorial will demonstrate how to download the data directly from Python into your working directory, but we recommend re-organizing in a way that makes sense for you.
Background
As part of the
NEON Airborne Operation Platform's
suite of remote sensing instruments, the digital camera producing high-resolution (<= 10 cm) photographs of the earth’s surface. The camera records light energy that has reflected off the ground in the visible portion (red, green and blue) of the electromagnetic spectrum. Often the camera images are used to provide context for the hyperspectral and LiDAR data, but they can also be used for research purposes in their own right. One such example is the tree-crown mapping work by Weinstein et al. - see the links below for more information!
Reference: Ben G Weinstein, Sergio Marconi, Stephanie A Bohlman, Alina Zare, Aditya Singh, Sarah J Graves, Ethan P White (2021) A remote sensing derived data set of 100 million individual tree crowns for the National Ecological Observatory Network eLife 10:e62922. https://doi.org/10.7554/eLife.62922
In this lesson we will keep it simple and show how to read in and plot a single camera file (1km x 1km ortho-mosaicked tile) - a first step in any research incorporating the AOP camera data (in Python).
Import required packages
First let's import the packages that we'll be using in this lesson.
import os
import requests
import rasterio as rio
from rasterio.plot import show, show_hist
import matplotlib.pyplot as plt
Next, let's download a camera file. For this tutorial, we will use the requests package to download a raster file from the public link where the data is stored. For simplicity, we will show how to download to a data folder in the working directory. You can move the data to a different folder, but if you do that, be sure to update the path to your data accordingly.
def download_url(url,download_dir):
if not os.path.isdir(download_dir):
os.makedirs(download_dir)
filename = url.split('/')[-1]
r = requests.get(url, allow_redirects=True)
file_object = open(os.path.join(download_dir,filename),'wb')
file_object.write(r.content)
# public url where the RGB camera tile is stored
rgb_url = "https://storage.googleapis.com/neon-aop-products/2021/FullSite/D02/2021_SERC_5/L3/Camera/Mosaic/2021_SERC_5_368000_4306000_image.tif"
# download the camera tile to a ./data subfolder in your working directory
download_url(rgb_url,'.\data')
# display the contents in the ./data folder to confirm the download completed
os.listdir('./data')
Open the Camera RGB data with rasterio
We can open and read this RGB data that we downloaded in Python using the rasterio.open function:
# read the RGB file (including the full path) to the variable rgb_dataset
rgb_name = rgb_url.split('/')[-1]
rgb_file = os.path.join(".\data",rgb_name)
rgb_dataset = rio.open(rgb_file)
Let's look at a few properties of this dataset to get a sense of the information stored in the rasterio object:
print('rgb_dataset:\n',rgb_dataset)
print('\nshape:\n',rgb_dataset.shape)
print('\nspatial extent:\n',rgb_dataset.bounds)
print('\ncoordinate information (crs):\n',rgb_dataset.crs)
Unlike the other AOP data products, camera imagery is generated at 10cm resolution, so each 1km x 1km tile will contain 10000 pixels (other 1m resolution data products will have 1000 x 1000 pixels per tile, where each pixel represents 1 meter).
Plot the RGB multiband image
We can use rasterio's built-in functions show to plot the CHM tile.
show(rgb_dataset);
Plot each band of the RGB image
We can also plot each band (red, green, and blue) individually as follows:
That's all for this example! Most of the other AOP raster data are all single band images, but rasterio is a handy Python package for working with any geotiff files. You can download and visualize the lidar and spectrometer derived raster images similarly.
The instructions below will guide you through using the neonUtilities R package
in Python, via the rpy2 package. rpy2 creates an R environment you can interact
with from Python.
The assumption in this tutorial is that you want to work with NEON data in
Python, but you want to use the handy download and merge functions provided by
the neonUtilities R package to access and format the data for analysis. If
you want to do your analyses in R, use one of the R-based tutorials linked
below.
For more information about the neonUtilities package, and instructions for
running it in R directly, see the Download and Explore tutorial
and/or the neonUtilities tutorial.
Install and set up
Before starting, you will need:
Python 3 installed. It is probably possible to use this workflow in Python 2,
but these instructions were developed and tested using 3.7.4.
R installed. You don't need to have ever used it directly. We wrote this
tutorial using R 4.1.1, but most other recent versions should also work.
rpy2 installed. Run the line below from the command line, it won't run within
a Python script. See Python documentation for more information on how to install packages.
rpy2 often has install problems on Windows, see "Windows Users" section below if
you are running Windows.
You may need to install pip before installing rpy2, if you don't have it
installed already.
From the command line, run pip install rpy2
Windows users
The rpy2 package was built for Mac, and doesn't always work smoothly on Windows.
If you have trouble with the install, try these steps.
Add C:\Program Files\R\R-3.3.1\bin\x64 to the Windows Environment Variable “Path”
Pick the correct version. At the download page the portion of the files
with cp## relate to the Python version. e.g., rpy2 2.9.2 cp36 cp36m win_amd64.whl
is the correct download when 2.9.2 is the latest version of rpy2 and you are
running Python 36 and 64 bit Windows (amd64).
Save the whl file, navigate to it in windows then run pip directly on the file
as follows “pip install rpy2 2.9.2 cp36 cp36m win_amd64.whl”
Add an R_HOME Windows environment variable with the path C:\Program Files\R\R-3.4.3
(or whichever version you are running)
Add an R_USER Windows environment variable with the path C:\Users\yourUserName\AppData\Local\Continuum\Anaconda3\Lib\site-packages\rpy2
Additional troubleshooting
If you're still having trouble getting R to communicate with Python, you can try
pointing Python directly to your R installation path.
Run R.home() in R.
Run import os in Python.
Run os.environ['R_HOME'] = '/Library/Frameworks/R.framework/Resources' in Python, substituting the file path you found in step 1.
Load packages
Now open up your Python interface of choice (Jupyter notebook, Spyder, etc) and import rpy2 into your session.
import rpy2
import rpy2.robjects as robjects
from rpy2.robjects.packages import importr
Load the base R functionality, using the rpy2 function importr().
base = importr('base')
utils = importr('utils')
stats = importr('stats')
The basic syntax for running R code via rpy2 is package.function(inputs),
where package is the R package in use, function is the name of the function
within the R package, and inputs are the inputs to the function. In other
words, it's very similar to running code in R as package::function(inputs).
For example:
Suppress R warnings. This step can be skipped, but will result in messages
getting passed through from R that Python will interpret as warnings.
from rpy2.rinterface_lib.callbacks import logger as rpy2_logger
import logging
rpy2_logger.setLevel(logging.ERROR)
Install the neonUtilities R package. Here I've specified the RStudio
CRAN mirror as the source, but you can use a different one if you
prefer.
You only need to do this step once to use the package, but we update
the neonUtilities package every few months, so reinstalling
periodically is recommended.
This installation step carries out the same steps in the same places on
your hard drive that it would if run in R directly, so if you use R
regularly and have already installed neonUtilities on your machine,
you can skip this step. And be aware, this also means if you install
other packages, or new versions of packages, via rpy2, they'll
be updated the next time you use R, too.
The semicolon at the end of the line (here, and in some other function
calls below) can be omitted. It suppresses a note indicating the output
of the function is null. The output is null because these functions download
or modify files on your local drive, but none of the data are read into the
Python or R environments.
The downloaded binary packages are in
/var/folders/_k/gbjn452j1h3fk7880d5ppkx1_9xf6m/T//Rtmpl5OpMA/downloaded_packages
Now load the neonUtilities package. This does need to be run every time
you use the code; if you're familiar with R, importr() is roughly
equivalent to the library() function in R.
neonUtilities = importr('neonUtilities')
Join data files: stackByTable()
The function stackByTable() in neonUtilities merges the monthly,
site-level files the NEON Data Portal
provides. Start by downloading the dataset you're interested in from the
Portal. Here, we'll assume you've downloaded IR Biological Temperature.
It will download as a single zip file named NEON_temp-bio.zip. Note the
file path it's saved to and proceed.
Run the stackByTable() function to stack the data. It requires only one
input, the path to the zip file you downloaded from the NEON Data Portal.
Modify the file path in the code below to match the path on your machine.
For additional, optional inputs to stackByTable(), see the R tutorial
for neonUtilities.
Stacking operation across a single core.
Stacking table IRBT_1_minute
Stacking table IRBT_30_minute
Merged the most recent publication of sensor position files for each site and saved to /stackedFiles
Copied the most recent publication of variable definition file to /stackedFiles
Finished: Stacked 2 data tables and 3 metadata tables!
Stacking took 2.019079 secs
All unzipped monthly data folders have been removed.
Check the folder containing the original zip file from the Data Portal;
you should now have a subfolder containing the unzipped and stacked files
called stackedFiles. To import these data to Python, skip ahead to the
"Read downloaded and stacked files into Python" section; to learn how to
use neonUtilities to download data, proceed to the next section.
Download files to be stacked: zipsByProduct()
The function zipsByProduct() uses the NEON API to programmatically download
data files for a given product. The files downloaded by zipsByProduct()
can then be fed into stackByTable().
Run the downloader with these inputs: a data product ID (DPID), a set of
4-letter site IDs (or "all" for all sites), a download package (either
basic or expanded), the filepath to download the data to, and an
indicator to check the size of your download before proceeding or not
(TRUE/FALSE).
The DPID is the data product identifier, and can be found in the data product
box on the NEON Explore Data page.
Here we'll download Breeding landbird point counts, DP1.10003.001.
There are two differences relative to running zipsByProduct() in R directly:
check.size becomes check_size, because dots have programmatic meaning
in Python
TRUE (or T) becomes 'TRUE' because the values TRUE and FALSE don't
have special meaning in Python the way they do in R, so it interprets them
as variables if they're unquoted.
check_size='TRUE' does not work correctly in the Python environment. In R,
it estimates the size of the download and asks you to confirm before
proceeding, and the interactive question and answer don't work correctly
outside R. Set check_size='FALSE' to avoid this problem, but be thoughtful
about the size of your query since it will proceed to download without checking.
Unpacking zip files using 1 cores.
Stacking operation across a single core.
Stacking table brd_countdata
Stacking table brd_perpoint
Copied the most recent publication of validation file to /stackedFiles
Copied the most recent publication of categoricalCodes file to /stackedFiles
Copied the most recent publication of variable definition file to /stackedFiles
Finished: Stacked 2 data tables and 4 metadata tables!
Stacking took 0.4586661 secs
All unzipped monthly data folders have been removed.
Read downloaded and stacked files into Python
We've downloaded biological temperature and bird data, and merged
the site by month files. Now let's read those data into Python so you
can proceed with analyses.
First let's take a look at what's in the output folders.
import os
os.listdir('/Users/Shared/filesToStack10003/stackedFiles/')
Each data product folder contains a set of data files and metadata files.
Here, we'll read in the data files and take a look at the contents; for
more details about the contents of NEON data files and how to interpret them,
see the Download and Explore tutorial.
There are a variety of modules and methods for reading tabular data into
Python; here we'll use the pandas module, but feel free to use your own
preferred method.
First, let's read in the two data tables in the bird data:
brd_countdata and brd_perpoint.
The function byFileAOP() uses the NEON API
to programmatically download data files for remote sensing (AOP) data
products. These files cannot be stacked by stackByTable() because they
are not tabular data. The function simply creates a folder in your working
directory and writes the files there. It preserves the folder structure
for the subproducts.
The inputs to byFileAOP() are a data product ID, a site, a year,
a filepath to save to, and an indicator to check the size of the
download before proceeding, or not. As above, set check_size="FALSE"
when working in Python. Be especially cautious about download size
when downloading AOP data, since the files are very large.
Here, we'll download Ecosystem structure (Canopy Height Model) data from
Hopbrook (HOPB) in 2017.
Downloading files totaling approximately 147.930656 MB
Downloading 217 files
|======================================================================| 100%
Successfully downloaded 217 files to /Users/Shared/DP3.30015.001
Let's read one tile of data into Python and view it. We'll use the
rasterio and matplotlib modules here, but as with tabular data,
there are other options available.
There are myriad resources out there to learn programming in R. After linking to
a tutorial on how to install R and RStudio on your computer, we then outline a
few different paths to learn R basics depending on how you enjoy learning, and
finally we include a few resources for intermediate and advanced learning.
Setting Up your Computer
Start out by installing R and, we recommend, RStudio, on your computer. RStudio
is an Interactive Development Environment (IDE) for the R program. It
is optional, but recommended when working with R. Directions
for installing can be found within the tutorial Install Git, Bash Shell, R & RStudio.
You will need administrator permissions on your computer.
Pathways to Learning the Basics of R
In-person trainings
If you prefer to learn through in-person trainings, consider local workshops
from The Carpentries Software Carpentry or Data Carpentry (generally ~$25 for a
2-day workshop), courses offered by a local college or university (prices vary),
or organize your colleagues to meet regularly to learn R together (free!).
Online interactive courses
If you prefer to learn in a semi-structured online environment, there are a wide
variety of online courses for learning R including Data Camp, Coursera, edX, and
Lynda.com. Many of these options include free introductory lessons or trial
periods as well as paid courses. We do not have personal experience with
these courses and do not recommend or specifically promote any course.
In program interactive course
Swirl
is guided introduction to R where you code along with the instructions in R. You
get direct feedback when you type a command incorrectly. To use this package,
once you have R or RStudio open and running, use the following commands to start
the first lesson.
install.packages("swirl")
library(swirl)
swirl()
Online tutorials
If you prefer a less structured online environment, these tutorial series may be
better suited for you.
Learn R with a focus on data analysis. Beyond the basics, it covers dyplr for
data aggregation & manipulation, ggplot2 for plotting, and touches on
interacting with an SQL database. Designed to be taught by an instructor but the
materials also work for independent learning online.
This comprehensive course contains an R section. While the overall focus is on
data science skills, learning R is a portion of it (note, this is an extensive
course).
RStudio links to many other learning opportunities. Start with the 'Beginners'
learning path.
Video tutorials
A blend of having an instructor and self-paced, video tutorials may also be of
interest. New stand-alone video tutorials are out each day, so we aren’t going
to recommend a specific series. Find what works for you by searching
“R Programming video tutorials” on YouTube.
Books
Books are still a great way to learn R (and other languages). Many books are
available at local libraries (university or community) or online, if you want to
try them out before buying. Below are a few of the many, many books that data
scientists working on the NEON project have found useful.
Michael Crawley’s The R Book
is a classic that takes you from beginning steps to analyses and modelling.
Grolemun and Wickham’s R for Data Science
focuses on using R in data science applications using Hadley Wickham’s
“tidyverse”. It does assume some basic familiarity with R. Bonus: it is available
online or in book format!
(If you are completely new, they recommend starting with
Hands-on Programming with R).
Beyond the Basics
There are many intermediate and advanced courses, lessons, and tutorials linked
in the above resources. For example, the Swirl package offers intermediate and
advanced courses on specific topics, as does RStudio's list. See courses here;
development is ongoing so new courses may be added.
However, once the basics are handled, you will find that much of your learning
will happen through solving individual problems you encounter. To solve these
problems, your favorite search engine is your friend. Paste the error (without
specifics to your file/data) into the search menu and find answers from those
who have had similar questions.
For more on working with NEON data in particular, be sure to check out the other
NEON data tutorials.
This tutorial provides the basics on how to set up Docker on one's local computer
and then connect to an eddy4R Docker container in order to use the eddy4R R package.
There are no specific skills needed for this tutorial, however, you will need to
know how to access the command line tool for your operating system
(basic instructions given).
Learning Objectives
After completing this tutorial, you will be able to:
Access Docker on your local computer.
Access the eddy4R package in a RStudio Docker environment.
Things You’ll Need To Complete This Tutorial
You will need internet access and an up to date browser.
Sources
The directions on how to install docker are heavily borrowed from the author's
of CyVerse's Container Camp's
Intro to Docker and we thank them for providing the information.
The directions for how to access eddy4R comes from
Metzger, S., D. Durden, C. Sturtevant, H. Luo, N. Pingintha-durden, and T. Sachs (2017). eddy4R 0.2.0: a DevOps model for community-extensible processing and analysis of eddy-covariance data based on R, Git, Docker, and HDF5. Geoscientific Model Development 10:3189–3206. doi:
10.5194/gmd-10-3189-2017.
The eddy4R versions within the tutorial have been updated to the 1.0.0 release that accompanied the following manuscript:
Metzger, S., E. Ayres, D. Durden, C. Florian, R. Lee, C. Lunch, H. Luo, N. Pingintha-Durden, J.A. Roberti, M. SanClements, C. Sturtevant, K. Xu, and R.C. Zulueta, 2019: From NEON Field Sites to Data Portal: A Community Resource for Surface–Atmosphere Research Comes Online. Bull. Amer. Meteor. Soc., 100, 2305–2325, https://doi.org/10.1175/BAMS-D-17-0307.1.
In the tutorial below, we give the very barest of information to get Docker set
up for use with the NEON R package eddy4R. For more information on using Docker,
consider reading through the content from CyVerse's Container Camp's
Intro to Docker.
Install Docker
To work with the eddy4R–Docker image, you first need to sign up for an
account at DockerHub.
Once logged in, getting Docker up and running on your favorite operating system
(Mac/Windows/Linux) is very easy. The "getting started" guide on Docker has
detailed instructions for setting up Docker. Unless you plan on being a very
active user and devoloper in Docker, we recommend starting with the stable channel
(not edge channel) as you may encounter fewer problems.
If you're using Docker for Windows make sure you have
shared your drive.
If you're using an older version of Windows or MacOS, you may need to use
Docker Machine
instead.
Test Docker installation
Once you are done installing Docker, test your Docker installation by running
the following command to make sure you are using version 1.13 or higher.
You will need an open shell window (Linux; Mac=Terminal) or the Docker
Quickstart Terminal (Windows).
docker --version
When run, you will see which version of Docker you are currently running.
Note: If you run just the word docker you should see a whole bunch of
lines showing the different options available with docker. Alternatively
you can test your installation by running the following:
docker run hello-world
Notice that the first line states that the image can't be found locally. The
next few lines are pulling the image, so if you were to run the hello-world
prompt again, it would already be local and you'd see the message start at
"Hello from Docker!".
If these steps work, you are ready to go on to access the
eddy4R-Docker image that houses the suite of eddy4R R
packages. If these steps have not worked, follow the installation
instructions a second time.
Accessing eddy4R
Download of the eddy4R–Docker image and subsequent creation of a local container
can be performed by two simple commands in an open shell (Linux; Mac = Terminal)
or the Docker Quickstart Terminal (Windows).
The first command docker login will prompt you for your DockerHub ID and password.
The second command docker run -d -p 8787:8787 -e PASSWORD=YOURPASSWORD stefanmet/eddy4r:1.0.0 will
download the latest eddy4R–Docker image and start a Docker container that
utilizes port 8787 for establishing a graphical interface via web browser.
docker run: docker will preform some process on an isolated container
-d: the container will start in a detached mode, which means the container
run in the background and will print the container ID
-p: publish a container to a specified port (which follows)
8787:8787: specify which port you want to use. The default 8787:8787
is great if you are running locally. The first 4 digits are the
port on your machine, the last 4 digits are the port communicating with
RStudio on Docker. You can change the first 4 digits if you want to use a
different port on your machine, or if you are running many containers or
are on a shared network, but the last 4 digits need to be 8787.
-e PASSWORD=YOURPASSWORD: define a password environmental variable to use upon login to the Rstudio instance. YOURPASSWORD can be anything you want.
stefanmet/eddy4r:1.0.0: finally, which container do you want to run.
Now try it.
docker login
docker run -d -p 8787:8787 -e PASSWORD=YOURPASSWORD stefanmet/eddy4r:1.0.0
This last command will run a specified release version (eddy4r:1.0.0) of the
Docker image. Alternatively you can use eddy4r:latest to get the most up-to-date
development image of eddy4r.
If you are using data stored on your local machine, rather than cloud hosting, a
physical file system location on the host computer (local/dir) can be mounted
to a file system location inside the Docker container (docker/dir). This is
achieved with the Docker run option -v local/dir:docker/dir.
Access RStudio session
Now you can access the interactive RStudio session for using eddy4r by using any
web browser and going to http://host-ip-address:8787 where host-ip-address
is the internal IP address of the Docker host. For example, if your host IP address
is 10.100.90.169 then you should type http://10.100.90.169:8787 into your browser.
To determine the IP address of your Docker host, follow the instructions below
for your operating system.
Windows
Depending on the version of Docker, older Docker Toolbox versus the newer Docker Desktop for Windows, there are different way to get the docker machine IP address:
Docker Toolbox - Type docker-machine ip default into cmd.exe window. The output will be your local IP address for the docker machine.
Docker Desktop for Windows - Type ipconfig into cmd.exe window. The output will include either DockerNAT IPv4 address or vEthernet IPv4 address that docker uses to communicate to the internet, which in most cases will be 10.0.75.1.
Mac
Type ifconfig | grep "inet " | grep -v 127.0.0.1 into your Terminal window.
The output will be one or more local IP addresses for the docker machine. Use
the numbers after the first inet output.
Linux
Type localhost in a shell session and the local IP will be the output.
Once in the web browser you can log into this instance of the RStudio session
with the username as rstudio and password as defined by YOURPASSWORD. Once complete you are now in
a RStudio user interface with eddy4R installed and ready to use.