Tutorial
Intro to Working with Hyperspectral Remote Sensing Data in HDF5 Format in R
Last Updated: Jul 1, 2026
In this tutorial, we will show how to read and extract NEON reflectance data stored within an HDF5 file using R.
Learning Objectives
After completing this tutorial, you will be able to:
- Explain how HDF5 data can be used to store spatial data and the benefits of this format when working with large spatial data cubes.
- Extract metadata from HDF5 files.
- Slice or subset HDF5 data. You will extract one band of pixels.
- Plot a matrix as an image and a raster.
- Export a final GeoTIFF (spatially projected) that can be used both in further analysis and in common GIS tools like QGIS.
Things You’ll Need To Complete This Tutorial
To complete this tutorial you will need the most current version of R and, preferably, RStudio installed on your computer.
As of June 2026, NEON requires an API token for data downloads, to reduce bot scraping and improve user support. Tokens can be generated in NEON data portal user accounts - log in to your account or create one, and go to the API Tokens section. For best practices in storing and using tokens, follow the instructions here.
R Libraries to Install:
-
rhdf5:
install.packages("BiocManager"),BiocManager::install("rhdf5") -
terra:
install.packages("terra") -
neonUtilities:
install.packages("neonUtilities")
More on Packages in R - Adapted from Software Carpentry.
Data to Download
Data will be downloaded in the tutorial using the neonUtilities::byTileAOP() function.
These hyperspectral remote sensing data provide information on the National Ecological Observatory Network's San Joaquin Experimental Range field site in March of 2021. The data were collected over the San Joaquin field site located in California (Domain 17).The entire dataset can be also be downloaded from the NEON Data Portal.
R Script & Challenge Code: NEON data lessons often contain challenges to reinforce skills. If available, the code for challenge solutions is found in the downloadable R script of the entire lesson, available in the footer of each lesson page.
About Hyperspectral Remote Sensing Data
The electromagnetic spectrum is composed of thousands of bands representing different types of light energy. Imaging spectrometers (instruments that collect hyperspectral data) break the electromagnetic spectrum into groups of bands that support classification of objects by their spectral properties on the Earth's surface. Hyperspectral data consists of many bands - up to hundreds of bands - that span a portion of the electromagnetic spectrum, from the visible to the Short Wave Infrared (SWIR) regions.
The NEON imaging spectrometer (NIS) collects data within the 380 nm to 2510 nm portions of the electromagnetic spectrum within bands that are approximately 5 nm in width. This results in a hyperspectral data cube that contains approximately 426 bands - which means BIG DATA.
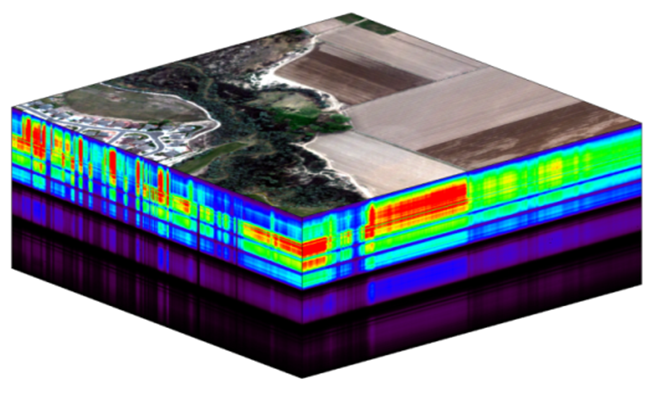
The HDF5 data model natively compresses data stored within it (makes it smaller) and supports data slicing (extracting only the portions of the data that you need to work with rather than reading the entire dataset into memory). These features make it ideal for working with large data cubes such as those generated by imaging spectrometers, in addition to supporting spatial data and associated metadata.
In this tutorial we will demonstrate how to read and extract spatial raster data stored within an HDF5 file using R.
Read HDF5 data into R
We will use the terra and rhdf5 packages to read in the HDF5 file that contains hyperspectral data for the NEON San Joaquin (SJER) field site.
Let's start by calling the needed packages and reading in our NEON HDF5 file.
Please be sure that you have at least version 2.10 of rhdf5 installed. Use:
packageVersion("rhdf5") to check the package version.
Data Tip: To update all packages installed in R, use update.packages().
# Load `terra` and `rhdf5` packages to read NIS data into R
library(terra)
library(rhdf5)
library(neonUtilities)
# Read in NEON_TOKEN (see "Things You'll Need to Complete This Tutorial" section to set this up)
token <- Sys.getenv("NEON_TOKEN")
Set the working directory to ensure R can find the file we are importing, and we know where the file is being saved. You can move the file that is downloaded afterward, but be sure to re-set the path to the file.
data_dir <- "~/data/" #This will depend on your local environment
We can use the neonUtilities function byTileAOP to download a single reflectance tile. You can run help(byTileAOP) to see more details on what the various inputs are. For this exercise, we'll specify the UTM Easting and Northing to be (257500, 4112500), which will download the tile with the lower left corner (257000,4112000). By default, the function will check the size total size of the download and ask you whether you wish to proceed (y/n). This file is ~672.7 MB, so make sure you have enough space on your local drive. You can set check.size=FALSE if you want to download without a prompt.
byTileAOP(dpID='DP3.30006.001',
site='SJER',
year='2021',
easting=257500,
northing=4112500,
check.size=TRUE, # set to FALSE if you don't want to enter y/n
savepath = data_dir,
token=token)
This file will be downloaded into a nested subdirectory under the ~/data folder, inside a folder named DP3.30006.001 (the Data Product ID). The file should show up in this location: ~/data/DP3.30006.001/neon-aop-products/2021/FullSite/D17/2021_SJER_5/L3/Spectrometer/Reflectance/NEON_D17_SJER_DP3_257000_4112000_reflectance.h5.
Data Tip: To make sure you are pointing to the correct path, look in the ~/data folder and navigate to where the .h5 file is saved, or use the R command list.files(path=data_dir,pattern="\\.h5$",recursive=TRUE,full.names=TRUE) to display the full path of the .h5 file. Note, if you have any other .h5 files downloaded in this folder, it will display all of the hdf5 files.
# Define the h5 file name to be opened
h5_file <- paste0(data_dir,"DP3.30006.001/neon-aop-products/2021/FullSite/D17/2021_SJER_5/L3/Spectrometer/Reflectance/NEON_D17_SJER_DP3_257000_4112000_reflectance.h5")
You can use h5ls and/or View(h5ls(...)) to look at the contents of the hdf5 file, as follows:
# look at the HDF5 file structure
View(h5ls(h5_file,all=T))
When you look at the structure of the data, take note of the "map info" dataset, the Coordinate_System group, and the wavelength and Reflectance datasets. The Coordinate_System folder contains the spatial attributes of the data including its EPSG Code, which is easily converted to a Coordinate Reference System (CRS). The CRS documents how the data are physically located on the Earth. The wavelength dataset contains the wavelength values for each band in the data. The Reflectance dataset contains the image data that we will use for both data processing and visualization.
More Information on raster metadata:
-
Raster Data in R - The Basics - this tutorial explains more about how rasters work in R and their associated metadata.
-
About Hyperspectral Remote Sensing Data -this tutorial explains more about metadata and important concepts associated with multi-band (multi and hyperspectral) rasters.
Data Tip - HDF5 Structure: Note that the structure of individual HDF5 files may vary depending on who produced the data. In this case, the Wavelength and reflectance data within the file are both h5 datasets. However, the spatial information is contained within a group. Data downloaded from another organization (like NASA) may look different. This is why it's important to explore the data as a first step!
We can use the h5readAttributes() function to read and extract metadata from the HDF5 file. Let's start by learning about the wavelengths described within this file.
# get information about the wavelengths of this dataset
wavelengthInfo <- h5readAttributes(h5_file,"/SJER/Reflectance/Metadata/Spectral_Data/Wavelength")
wavelengthInfo
## $Description
## [1] "Central wavelength of the reflectance bands."
##
## $Units
## [1] "nanometers"
Next, we can use the h5read function to read the data contained within the HDF5 file. Let's read in the wavelengths of the band centers:
# read in the wavelength information from the HDF5 file
wavelengths <- h5read(h5_file,"/SJER/Reflectance/Metadata/Spectral_Data/Wavelength")
head(wavelengths)
## [1] 381.6035 386.6132 391.6229 396.6327 401.6424 406.6522
tail(wavelengths)
## [1] 2485.693 2490.703 2495.713 2500.722 2505.732 2510.742
Which wavelength is band 21 associated with?
(Hint: look at the wavelengths vector that we just imported and check out the data located at index 21 - wavelengths[21]).
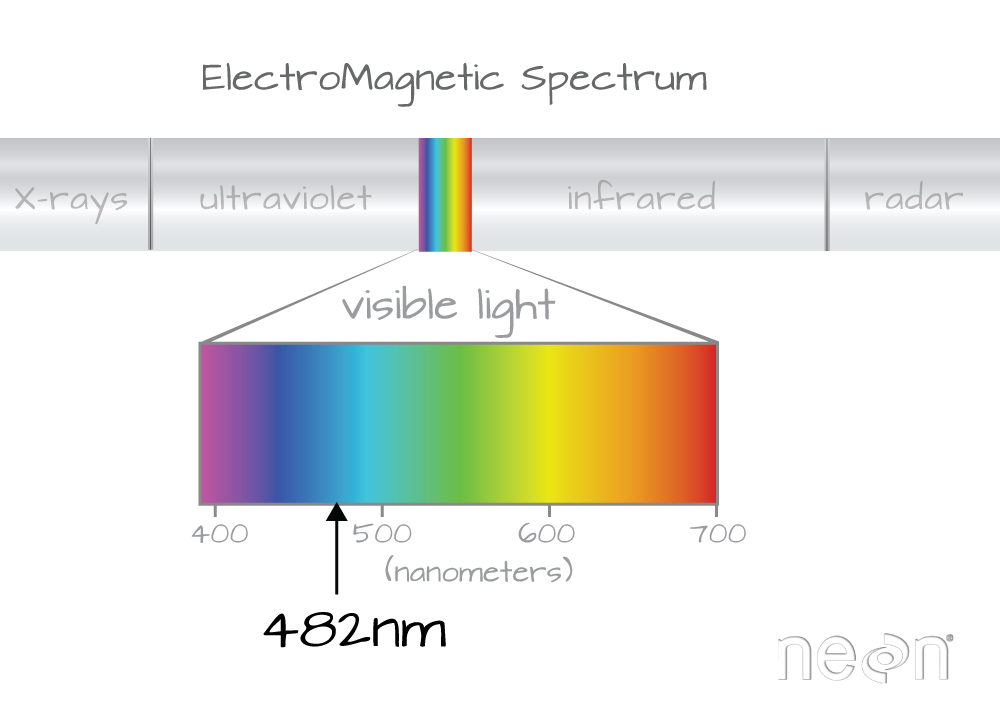
Band 21 has a associated wavelength center of 481.7982 nanometers (nm) which is in the blue portion (~380-500 nm) of the visible electromagnetic spectrum (~380-700 nm).
Bands and Wavelengths
A band represents a group of wavelengths. For example, the wavelength values between 695 nm and 700 nm might be one band captured by an imaging spectrometer. The imaging spectrometer collects reflected light energy in a pixel for light in that band. Often when you work with a multi- or hyperspectral dataset, the band information is reported as the center wavelength value. This value represents the mean value of the wavelengths represented in that band. Thus in a band spanning 695-700 nm, the center would be 697.5 nm). The full width half max (FWHM) will also be reported. This value can be thought of as the spread of the band around that center point. So, a band that covers 800-805 nm might have a FWHM of 5 nm and a wavelength value of 802.5 nm.
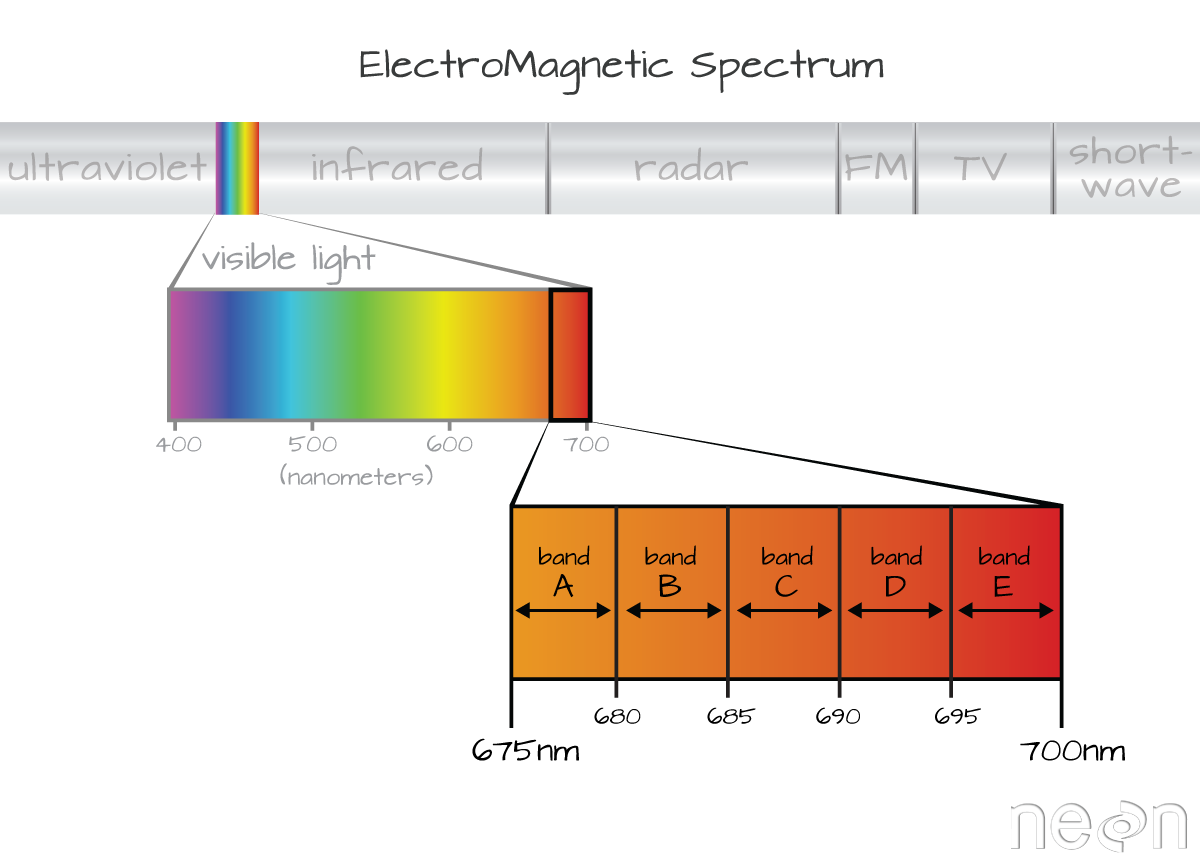
The HDF5 dataset that we are working with in this activity may contain more information than we need to work with. For example, we don't necessarily need to process all 426 bands available in a full NEON hyperspectral reflectance file - if we are interested in creating a product like NDVI which only uses bands in the Near InfraRed (NIR) and Red portions of the spectrum. Or we might only be interested in a spatial subset of the data - perhaps an area where we have collected corresponding ground data in the field.
The HDF5 format allows us to slice (or subset) the data - quickly extracting the subset that we need to process. Let's extract one of the green bands - band 34.
By the way - what is the center wavelength value associated with band 34?
Hint: wavelengths[34].
How do we know this band is a green band in the visible portion of the spectrum?
In order to effectively subset our data, let's first read the reflectance metadata stored as attributes in the "Reflectance_Data" dataset.
# First, we need to extract the reflectance metadata:
reflInfo <- h5readAttributes(h5_file, "/SJER/Reflectance/Reflectance_Data")
reflInfo
## $Cloud_conditions
## [1] "For cloud conditions information see Weather Quality Index dataset."
##
## $Cloud_type
## [1] "Cloud type may have been selected from multiple flight trajectories."
##
## $Data_Ignore_Value
## [1] -9999
##
## $Description
## [1] "Atmospherically corrected reflectance."
##
## $Dimension_Labels
## [1] "Line, Sample, Wavelength"
##
## $Dimensions
## [1] 1000 1000 426
##
## $Interleave
## [1] "BSQ"
##
## $Scale_Factor
## [1] 10000
##
## $Spatial_Extent_meters
## [1] 257000 258000 4112000 4113000
##
## $Spatial_Resolution_X_Y
## [1] 1 1
##
## $Units
## [1] "Unitless."
##
## $Units_Valid_range
## [1] 0 10000
# Next, we read the different dimensions
nRows <- reflInfo$Dimensions[1]
nCols <- reflInfo$Dimensions[2]
nBands <- reflInfo$Dimensions[3]
nRows
## [1] 1000
nCols
## [1] 1000
nBands
## [1] 426
The HDF5 read function reads data in the order: Bands, Cols, Rows. This is different from how R reads data. We'll adjust for this later.
# Extract or "slice" data for band 34 from the HDF5 file
b34 <- h5read(h5_file,"/SJER/Reflectance/Reflectance_Data",index=list(34,1:nCols,1:nRows))
# what type of object is b34?
class(b34)
## [1] "array"
A Note About Data Slicing in HDF5
Data slicing allows us to extract and work with subsets of the data rather than reading in the entire dataset into memory. In this example, we will extract and plot the green band without reading in all 426 bands. The ability to slice large datasets makes HDF5 ideal for working with big data.
Next, let's convert our data from an array (more than 2 dimensions) to a matrix (just 2 dimensions). We need to have our data in a matrix format to plot it.
# convert from array to matrix by selecting only the first band
b34 <- b34[1,,]
# display the class of this re-defined variable
class(b34)
## [1] "matrix" "array"
Arrays vs. Matrices
Arrays are matrices with more than 2 dimensions. When we say dimension, we are talking about the "z" associated with the data (imagine a series of tabs in a spreadsheet). Put the other way: matrices are arrays with only 2 dimensions. Arrays can have any number of dimensions one, two, ten or more.
Here is a matrix that is 4 x 3 in size (4 rows and 3 columns):
| Metric | species 1 | species 2 |
|---|---|---|
| total number | 23 | 45 |
| average weight | 14 | 5 |
| average length | 2.4 | 3.5 |
| average height | 32 | 12 |
Dimensions in Arrays
An array contains 1 or more dimensions in the "z" direction. For example, let's say that we collected the same set of species data for every day in a 30 day month. We might then have a matrix like the one above for each day for a total of 30 days making a 4 x 3 x 30 array (this dataset has more than 2 dimensions). More on R object types here (links to external site, DataCamp).
Next, let's look at the metadata for the reflectance data. When we do this, take note of 1) the scale factor and 2) the data ignore value. Then we can plot the band 34 data. Plotting spatial data as a visual "data check" is a good idea to make sure processing is being performed correctly and all is well with the image.
# look at the metadata for the reflectance dataset
h5readAttributes(h5_file,"/SJER/Reflectance/Reflectance_Data")
## $Cloud_conditions
## [1] "For cloud conditions information see Weather Quality Index dataset."
##
## $Cloud_type
## [1] "Cloud type may have been selected from multiple flight trajectories."
##
## $Data_Ignore_Value
## [1] -9999
##
## $Description
## [1] "Atmospherically corrected reflectance."
##
## $Dimension_Labels
## [1] "Line, Sample, Wavelength"
##
## $Dimensions
## [1] 1000 1000 426
##
## $Interleave
## [1] "BSQ"
##
## $Scale_Factor
## [1] 10000
##
## $Spatial_Extent_meters
## [1] 257000 258000 4112000 4113000
##
## $Spatial_Resolution_X_Y
## [1] 1 1
##
## $Units
## [1] "Unitless."
##
## $Units_Valid_range
## [1] 0 10000
# plot the image
image(b34)
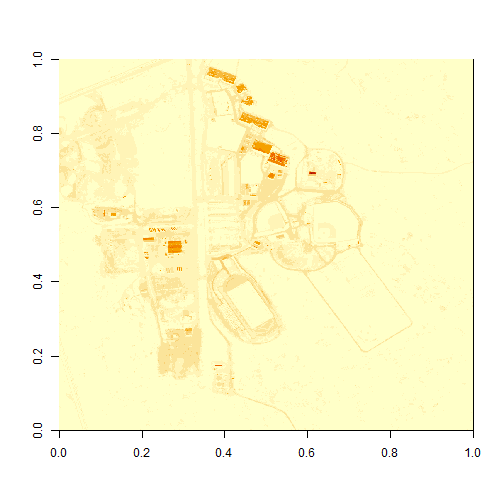
What do you notice about the first image? It's washed out and lacking any detail. What could be causing this? It got better when plotting the log of the values, but still not great.
# this is a little hard to visually interpret - what happens if we plot a log of the data?
image(log(b34))

Let's look at the distribution of reflectance values in our data to figure out what is going on.
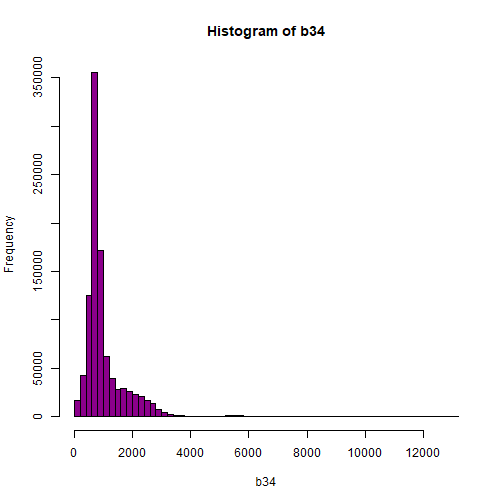
# Plot range of reflectance values as a histogram to view range
# and distribution of values.
hist(b34,breaks=50,col="darkmagenta")
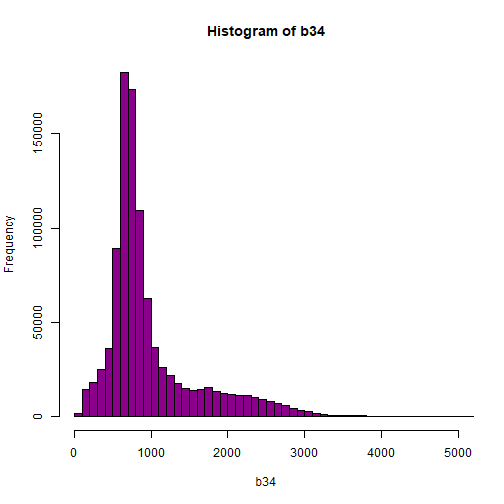
# View values between 0 and 5000
hist(b34,breaks=100,col="darkmagenta",xlim = c(0, 5000))
# View higher values
hist(b34, breaks=100,col="darkmagenta",xlim = c(5000, 15000),ylim = c(0, 750))
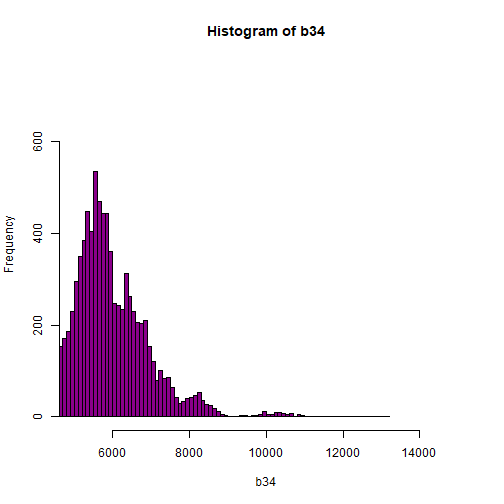
As you're examining the histograms above, keep in mind that reflectance values range between 0-1. The data scale factor in the metadata tells us to divide all reflectance values by 10,000. Thus, a value of 5,000 equates to a reflectance value of 0.50. Storing data as integers (without decimal places) compared to floating points (with decimal places) creates a smaller file. This type of scaling is commin in remote sensing datasets.
Notice in the data that there are some larger reflectance values (>5,000) that represent a smaller number of pixels. These pixels are skewing how the image renders.
Data Ignore Value
Image data in raster format will often contain a data ignore value and a scale factor. The data ignore value represents pixels where there are no data. Among other causes, no data values may be attributed to the sensor not collecting data in that area of the image or to processing results which yield null values.
Remember that the metadata for the Reflectance dataset designated -9999 as data ignore value. Thus, let's set all pixels with a value == -9999 to NA (no value). If we do this, R won't render these pixels.
# there is a no data value in our raster - let's define it
noDataValue <- as.numeric(reflInfo$Data_Ignore_Value)
noDataValue
## [1] -9999
# set all values equal to the no data value (-9999) to NA
b34[b34 == noDataValue] <- NA
# plot the image now
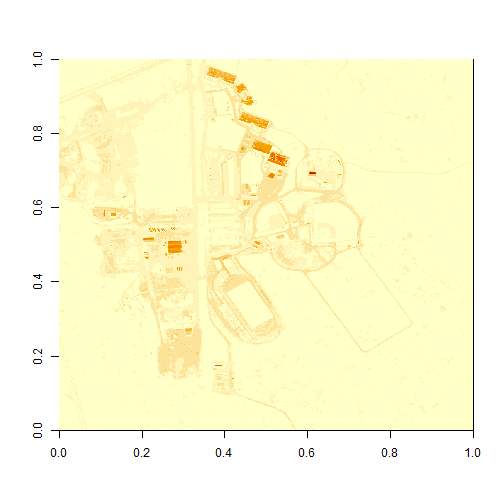
image(b34)
Reflectance Values and Image Stretch
Our image still looks dark because R is trying to render all reflectance values between 0 and 14999 as if they were distributed equally in the histogram. However we know they are not distributed equally. There are many more values between 0-5000 than there are values >5000.
Images contain a distribution of reflectance values. A typical image viewing program will render the values by distributing the entire range of reflectance values across a range of "shades" that the monitor can render - between 0 and 255. However, often the distribution of reflectance values is not linear. For example, in the case of our data, most of the reflectance values fall between 0 and 0.5. Yet there are a few values >0.8 that are heavily impacting the way the image is drawn on our monitor. Imaging processing programs like ENVI, QGIS and ArcGIS (and even Adobe Photoshop) allow you to adjust the stretch of the image. This is similar to adjusting the contrast and brightness in Photoshop.
The proper way to adjust our data would be to apply what's called an image stretch. We will learn how to stretch our image data later. For now, let's plot the values as the log function on the pixel reflectance values to factor out those larger values.
image(log(b34))

The log applied to our image increases the contrast making it look more like an image. However, look at the images below. The top one is an RGB image as the image should look. The bottom one is our log-adjusted image. Notice a difference?


Transpose Image
Notice that there are three data dimensions for this file: Bands x Rows x Columns. However, when R reads in the dataset, it reads them as: Columns x Bands x Rows. The data are flipped. We can quickly transpose the data to correct for this using the t or transpose command in R.
The orientation is rotated in our log adjusted image. This is because R reads in matrices starting from the upper left hand corner. While most rasters read pixels starting from the lower left hand corner. In the next section, we will deal with this issue by creating a proper georeferenced (spatially located) raster in R. The raster format will read in pixels following the same methods as other GIS and imaging processing software like QGIS and ENVI do.
# We need to transpose x and y values in order for our
# final image to plot properly
b34 <- t(b34)
image(log(b34), main="Transposed Image")

Create a Georeferenced Raster
Next, we will create a proper raster using the b34 matrix. The raster format will allow us to define and manage:
- Image stretch
- Coordinate reference system & spatial reference
- Resolution
- and other raster attributes...
It will also account for the orientation issue discussed above.
To create a raster in R, we need a few pieces of information, including:
- The coordinate reference system (CRS)
- The spatial extent of the image
Define Raster CRS
First, we need to define the Coordinate reference system (CRS) of the raster. To do that, we can first grab the EPSG code from the HDF5 attributes, and covert the EPSG to a CRS string. Then we can assign that CRS to the raster object.
# Extract the EPSG from the h5 dataset
h5EPSG <- h5read(h5_file, "/SJER/Reflectance/Metadata/Coordinate_System/EPSG Code")
# convert the EPSG code to a CRS string
h5CRS <- crs(paste0("+init=epsg:",h5EPSG))
# define final raster with projection info
# note that capitalization will throw errors on a MAC.
# if UTM is all caps it might cause an error!
b34r <- rast(b34,
crs=h5CRS)
# view the raster attributes
b34r
## class : SpatRaster
## size : 1000, 1000, 1 (nrow, ncol, nlyr)
## resolution : 1, 1 (x, y)
## extent : 0, 1000, 0, 1000 (xmin, xmax, ymin, ymax)
## coord. ref. : WGS 84 / UTM zone 11N
## source(s) : memory
## name : lyr.1
## min value : 32
## max value : 13129
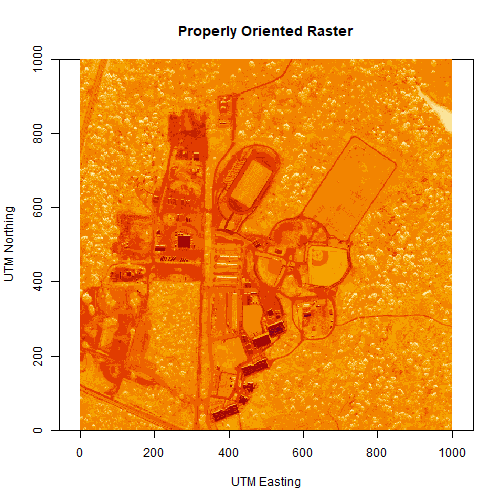
# let's have a look at our properly oriented raster. Take note of the
# coordinates on the x and y axis.
image(log(b34r),
xlab = "UTM Easting",
ylab = "UTM Northing",
main = "Properly Oriented Raster")
Next we define the extents of our raster. The extents will be used to calculate the raster's resolution. Fortunately, the spatial extent is provided in the HDF5 file "Reflectance_Data" group attributes that we saved before as reflInfo.
# Grab the UTM coordinates of the spatial extent
xMin <- reflInfo$Spatial_Extent_meters[1]
xMax <- reflInfo$Spatial_Extent_meters[2]
yMin <- reflInfo$Spatial_Extent_meters[3]
yMax <- reflInfo$Spatial_Extent_meters[4]
# define the extent (left, right, top, bottom)
rasExt <- ext(xMin,xMax,yMin,yMax)
rasExt
## SpatExtent : 257000, 258000, 4112000, 4113000 (xmin, xmax, ymin, ymax)
# assign the spatial extent to the raster
ext(b34r) <- rasExt
# look at raster attributes
b34r
## class : SpatRaster
## size : 1000, 1000, 1 (nrow, ncol, nlyr)
## resolution : 1, 1 (x, y)
## extent : 257000, 258000, 4112000, 4113000 (xmin, xmax, ymin, ymax)
## coord. ref. : WGS 84 / UTM zone 11N
## source(s) : memory
## name : lyr.1
## min value : 32
## max value : 13129
Learn more about working with Raster data in R in the Data Carpentry workshop: Introduction to Geospatial Raster and Vector Data with R.
We can adjust the colors of our raster as well, if desired.
# let's change the colors of our raster and adjust the zlim
col <- terrain.colors(25)
image(b34r,
xlab = "UTM Easting",
ylab = "UTM Northing",
main= "Spatially Referenced Raster",
col=col,
zlim=c(0,3000))
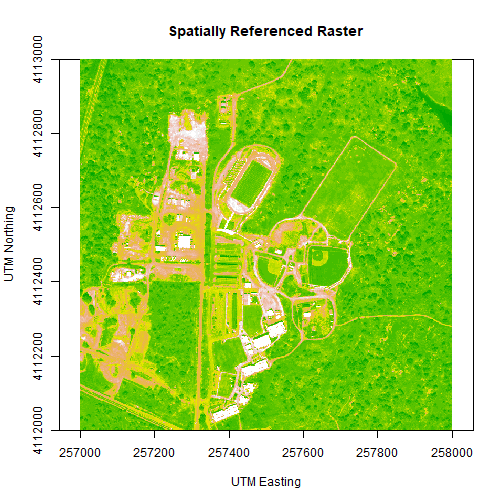
We've now created a raster from band 34 reflectance data. We can export the data as a raster, using the writeRaster command. Note that it's good practice to close the H5 connection before moving on!
# write out the raster as a geotiff
writeRaster(b34r,
file=paste0(data_dir,"band34.tif"),
overwrite=TRUE)
# close the H5 file
H5close()
Challenge: Work with Rasters
Try these three extensions on your own:
-
Create rasters using other bands in the dataset.
-
Vary the distribution of values in the image to mimic an image stretch. e.g.
b34[b34 > 6000 ] <- 6000 -
Use what you know to extract ALL of the reflectance values for ONE pixel rather than for an entire band. HINT: this will require you to pick an x and y value and then all values in the z dimension:
aPixel<- h5read(h5_file,"Reflectance",index=list(NULL,100,35)). Plot the spectra output.