This tutorial goes over how to use the neonUtilities R package
(formerly the neonDataStackR package).
The package contains several functions:
stackByTable(): Takes zip files downloaded from the
Data Portal or
downloaded by zipsByProduct(), unzips them, and joins
the monthly files by data table to create a single file per table.
zipsByProduct(): A wrapper for the
NEON API;
downloads data based on data product and site criteria. Stores
downloaded data in a format that can then be joined by
stackByTable().
loadByProduct(): Combines the functionality of zipsByProduct() and
stackByTable(): Downloads the specified data, stacks the files, and
loads the files to the R environment.
getPackage(): A wrapper for the NEON API; downloads one
site-by-month zip file at a time.
byFileAOP(): A wrapper for the NEON API; downloads remote
sensing data based on data product, site, and year criteria.
Preserves the file structure of the original data.
byTileAOP(): Downloads remote sensing data for the specified
data product, subset to tiles that intersect a list of
coordinates.
readTableNEON(): Reads NEON data tables into R, using the
variables file to assign R classes to each column.
transformFileToGeoCSV(): Converts any NEON data file in
csv format into a new file with GeoCSV headers.
If you are only interested in joining data
files downloaded from the NEON Data Portal, you will only need to use
`stackByTable()`. Follow the instructions in the first section of the
Download and Explore
tutorial.
neonUtilities package
This package is intended to provide a toolbox of basic functionality
for working with NEON data. It currently contains the functions
listed above, but it is under development and more will be added in
the future. To report bugs or request new features, post an issue in the GitHub
repo
issues page.
If you are already familiar with the neonUtilities package, and need a
quick reference guide to function inputs and notation, see the
neonUtilities cheat sheet.
First, we must install and load the neonUtilities package.
# install neonUtilities - can skip if already installed
install.packages("neonUtilities")
# load neonUtilities
library(neonUtilities)
Download files and load directly to R: loadByProduct()
The most popular function in neonUtilities is loadByProduct().
This function downloads data from the NEON API, merges the site-by-month
files, and loads the resulting data tables into the R environment,
assigning each data type to the appropriate R class. It combines the
actions of the zipsByProduct(), stackByTable(), and readTableNEON()
functions, described below.
This is a popular choice because it ensures you're always working with the
latest data, and it ends with ready-to-use tables in R. However, if you
use it in a workflow you run repeatedly, keep in mind it will re-download
the data every time.
loadByProduct() works on most observational (OS) and sensor (IS) data,
but not on surface-atmosphere exchange (SAE) data, remote sensing (AOP)
data, and some of the data tables in the microbial data products. For
functions that download AOP data, see the byFileAOP() and byTileAOP()
sections in this tutorial. For functions that work with SAE data, see
the NEON eddy flux data tutorial.
The inputs to loadByProduct() control which data to download and how
to manage the processing:
dpID: the data product ID, e.g. DP1.00002.001
site: defaults to "all", meaning all sites with available data;
can be a vector of 4-letter NEON site codes, e.g.
c("HARV","CPER","ABBY").
startdate and enddate: defaults to NA, meaning all dates
with available data; or a date in the form YYYY-MM, e.g.
2017-06. Since NEON data are provided in month packages, finer
scale querying is not available. Both start and end date are
inclusive.
package: either basic or expanded data package. Expanded data
packages generally include additional information about data
quality, such as chemical standards and quality flags. Not every
data product has an expanded package; if the expanded package is
requested but there isn't one, the basic package will be
downloaded.
avg: defaults to "all", to download all data; or the
number of minutes in the averaging interval. See example below;
only applicable to IS data.
savepath: the file path you want to download to; defaults to the
working directory.
check.size: T or F: should the function pause before downloading
data and warn you about the size of your download? Defaults to T; if
you are using this function within a script or batch process you
will want to set it to F.
nCores: Number of cores to use for parallel processing. Defaults
to 1, i.e. no parallelization.
The dpID is the data product identifier of the data you want to
download. The DPID can be found on the
Explore Data Products page.
It will be in the form DP#.#####.###
Let's get triple-aspirated air temperature data (DP1.00003.001)
from Moab and Onaqui (MOAB and ONAQ), from May--August 2018, and
name the data object trip.temp:
trip.temp <- loadByProduct(dpID="DP1.00003.001",
site=c("MOAB","ONAQ"),
startdate="2018-05",
enddate="2018-08")
Continuing will download files totaling approximately 7.994569 MB. Do you want to proceed y/n: y
Downloading 8 files
|========================================================================================================| 100%
Unpacking zip files using 1 cores.
|++++++++++++++++++++++++++++++++++++++++++++++++++| 100% elapsed=00s
|++++++++++++++++++++++++++++++++++++++++++++++++++| 100% elapsed=00s
Stacking operation across a single core.
Stacking table TAAT_1min
|++++++++++++++++++++++++++++++++++++++++++++++++++| 100% elapsed=00s
Stacking table TAAT_30min
|++++++++++++++++++++++++++++++++++++++++++++++++++| 100% elapsed=00s
Merged the most recent publication of sensor position files for each site and saved to /stackedFiles
Copied the most recent publication of variable definition file to /stackedFiles
Finished: Stacked 2 data tables and 2 metadata tables!
Stacking took 0.8517601 secs
The object returned by loadByProduct() is a named list of data
frames. To work with each of them, select them from the list
using the $ operator.
names(trip.temp)
View(trip.temp$TAAT_30min)
If you prefer to extract each table from the list and work
with it as an independent object, you can use the
list2env() function:
list2env(trip.temp, .GlobalEnv)
For more details about the contents of the data tables and metadata tables,
check out the Download and Explore
tutorial.
If you want to be able to close R and come back to these data without
re-downloading, you'll want to save the tables locally. We recommend
also saving the variables file, both so you'll have it to refer to, and
so you can use it with readTableNEON() (see below).
But, if you want to save files locally and load them into R (or another
platform) each time you run a script, instead of downloading from the API
every time, you may prefer to use zipsByProduct() and stackByTable()
instead of loadByProduct().
Join data files: stackByTable()
The function stackByTable() joins the month-by-site files from a data
download. The output will yield data grouped into new files by table name.
For example, the single aspirated air temperature data product contains 1
minute and 30 minute interval data. The output from this function is one
.csv with 1 minute data and one .csv with 30 minute data.
Depending on your file size this function may run for a while. For
example, in testing for this tutorial, 124 MB of temperature data took
about 4 minutes to stack. A progress bar will display while the
stacking is in progress.
Download the Data
To stack data from the Portal, first download the data of interest from the
NEON Data Portal.
To stack data downloaded from the API, see the zipsByProduct() section
below.
Your data will download from the Portal in a single zipped file.
The stacking function will only work on zipped Comma Separated Value (.csv)
files and not the NEON data stored in other formats (HDF5, etc).
Run stackByTable()
The example data below are single-aspirated air temperature.
To run the stackByTable() function, input the file path to the
downloaded and zipped file.
# stack files - Mac OSX file path shown
stackByTable(filepath="~neon/data/NEON_temp-air-single.zip")
Unpacking zip files
|=========================================================================================| 100%
Stacking table SAAT_1min
|=========================================================================================| 100%
Stacking table SAAT_30min
|=========================================================================================| 100%
Finished: All of the data are stacked into 2 tables!
Copied the first available variable definition file to /stackedFiles and renamed as variables.csv
Stacked SAAT_1min which has 424800 out of the expected 424800 rows (100%).
Stacked SAAT_30min which has 14160 out of the expected 14160 rows (100%).
Stacking took 6.233922 secs
All unzipped monthly data folders have been removed.
From the single-aspirated air temperature data we are given two final tables.
One with 1 minute intervals: SAAT_1min and one for 30 minute intervals:
SAAT_30min.
In the same directory as the zipped file, you should now have an unzipped
directory of the same name. When you open this you will see a new directory
called stackedFiles. This directory contains one or more .csv files
(depends on the data product you are working with) with all the data from
the months & sites you downloaded. There will also be a single copy of the
associated variables, validation, and sensor_positions files, if applicable
(validation files are only available for observational data products, and
sensor position files are only available for instrument data products).
These .csv files are now ready for use with the program of your choice.
To read the data tables into R, we recommend using readTableNEON(),
which will assign each column to the relevant R class, based on the
metadata in the variables file. This ensures time stamps and missing
data are interpreted correctly in R.
The function zipsByProduct() is a wrapper for the NEON API, it
downloads zip files for the data product specified and stores them in
a format that can then be passed on to stackByTable().
Input options for zipsByProduct() are the same as those for
loadByProduct() described above, except for nCores.
Here, we'll download single-aspirated air temperature (DP1.00002.001)
data from Wind River Experimental Forest (WREF) for April and May of
2019.
zipsByProduct(dpID="DP1.00002.001", site="WREF",
startdate="2019-04", enddate="2019-05",
package="basic", check.size=T)
Continuing will download files totaling approximately 12.750557 MB. Do you want to proceed y/n: y
Downloading 2 files
|========================================================================================================| 100%
2 files downloaded to /Users/neon/filesToStack00002
Downloaded files can now be passed to stackByTable() to be
stacked.
For many sensor data products, download sizes can get
very large, and stackByTable() takes a long time. The
1-minute or 2-minute files are much larger than the
longer averaging intervals, so if you don't need high-
frequency data, the avg input option lets you choose
which averaging interval to download.
This option is only applicable to sensor (IS) data,
since OS data are not averaged.
Download only the 30-minute data for single-aspirated
air temperature at WREF:
zipsByProduct(dpID="DP1.00002.001", site="WREF",
startdate="2019-04", enddate="2019-05",
package="basic", avg=30, check.size=T)
Continuing will download files totaling approximately 2.101936 MB. Do you want to proceed y/n: y
Downloading 17 files
|========================================================================================================| 100%
17 files downloaded to /Users/neon/filesToStack00002
The 30-minute files can be stacked as usual, and can
be read into R using readTableNEON():
If you only need a single site-month (e.g., to test code
you're writing), the getPackage() function can be used to
download a single zip file. Here we'll download the
November 2017 temperature data from HARV.
The file should now be saved to your working directory.
Download remote sensing files: byFileAOP()
Remote sensing data files can be very large, and NEON remote sensing
(AOP) data are stored in a directory structure that makes them easier
to navigate. byFileAOP() downloads AOP files from the API while
preserving their directory structure. This provides a convenient way
to access AOP data programmatically.
Be aware that downloads from byFileAOP() can take a VERY long time,
depending on the data you request and your connection speed. You
may need to run the function and then leave your machine on and
downloading for an extended period of time.
Here the example download is the Ecosystem Structure data product at
Hop Brook (HOPB) in 2017; we use this as the example because it's a
relatively small year-site-product combination.
byFileAOP("DP3.30015.001", site="HOPB",
year="2017", check.size=T)
Continuing will download 36 files totaling approximately 140.3 MB . Do you want to proceed y/n: y
trying URL 'https://neon-aop-product.s3.data.neonscience.org:443/2017/FullSite/D01/2017_HOPB_2/L3/DiscreteLidar/CanopyHeightModelGtif/NEON_D01_HOPB_DP3_716000_4704000_CHM.tif?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20180410T233031Z&X-Amz-SignedHeaders=host&X-Amz-Expires=3599&X-Amz-Credential=pub-internal-read%2F20180410%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Signature=92833ebd10218f4e2440cb5ea78d1c8beac4ee4c10be5c6aeefb72d18cf6bd78'
Content type 'application/octet-stream' length 4009489 bytes (3.8 MB)
==================================================
downloaded 3.8 MB
(Further URLs omitted for space. Function returns a message
for each URL it attempts to download from)
Successfully downloaded 36 files.
NEON_D01_HOPB_DP3_716000_4704000_CHM.tif downloaded to /Users/neon/DP3.30015.001/2017/FullSite/D01/2017_HOPB_2/L3/DiscreteLidar/CanopyHeightModelGtif
NEON_D01_HOPB_DP3_716000_4705000_CHM.tif downloaded to /Users/neon/DP3.30015.001/2017/FullSite/D01/2017_HOPB_2/L3/DiscreteLidar/CanopyHeightModelGtif
(Further messages omitted for space.)
The files should now be downloaded to a new folder in your
working directory.
Download remote sensing files for specific coordinates: byTileAOP()
Often when using remote sensing data, we only want data covering a
certain area - usually the area where we have coordinated ground
sampling. byTileAOP() queries for data tiles containing a
specified list of coordinates. It only works for the tiled, AKA
mosaicked, versions of the remote sensing data, i.e. the ones with
data product IDs beginning with "DP3".
Here, we'll download tiles of vegetation indices data (DP3.30026.001)
corresponding to select observational sampling plots. For more information
about accessing NEON spatial data, see the
API tutorial and the in-development
geoNEON package.
For now, assume we've used the API to look up the plot centroids of
plots SOAP_009 and SOAP_011 at the Soaproot Saddle site. You can
also look these up in the Spatial Data folder of the
document library.
The coordinates of the two plots in UTMs are 298755,4101405 and
299296,4101461. These are 40x40m plots, so in looking for tiles
that contain the plots, we want to include a 20m buffer. The
"buffer" is actually a square, it's a delta applied equally to
both the easting and northing coordinates.
byTileAOP(dpID="DP3.30026.001", site="SOAP",
year="2018", easting=c(298755,299296),
northing=c(4101405,4101461),
buffer=20)
trying URL 'https://neon-aop-product.s3.data.neonscience.org:443/2018/FullSite/D17/2018_SOAP_3/L3/Spectrometer/VegIndices/NEON_D17_SOAP_DP3_299000_4101000_VegIndices.zip?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20190313T225238Z&X-Amz-SignedHeaders=host&X-Amz-Expires=3600&X-Amz-Credential=pub-internal-read%2F20190313%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Signature=e9ae6858242b48df0677457e31ea3d86b2f20ac2cf43d5fc02847bbaf2e1da47'
Content type 'application/octet-stream' length 47798759 bytes (45.6 MB)
==================================================
downloaded 45.6 MB
(Further URLs omitted for space. Function returns a message
for each URL it attempts to download from)
Successfully downloaded 2 files.
NEON_D17_SOAP_DP3_298000_4101000_VegIndices.zip downloaded to /Users/neon/DP3.30026.001/2018/FullSite/D17/2018_SOAP_3/L3/Spectrometer/VegIndices
NEON_D17_SOAP_DP3_299000_4101000_VegIndices.zip downloaded to /Users/neon/DP3.30026.001/2018/FullSite/D17/2018_SOAP_3/L3/Spectrometer/VegIndices
The 2 tiles covering the SOAP_009 and SOAP_011 plots have
been downloaded.
Convert files to GeoCSV: transformFileToGeoCSV()
transformFileToGeoCSV() takes a NEON csv file, plus its
corresponding variables file, and writes out a new version of the
file with
GeoCSV
headers. This allows for compatibility with data
provided by
UNAVCO
and other facilities.
Inputs to transformFileToGeoCSV() are the file path to the data
file, the file path to the variables file, and the file path where
you want to write out the new version. It works on both single
site-month files and on stacked files.
In this example, we'll convert the November 2017 temperature data
from HARV that we downloaded with getPackage() earlier. First,
you'll need to unzip the file so you can get to the data files.
Then we'll select the file for the tower top, which we can
identify by the 050 in the VER field (see the
file naming conventions
page for more information).
This tutorial discusses ways to plot plant phenology (discrete time
series) and single-aspirated temperature (continuous time series) together.
It uses data frames created in the first two parts of this series,
Work with NEON OS & IS Data - Plant Phenology & Temperature.
If you have not completed these tutorials, please download the dataset below.
Objectives
After completing this tutorial, you will be able to:
plot multiple figures together with grid.arrange()
plot only a subset of dates
Things You’ll Need To Complete This Tutorial
You will need the most current version of R and, preferably, RStudio loaded
on your computer to complete this tutorial.
This tutorial is designed to have you download data directly from the NEON
portal API using the neonUtilities package. However, you can also directly
download this data, prepackaged, from FigShare. This data set includes all the
files needed for the Work with NEON OS & IS Data - Plant Phenology & Temperature
tutorial series. The data are in the format you would receive if downloading them
using the zipsByProduct() function in the neonUtilities package.
To start, we need to set up our R environment. If you're continuing from the
previous tutorial in this series, you'll only need to load the new packages.
# Install needed package (only uncomment & run if not already installed)
#install.packages("dplyr")
#install.packages("ggplot2")
#install.packages("scales")
# Load required libraries
library(ggplot2)
library(dplyr)
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
library(gridExtra)
##
## Attaching package: 'gridExtra'
## The following object is masked from 'package:dplyr':
##
## combine
library(scales)
options(stringsAsFactors=F) #keep strings as character type not factors
# set working directory to ensure R can find the file we wish to import and where
# we want to save our files. Be sure to move the download into your working directory!
wd <- "~/Documents/data/" # Change this to match your local environment
setwd(wd)
If you don't already have the R objects, temp_day and phe_1sp_2018, loaded
you'll need to load and format those data. If you do, you can skip this code.
# Read in data -> if in series this is unnecessary
temp_day <- read.csv(paste0(wd,'NEON-pheno-temp-timeseries/NEONsaat_daily_SCBI_2018.csv'))
phe_1sp_2018 <- read.csv(paste0(wd,'NEON-pheno-temp-timeseries/NEONpheno_LITU_Leaves_SCBI_2018.csv'))
# Convert dates
temp_day$Date <- as.Date(temp_day$Date)
# use dateStat - the date the phenophase status was recorded
phe_1sp_2018$dateStat <- as.Date(phe_1sp_2018$dateStat)
Separate Plots, Same Panel
In this dataset, we have phenology and temperature data from the Smithsonian
Conservation Biology Institute (SCBI) NEON field site. There are a variety of ways
we may want to look at this data, including aggregated at the site level, by
a single plot, or viewing all plots at the same time but in separate plots. In
the Work With NEON's Plant Phenology Data and the
Work with NEON's Single-Aspirated Air Temperature Data tutorials, we created
separate plots of the number of individuals who had leaves at different times
of the year and the temperature in 2018.
However, plot the data next to each other to aid comparisons. The grid.arrange()
function from the gridExtra package can help us do this.
# first, create one plot
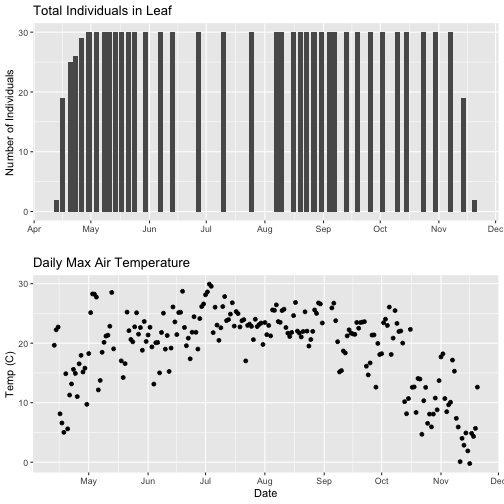
phenoPlot <- ggplot(phe_1sp_2018, aes(dateStat, countYes)) +
geom_bar(stat="identity", na.rm = TRUE) +
ggtitle("Total Individuals in Leaf") +
xlab("") + ylab("Number of Individuals")
# create second plot of interest
tempPlot_dayMax <- ggplot(temp_day, aes(Date, dayMax)) +
geom_point() +
ggtitle("Daily Max Air Temperature") +
xlab("Date") + ylab("Temp (C)")
# Then arrange the plots - this can be done with >2 plots as well.
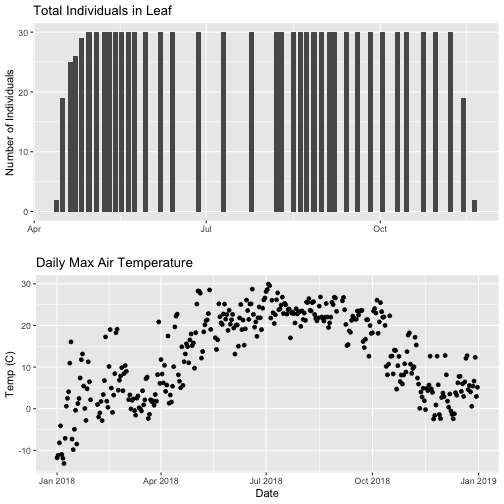
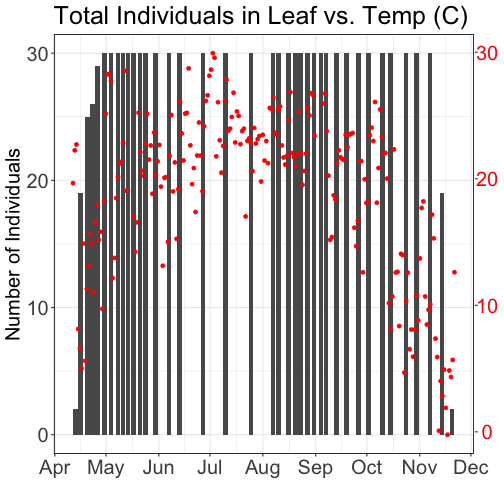
grid.arrange(phenoPlot, tempPlot_dayMax)
Now, we can see both plots in the same window. But, hmmm... the x-axis on both
plots is kinda wonky. We want the same spacing in the scale across the year (e.g.,
July in one should line up with July in the other) plus we want the dates to
display in the same format(e.g. 2016-07 vs. Jul vs Jul 2018).
Format Dates in Axis Labels
The date format parameter can be adjusted with scale_x_date. Let's format the x-axis
ticks so they read "month" (%b) in both graphs. We will use the syntax:
scale_x_date(labels=date_format("%b"")
Rather than re-coding the entire plot, we can add the scale_x_date element
to the plot object phenoPlot we just created.
**Data Tip:**
You can type ?strptime into the R
console to find a list of date format conversion specifications (e.g. %b = month).
Type scale_x_date for a list of parameters that allow you to format dates
on the x-axis.
If you are working with a date & time
class (e.g. POSIXct), you can use scale_x_datetime instead of scale_x_date.
But this only solves one of the problems, we still have a different range on the
x-axis which makes it harder to see trends.
Align data sets with different start dates
Now let's work to align the values on the x-axis. We can do this in two ways,
setting the x-axis to have the same date range or 2) by filtering the dataset
itself to only include the overlapping data. Depending on what you are trying to
demonstrate and if you're doing additional analyses and want only the overlapping
data, you may prefer one over the other. Let's try both.
Set range of x-axis
Alternatively, we can set the x-axis range for both plots by adding the limits
parameter to the scale_x_date() function.
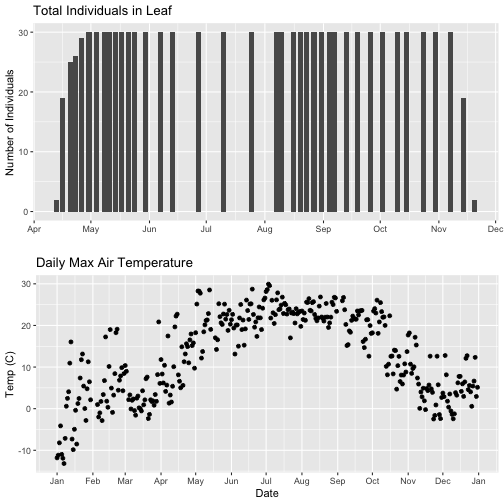
# first, lets recreate the full plot and add in the
phenoPlot_setX <- ggplot(phe_1sp_2018, aes(dateStat, countYes)) +
geom_bar(stat="identity", na.rm = TRUE) +
ggtitle("Total Individuals in Leaf") +
xlab("") + ylab("Number of Individuals") +
scale_x_date(breaks = date_breaks("1 month"),
labels = date_format("%b"),
limits = as.Date(c('2018-01-01','2018-12-31')))
# create second plot of interest
tempPlot_dayMax_setX <- ggplot(temp_day, aes(Date, dayMax)) +
geom_point() +
ggtitle("Daily Max Air Temperature") +
xlab("Date") + ylab("Temp (C)") +
scale_x_date(date_breaks = "1 month",
labels=date_format("%b"),
limits = as.Date(c('2018-01-01','2018-12-31')))
# Plot
grid.arrange(phenoPlot_setX, tempPlot_dayMax_setX)
Now we can really see the pattern over the full year. This emphasizes the point
that during much of the late fall, winter, and early spring none of the trees
have leaves on them (or that data were not collected - this plot would not
distinguish between the two).
Subset one data set to match other
Alternatively, we can simply filter the dataset with the larger date range so
the we only plot the data from the overlapping dates.
# filter to only having overlapping data
temp_day_filt <- filter(temp_day, Date >= min(phe_1sp_2018$dateStat) &
Date <= max(phe_1sp_2018$dateStat))
# Check
range(phe_1sp_2018$date)
## [1] "2018-04-13" "2018-11-20"
range(temp_day_filt$Date)
## [1] "2018-04-13" "2018-11-20"
#plot again
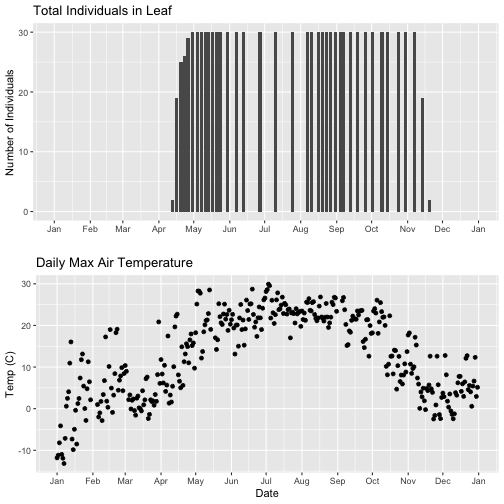
tempPlot_dayMaxFiltered <- ggplot(temp_day_filt, aes(Date, dayMax)) +
geom_point() +
scale_x_date(breaks = date_breaks("months"), labels = date_format("%b")) +
ggtitle("Daily Max Air Temperature") +
xlab("Date") + ylab("Temp (C)")
grid.arrange(phenoPlot, tempPlot_dayMaxFiltered)
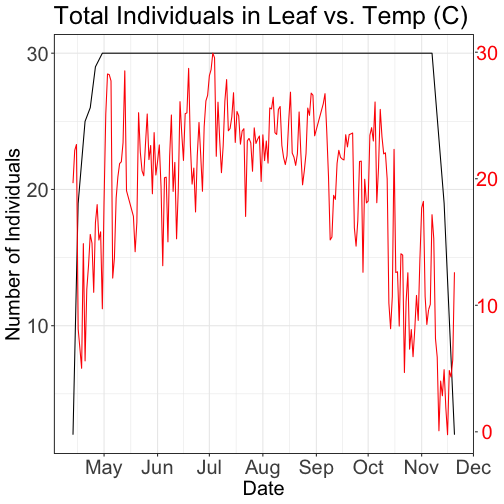
With this plot, we really look at the area of overlap in the plotted data (but
this does cut out the time where the data are collected but not plotted).
Same plot with two Y-axes
What about layering these plots and having two y-axes (right and left) that have
the different scale bars?
Some argue that you should not do this as it can distort what is actually going
on with the data. The author of the ggplot2 package is one of these individuals.
Therefore, you cannot use ggplot() to create a single plot with multiple y-axis
scales. You can read his own discussion of the topic on this
StackOverflow post.
However, individuals have found work arounds for these plots. The code below
is provided as a demonstration of this capability. Note, by showing this code
here, we don't necessarily endorse having plots with two y-axes.
In this tutorial, we explore the NEON single-aspirated air temperature data.
We then discuss how to interpret the variables, how to work with date-time and
date formats, and finally how to plot the data.
This tutorial is part of a series on how to work with both discrete and continuous
time series data with NEON plant phenology and temperature data products.
Objectives
After completing this activity, you will be able to:
work with "stacked" NEON Single-Aspirated Air Temperature data.
correctly format date-time data.
use dplyr functions to filter data.
plot time series data in scatter plots using ggplot function.
Things You’ll Need To Complete This Tutorial
You will need the most current version of R and, preferably, RStudio loaded
on your computer to complete this tutorial.
Background Information About NEON Air Temperature Data
Air temperature is continuously monitored by NEON by two methods. At terrestrial
sites temperature at the top of the tower is derived from a triple
redundant aspirated air temperature sensor. This is provided as NEON data
product DP1.00003.001. Single Aspirated Air Temperature sensors (SAAT) are
deployed to develop temperature profiles at multiple levels on the tower at NEON
terrestrial sites and on the meteorological stations at NEON aquatic sites. This
is provided as NEON data product DP1.00002.001.
When designing a research project using this data, consult the
Data Product Details Page
for more detailed documentation.
Single-aspirated Air Temperature
Air temperature profiles are ascertained by deploying SAATs at various heights
on NEON tower infrastructure. Air temperature at aquatic sites is measured
using a single SAAT at a standard height of 3m above ground level. Air temperature
for this data product is provided as one- and thirty-minute averages of 1 Hz
observations. Temperature observations are made using platinum resistance
thermometers, which are housed in a fan aspirated shield to reduce radiative
heating. The temperature is measured in Ohms and subsequently converted to degrees
Celsius during data processing. Details on the conversion can be found in the
associated Algorithm Theoretic Basis Document (ATBD; see Product Details page
linked above).
Available Data Tables
The SAAT data product contains two data tables for each site and month selected,
consisting of the 1-minute and 30-minute averaging intervals. In addition, there
are several metadata files that provide additional useful information.
readme with information on the data product and the download
variables file that defines the terms, data types, and units
EML file with machine readable metadata in standardized Ecological Metadata Language
Access NEON Data
There are several ways to access NEON data, directly from the NEON data portal,
access through a data partner (select data products only), writing code to
directly pull data from the NEON API, or, as we'll do here, using the neonUtilities
package which is a wrapper for the API to make working with the data easier.
Downloading from the Data Portal
If you prefer to download data from the data portal, please
review the Getting started and Stack the downloaded data sections of the
Download and Explore NEON Data tutorial.
This will get you to the point where you can download data from sites or dates
of interest and resume this tutorial.
Downloading Data Using neonUtilities
First, we need to set up our environment with the packages needed for this tutorial.
# Install needed package (only uncomment & run if not already installed)
#install.packages("neonUtilities")
#install.packages("ggplot2")
#install.packages("dplyr")
#install.packages("tidyr")
# Load required libraries
library(neonUtilities) # for accessing NEON data
library(ggplot2) # for plotting
library(dplyr) # for data munging
library(tidyr) # for data munging
# set working directory
# this step is optional, only needed if you plan to save the
# data files at the end of the tutorial
wd <- "~/data" # enter your working directory here
setwd(wd)
This tutorial is part of series working with discrete plant phenology data and
(nearly) continuous temperature data. Our overall "research" question is to see if
there is any correlation between plant phenology and temperature.
Therefore, we will want to work with data that
align with the plant phenology data that we worked with in the first tutorial.
If you are only interested in working with the temperature data, you do not need
to complete the previous tutorial.
Our data of interest will be the temperature data from 2018 from NEON's
Smithsonian Conservation Biology Institute (SCBI) field site located in Virginia
near the northern terminus of the Blue Ridge Mountains.
NEON single aspirated air temperature data is available in two averaging intervals,
1 minute and 30 minute intervals. Which data you want to work with is going to
depend on your research questions. Here, we're going to only download and work
with the 30 minute interval data as we're primarily interest in longer term (daily,
weekly, annual) patterns.
This will download 7.7 MB of data. check.size is set to false (F) to improve flow
of the script but is always a good idea to view the size with true (T) before
downloading a new dataset.
# download data of interest - Single Aspirated Air Temperature
saat <- loadByProduct(dpID="DP1.00002.001", site="SCBI",
startdate="2018-01", enddate="2018-12",
package="basic", timeIndex="30",
check.size = F)
Explore Temperature Data
Now that you have the data, let's take a look at the structure and understand
what's in the data. The data (saat) come in as a large list of four items.
View(saat)
So what exactly are these five files and why would you want to use them?
data file(s): There will always be one or more dataframes that include the
primary data of the data product you downloaded. Since we downloaded only the 30
minute averaged data we only have one data table SAAT_30min.
readme_xxxxx: The readme file, with the corresponding 5 digits from the data
product number, provides you with important information relevant to the data
product and the specific instance of downloading the data.
sensor_positions_xxxxx: This table contains the spatial coordinates
of each sensor, relative to a reference location.
variables_xxxxx: This table contains all the variables found in the associated
data table(s). This includes full definitions, units, and rounding.
issueLog_xxxxx: This table contains records of any known issues with the
data product, such as sensor malfunctions.
scienceReviewFlags_xxxxx: This table may or may not be present. It contains
descriptions of adverse events that led to manual flagging of the data, and is
usually more detailed than the issue log. It only contains records relevant to
the sites and dates of data downloaded.
Since we want to work with the individual files, let's make the elements of the
list into independent objects.
The sensor data undergo a variety of automated quality assurance and quality control
checks. You can read about them in detail in the Quality Flags and Quality Metrics ATBD, in the Documentation section of the product details page.
The expanded data package
includes all of these quality flags, which can allow you to decide if not passing
one of the checks will significantly hamper your research and if you should
therefore remove the data from your analysis. Here, we're using the
basic data package, which only includes the final quality flag (finalQF),
which is aggregated from the full set of quality flags.
A pass of the check is 0, while a fail is 1. Let's see what percentage
of the data we downloaded passed the quality checks.
What should we do with the 23% of the data that are flagged?
This may depend on why it is flagged and what questions you are asking,
and the expanded data package would be useful for determining this.
For now, for demonstration purposes, we'll keep the flagged data.
What about null (NA) data?
sum(is.na(SAAT_30min$tempSingleMean))/nrow(SAAT_30min)
## [1] 0.2239269
mean(SAAT_30min$tempSingleMean)
## [1] NA
22% of the mean temperature values are NA. Note that this is not
additive with the flagged data! Empty data records are flagged, so this
indicates nearly all of the flagged data in our download are empty records.
Why was there no output from the calculation of mean temperature?
The R programming language, by default, won't calculate a mean (and many other
summary statistics) in data that contain NA values. We could override this
using the input parameter na.rm=TRUE in the mean() function, or just
remove the empty values from our analysis.
# create new dataframe without NAs
SAAT_30min_noNA <- SAAT_30min %>%
drop_na(tempSingleMean) # tidyr function
# alternate base R
# SAAT_30min_noNA <- SAAT_30min[!is.na(SAAT_30min$tempSingleMean),]
# did it work?
sum(is.na(SAAT_30min_noNA$tempSingleMean))
## [1] 0
Scatterplots with ggplot
We can use ggplot to create scatter plots. Which data should we plot, as we have
several options?
tempSingleMean: the mean temperature for the interval
tempSingleMinimum: the minimum temperature during the interval
tempSingleMaximum: the maximum temperature for the interval
Depending on exactly what question you are asking you may prefer to use one over
the other. For many applications, the mean temperature of the 1- or 30-minute
interval will provide the best representation of the data.
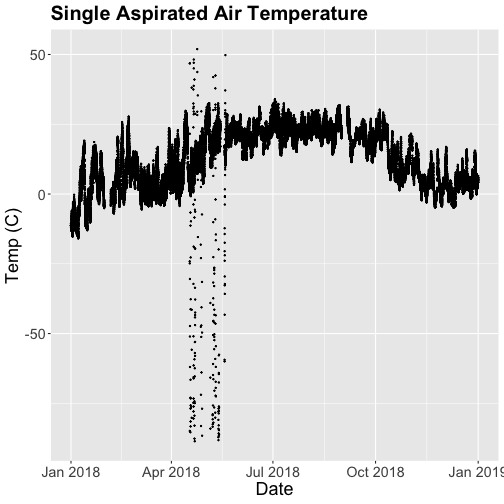
Let's plot it. (This is a plot of a large amount of data. It can take 1-2 mins
to process. It is not essential for completing the next steps if this takes too
much of your computer memory.)
Something odd seems to have happened in late April/May 2018. Since it is unlikely
Virginia experienced -50C during this time, these are probably erroneous sensor
readings and why we should probably remove data that are flagged with those quality
flags.
Right now we are also looking at all the data points in the dataset. However, we may
want to view or aggregate the data differently:
aggregated data: min, mean, or max over a some duration
the number of days since a freezing temperatures
or some other segregation of the data.
Given that in the previous tutorial,
Work With NEON's Plant Phenology Data,
we were working with phenology data collected on a daily scale let's aggregate
to that level.
To make this plot better, lets do two things
Remove flagged data
Aggregate to a daily mean.
Subset to remove quality flagged data
We already removed the empty records. Now we'll
subset the data to remove the remaining flagged data.
# subset and add C to name for "clean"
SAAT_30minC <- filter(SAAT_30min_noNA, SAAT_30min_noNA$finalQF==0)
# Do any quality flags remain?
sum(SAAT_30minC$finalQF==1)
## [1] 0
That looks better! But we're still working with the 30-minute data.
Aggregate Data by Day
We can use the dplyr package functions to aggregate the data. However, we have to
choose which data we want to aggregate. Again, you might want daily
minimum temps, mean temperature or maximum temps depending on your question.
In the context of phenology, minimum temperatures might be very important if you
are interested in a species that is very frost susceptible. Any days with a
minimum temperature below 0C could dramatically change the phenophase. For other
species or climates, maximum thresholds may be very important. Or you might be most
interested in the daily mean.
And note that you can combine different input values with different aggregation
functions - for example, you could calculate the minimum of the half-hourly
average temperature, or the average of the half-hourly maximum temperature.
For this tutorial, let's use maximum daily temperature, i.e. the maximum of the
tempSingleMax values for the day.
# convert to date, easier to work with
SAAT_30minC$Date <- as.Date(SAAT_30minC$startDateTime)
# max of mean temp each day
temp_day <- SAAT_30minC %>%
group_by(Date) %>%
distinct(Date, .keep_all=T) %>%
mutate(dayMax=max(tempSingleMaximum))
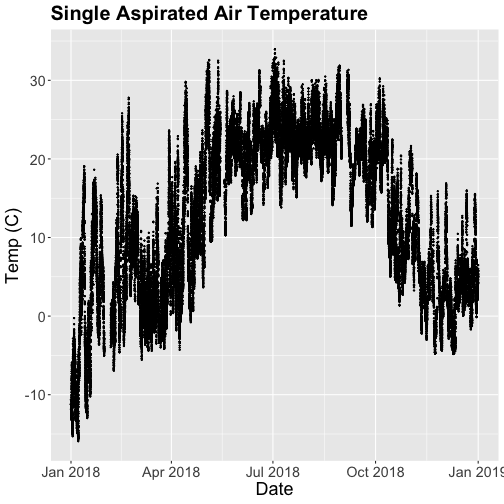
Now we can plot the cleaned up daily temperature.
# plot Air Temperature Data across 2018 using daily data
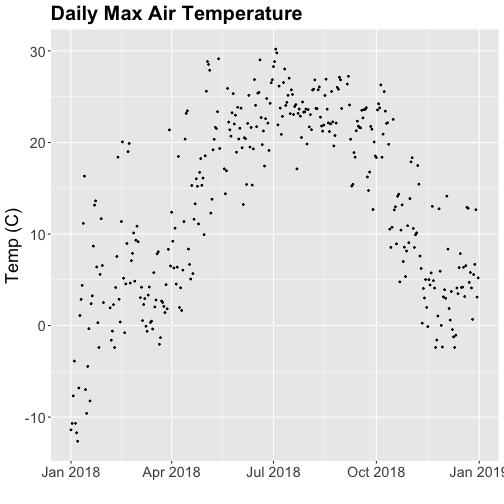
tempPlot_dayMax <- ggplot(temp_day, aes(Date, dayMax)) +
geom_point(size=0.5) +
ggtitle("Daily Max Air Temperature") +
xlab("") + ylab("Temp (C)") +
theme(plot.title = element_text(lineheight=.8, face="bold", size = 20)) +
theme(text = element_text(size=18))
tempPlot_dayMax
Thought questions:
What do we gain by this visualization?
What do we lose relative to the 30 minute intervals?
ggplot - Subset by Time
Sometimes we want to scale the x- or y-axis to a particular time subset without
subsetting the entire data_frame. To do this, we can define start and end
times. We can then define these limits in the scale_x_date object as
follows:
scale_x_date(limits=start.end) +
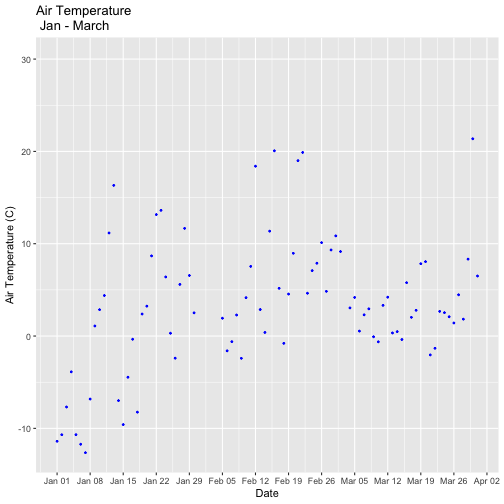
Let's plot just the first three months of the year.
# Define Start and end times for the subset as R objects that are the time class
startTime <- as.Date("2018-01-01")
endTime <- as.Date("2018-03-31")
# create a start and end time R object
start.end <- c(startTime,endTime)
str(start.end)
## Date[1:2], format: "2018-01-01" "2018-03-31"
# View data for first 3 months only
# And we'll add some color for a change.
tempPlot_dayMax3m <- ggplot(temp_day, aes(Date, dayMax)) +
geom_point(color="blue", size=0.5) +
ggtitle("Air Temperature\n Jan - March") +
xlab("Date") + ylab("Air Temperature (C)")+
(scale_x_date(limits=start.end,
date_breaks="1 week",
date_labels="%b %d"))
tempPlot_dayMax3m
## Warning: Removed 268 rows containing missing values (`geom_point()`).
Now we have the temperature data matching our Phenology data from the previous
tutorial, we want to save it to our computer to use in future analyses (or the
next tutorial). This is optional if you are continuing directly to the next tutorial
as you already have the data in R.
# Write .csv - this step is optional
# This will write to the working directory we set at the start of the tutorial
write.csv(temp_day , file="NEONsaat_daily_SCBI_2018.csv", row.names=F)
Many organisms, including plants, show patterns of change across seasons -
the different stages of this observable change are called phenophases. In this
tutorial we explore how to work with NEON plant phenophase data.
Objectives
After completing this activity, you will be able to:
work with NEON Plant Phenology Observation data.
use dplyr functions to filter data.
plot time series data in a bar plot using ggplot the function.
Things You’ll Need To Complete This Tutorial
You will need the most current version of R and, preferably, RStudio loaded
on your computer to complete this tutorial.
This tutorial is designed to have you download data directly from the NEON
portal API using the neonUtilities package. However, you can also directly
download this data, prepackaged, from FigShare. This data set includes all the
files needed for the Work with NEON OS & IS Data - Plant Phenology & Temperature
tutorial series. The data are in the format you would receive if downloading them
using the zipsByProduct() function in the neonUtilities package.
Plants change throughout the year - these are phenophases.
Why do they change?
Explore Phenology Data
The following sections provide a brief overview of the NEON plant phenology
observation data. When designing a research project using this data, you
need to consult the
documents associated with this data product and not rely solely on this summary.
The following description of the NEON Plant Phenology Observation data is modified
from the data product user guide.
NEON Plant Phenology Observation Data
NEON collects plant phenology data and provides it as NEON data product
DP1.10055.001.
The plant phenology observations data product provides in-situ observations of
the phenological status and intensity of tagged plants (or patches) during
discrete observations events.
Sampling occurs at all terrestrial field sites at site and season specific
intervals. During Phase I (dominant species) sampling (pre-2021), three species
with 30 individuals each are sampled. In 2021, Phase II (community) sampling
will begin, with <=20 species with 5 or more individuals sampled will occur.
Status-based Monitoring
NEON employs status-based monitoring, in which the phenological condition of an
individual is reported any time that individual is observed. At every observations
bout, records are generated for every phenophase that is occurring and for every
phenophase not occurring. With this approach, events (such as leaf emergence in
Mediterranean climates, or flowering in many desert species) that may occur
multiple times during a single year, can be captured. Continuous reporting of
phenophase status enables quantification of the duration of phenophases rather
than just their date of onset while allows enabling the explicit quantification
of uncertainty in phenophase transition dates that are introduced by monitoring
in discrete temporal bouts.
Specific products derived from this sampling include the observed phenophase
status (whether or not a phenophase is occurring) and the intensity of
phenophases for individuals in which phenophase status = ‘yes’. Phenophases
reported are derived from the USA National Phenology Network (USA-NPN) categories.
The number of phenophases observed varies by growth form and ranges from 1
phenophase (cactus) to 7 phenophases (semi-evergreen broadleaf).
In this tutorial we will focus only on the state of the phenophase, not the
phenophase intensity data.
Phenology Transects
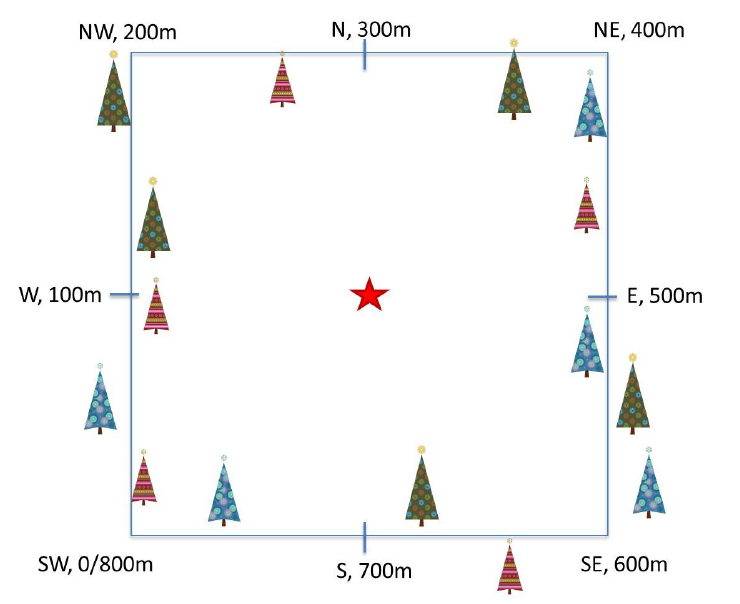
Plant phenology observations occurs at all terrestrial NEON sites along an 800
meter square loop transect (primary) and within a 200 m x 200 m plot located
within view of a canopy level, tower-mounted, phenology camera.
Diagram of a phenology transect layout, with meter layout marked.
Point-level geolocations are recorded at eight reference points along the
perimeter, plot-level geolocation at the plot centroid (star).
Source: National Ecological Observatory Network (NEON)
Timing of Observations
At each site, there are:
~50 observation bouts per year.
no more that 100 sampling points per phenology transect.
no more than 9 sampling points per phenocam plot.
1 annual measurement per year to collect annual size and disease status measurements from
each sampling point.
Available Data Tables
In the downloaded data packet, data are available in two main files
phe_statusintensity: Plant phenophase status and intensity data
phe_perindividual: Geolocation and taxonomic identification for phenology plants
phe_perindividualperyear: recorded once a year, essentially the "metadata"
about the plant: DBH, height, etc.
There are other files in each download including a readme with information on
the data product and the download; a variables file that defines the
term descriptions, data types, and units; a validation file with data entry
validation and parsing rules; and an XML with machine readable metadata.
Stack NEON Data
NEON data are delivered in a site and year-month format. When you download data,
you will get a single zipped file containing a directory for each month and site that you've
requested data for. Dealing with these separate tables from even one or two sites
over a 12 month period can be a bit overwhelming. Luckily NEON provides an R package
neonUtilities that takes the unzipped downloaded file and joining the data
files. The teaching data downloaded with this tutorial is already stacked. If you
are working with other NEON data, please go through the tutorial to stack the data
in
R or in Python
and then return to this tutorial.
Work with NEON Data
When we do this for phenology data we get three files, one for each data table,
with all the data from your site and date range of interest.
First, we need to set up our R environment.
# install needed package (only uncomment & run if not already installed)
#install.packages("neonUtilities")
#install.packages("dplyr")
#install.packages("ggplot2")
# load needed packages
library(neonUtilities)
library(dplyr)
library(ggplot2)
options(stringsAsFactors=F) #keep strings as character type not factors
# set working directory to ensure R can find the file we wish to import and where
# we want to save our files. Be sure to move the download into your working directory!
wd <- "~/Git/data/" # Change this to match your local environment
setwd(wd)
Let's start by loading our data of interest. For this series, we'll work with
date from the NEON Domain 02 sites:
Blandy Farm (BLAN)
Smithsonian Conservation Biology Institute (SCBI)
Smithsonian Environmental Research Center (SERC)
And we'll use data from January 2017 to December 2019. This downloads over 9MB
of data. If this is too large, use a smaller date range. If you opt to do this,
your figures and some output may look different later in the tutorial.
With this information, we can download our data using the neonUtilities package.
If you are not using a NEON token to download your data, remove the
token = Sys.getenv(NEON_TOKEN) line of code (learn more about NEON API tokens
in the
Using an API Token when Accessing NEON Data with neonUtilities tutorial).
If you are using the data downloaded at the start of the tutorial, use the
commented out code in the second half of this code chunk.
## Two options for accessing data - programmatic or from the example dataset
# Read data from data portal
phe <- loadByProduct(dpID = "DP1.10055.001", site=c("BLAN","SCBI","SERC"),
startdate = "2017-01", enddate="2019-12",
token = Sys.getenv("NEON_TOKEN"),
check.size = F)
## API token was not recognized. Public rate limit applied.
## Finding available files
##
# if you aren't sure you can handle the data file size use check.size = T.
# save dataframes from the downloaded list
ind <- phe$phe_perindividual #individual information
status <- phe$phe_statusintensity #status & intensity info
##If choosing to use example dataset downloaded from this tutorial:
# Stack multiple files within the downloaded phenology data
#stackByTable("NEON-pheno-temp-timeseries_v2/filesToStack10055", folder = T)
# read in data - readTableNEON uses the variables file to assign the correct
# data type for each variable
#ind <- readTableNEON('NEON-pheno-temp-timeseries_v2/filesToStack10055/stackedFiles/phe_perindividual.csv', 'NEON-pheno-temp-timeseries_v2/filesToStack10055/stackedFiles/variables_10055.csv')
#status <- readTableNEON('NEON-pheno-temp-timeseries_v2/filesToStack10055/stackedFiles/phe_statusintensity.csv', 'NEON-pheno-temp-timeseries_v2/filesToStack10055/stackedFiles/variables_10055.csv')
Let's explore the data. Let's get to know what the ind dataframe looks like.
# What are the fieldnames in this dataset?
names(ind)
## [1] "uid" "namedLocation"
## [3] "domainID" "siteID"
## [5] "plotID" "decimalLatitude"
## [7] "decimalLongitude" "geodeticDatum"
## [9] "coordinateUncertainty" "elevation"
## [11] "elevationUncertainty" "subtypeSpecification"
## [13] "transectMeter" "directionFromTransect"
## [15] "ninetyDegreeDistance" "sampleLatitude"
## [17] "sampleLongitude" "sampleGeodeticDatum"
## [19] "sampleCoordinateUncertainty" "sampleElevation"
## [21] "sampleElevationUncertainty" "date"
## [23] "editedDate" "individualID"
## [25] "taxonID" "scientificName"
## [27] "identificationQualifier" "taxonRank"
## [29] "nativeStatusCode" "growthForm"
## [31] "vstTag" "samplingProtocolVersion"
## [33] "measuredBy" "identifiedBy"
## [35] "recordedBy" "remarks"
## [37] "dataQF" "publicationDate"
## [39] "release"
# Unsure of what some of the variables are you? Look at the variables table!
View(phe$variables_10055)
# if using the pre-downloaded data, you need to read in the variables file
# or open and look at it on your desktop
#var <- read.csv('NEON-pheno-temp-timeseries_v2/filesToStack10055/stackedFiles/variables_10055.csv')
#View(var)
# how many rows are in the data?
nrow(ind)
## [1] 433
# look at the first six rows of data.
#head(ind) #this is a good function to use but looks messy so not rendering it
# look at the structure of the dataframe.
str(ind)
## 'data.frame': 433 obs. of 39 variables:
## $ uid : chr "76bf37d9-c834-43fc-a430-83d87e4b9289" "cf0239bb-2953-44a8-8fd2-051539be5727" "833e5f41-d5cb-4550-ba60-e6f000a2b1b6" "6c2e348d-d19e-4543-9d22-0527819ee964" ...
## $ namedLocation : chr "BLAN_061.phenology.phe" "BLAN_061.phenology.phe" "BLAN_061.phenology.phe" "BLAN_061.phenology.phe" ...
## $ domainID : chr "D02" "D02" "D02" "D02" ...
## $ siteID : chr "BLAN" "BLAN" "BLAN" "BLAN" ...
## $ plotID : chr "BLAN_061" "BLAN_061" "BLAN_061" "BLAN_061" ...
## $ decimalLatitude : num 39.1 39.1 39.1 39.1 39.1 ...
## $ decimalLongitude : num -78.1 -78.1 -78.1 -78.1 -78.1 ...
## $ geodeticDatum : chr NA NA NA NA ...
## $ coordinateUncertainty : num NA NA NA NA NA NA NA NA NA NA ...
## $ elevation : num 183 183 183 183 183 183 183 183 183 183 ...
## $ elevationUncertainty : num NA NA NA NA NA NA NA NA NA NA ...
## $ subtypeSpecification : chr "primary" "primary" "primary" "primary" ...
## $ transectMeter : num 491 464 537 15 753 506 527 305 627 501 ...
## $ directionFromTransect : chr "Left" "Right" "Left" "Left" ...
## $ ninetyDegreeDistance : num 0.5 4 2 3 2 1 2 3 2 3 ...
## $ sampleLatitude : num NA NA NA NA NA NA NA NA NA NA ...
## $ sampleLongitude : num NA NA NA NA NA NA NA NA NA NA ...
## $ sampleGeodeticDatum : chr "WGS84" "WGS84" "WGS84" "WGS84" ...
## $ sampleCoordinateUncertainty: num NA NA NA NA NA NA NA NA NA NA ...
## $ sampleElevation : num NA NA NA NA NA NA NA NA NA NA ...
## $ sampleElevationUncertainty : num NA NA NA NA NA NA NA NA NA NA ...
## $ date : POSIXct, format: "2016-04-20" ...
## $ editedDate : POSIXct, format: "2016-05-09" ...
## $ individualID : chr "NEON.PLA.D02.BLAN.06290" "NEON.PLA.D02.BLAN.06501" "NEON.PLA.D02.BLAN.06204" "NEON.PLA.D02.BLAN.06223" ...
## $ taxonID : chr "RHDA" "SOAL6" "RHDA" "LOMA6" ...
## $ scientificName : chr "Rhamnus davurica Pall." "Solidago altissima L." "Rhamnus davurica Pall." "Lonicera maackii (Rupr.) Herder" ...
## $ identificationQualifier : chr NA NA NA NA ...
## $ taxonRank : chr "species" "species" "species" "species" ...
## $ nativeStatusCode : chr "I" "N" "I" "I" ...
## $ growthForm : chr "Deciduous broadleaf" "Forb" "Deciduous broadleaf" "Deciduous broadleaf" ...
## $ vstTag : chr NA NA NA NA ...
## $ samplingProtocolVersion : chr NA "NEON.DOC.014040vJ" "NEON.DOC.014040vJ" "NEON.DOC.014040vJ" ...
## $ measuredBy : chr "jcoloso@neoninc.org" "jward@battelleecology.org" "alandes@field-ops.org" "alandes@field-ops.org" ...
## $ identifiedBy : chr "shackley@neoninc.org" "llemmon@field-ops.org" "llemmon@field-ops.org" "llemmon@field-ops.org" ...
## $ recordedBy : chr "shackley@neoninc.org" NA NA NA ...
## $ remarks : chr "Nearly dead shaded out" "no entry" "no entry" "no entry" ...
## $ dataQF : chr NA NA NA NA ...
## $ publicationDate : chr "20201218T103411Z" "20201218T103411Z" "20201218T103411Z" "20201218T103411Z" ...
## $ release : chr "RELEASE-2021" "RELEASE-2021" "RELEASE-2021" "RELEASE-2021" ...
Notice that the neonUtilities package read the data type from the variables file
and then automatically converts the data to the correct date type in R.
(Note that if you first opened your data file in Excel, you might see 06/14/2014 as
the format instead of 2014-06-14. Excel can do some ~~weird~~ interesting things
to dates.)
Phenology status
Now let's look at the status data.
# What variables are included in this dataset?
names(status)
## [1] "uid" "namedLocation"
## [3] "domainID" "siteID"
## [5] "plotID" "date"
## [7] "editedDate" "dayOfYear"
## [9] "individualID" "phenophaseName"
## [11] "phenophaseStatus" "phenophaseIntensityDefinition"
## [13] "phenophaseIntensity" "samplingProtocolVersion"
## [15] "measuredBy" "recordedBy"
## [17] "remarks" "dataQF"
## [19] "publicationDate" "release"
nrow(status)
## [1] 219357
#head(status) #this is a good function to use but looks messy so not rendering it
str(status)
## 'data.frame': 219357 obs. of 20 variables:
## $ uid : chr "b69ada55-41d1-41c7-9031-149c54de51f9" "9be6f7ad-4422-40ac-ba7f-e32e0184782d" "58e7aeaf-163c-4ea2-ad75-db79a580f2f8" "efe7ca02-d09e-4964-b35d-aebdac8f3efb" ...
## $ namedLocation : chr "BLAN_061.phenology.phe" "BLAN_061.phenology.phe" "BLAN_061.phenology.phe" "BLAN_061.phenology.phe" ...
## $ domainID : chr "D02" "D02" "D02" "D02" ...
## $ siteID : chr "BLAN" "BLAN" "BLAN" "BLAN" ...
## $ plotID : chr "BLAN_061" "BLAN_061" "BLAN_061" "BLAN_061" ...
## $ date : POSIXct, format: "2017-02-24" ...
## $ editedDate : POSIXct, format: "2017-03-31" ...
## $ dayOfYear : num 55 55 55 55 55 55 55 55 55 55 ...
## $ individualID : chr "NEON.PLA.D02.BLAN.06229" "NEON.PLA.D02.BLAN.06226" "NEON.PLA.D02.BLAN.06222" "NEON.PLA.D02.BLAN.06223" ...
## $ phenophaseName : chr "Leaves" "Leaves" "Leaves" "Leaves" ...
## $ phenophaseStatus : chr "no" "no" "no" "no" ...
## $ phenophaseIntensityDefinition: chr NA NA NA NA ...
## $ phenophaseIntensity : chr NA NA NA NA ...
## $ samplingProtocolVersion : chr NA NA NA NA ...
## $ measuredBy : chr "llemmon@neoninc.org" "llemmon@neoninc.org" "llemmon@neoninc.org" "llemmon@neoninc.org" ...
## $ recordedBy : chr "llemmon@neoninc.org" "llemmon@neoninc.org" "llemmon@neoninc.org" "llemmon@neoninc.org" ...
## $ remarks : chr NA NA NA NA ...
## $ dataQF : chr "legacyData" "legacyData" "legacyData" "legacyData" ...
## $ publicationDate : chr "20201217T203824Z" "20201217T203824Z" "20201217T203824Z" "20201217T203824Z" ...
## $ release : chr "RELEASE-2021" "RELEASE-2021" "RELEASE-2021" "RELEASE-2021" ...
# date range
min(status$date)
## [1] "2017-02-24 GMT"
max(status$date)
## [1] "2019-12-12 GMT"
Clean up the Data
remove duplicates (full rows)
convert to date format
retain only the most recent editedDate in the perIndividual and status table.
Remove Duplicates
The individual table (ind) file is included in each site by month-year file. As
a result when all the tables are stacked there are many duplicates.
Let's remove any duplicates that exist.
# drop UID as that will be unique for duplicate records
ind_noUID <- select(ind, -(uid))
status_noUID <- select(status, -(uid))
# remove duplicates
## expect many
ind_noD <- distinct(ind_noUID)
nrow(ind_noD)
## [1] 433
status_noD<-distinct(status_noUID)
nrow(status_noD)
## [1] 216837
Variable Overlap between Tables
From the initial inspection of the data we can see there is overlap in variable
names between the fields.
Let's see what they are.
# where is there an intersection of names
intersect(names(status_noD), names(ind_noD))
## [1] "namedLocation" "domainID"
## [3] "siteID" "plotID"
## [5] "date" "editedDate"
## [7] "individualID" "samplingProtocolVersion"
## [9] "measuredBy" "recordedBy"
## [11] "remarks" "dataQF"
## [13] "publicationDate" "release"
There are several fields that overlap between the datasets. Some of these are
expected to be the same and will be what we join on.
However, some of these will have different values in each table. We want to keep
those distinct value and not join on them. Therefore, we can rename these
fields before joining:
date
editedDate
measuredBy
recordedBy
samplingProtocolVersion
remarks
dataQF
publicationDate
Now we want to rename the variables that would have duplicate names. We can
rename all the variables in the status object to have "Stat" at the end of the
variable name.
# in Status table rename like columns
status_noD <- rename(status_noD, dateStat=date,
editedDateStat=editedDate, measuredByStat=measuredBy,
recordedByStat=recordedBy,
samplingProtocolVersionStat=samplingProtocolVersion,
remarksStat=remarks, dataQFStat=dataQF,
publicationDateStat=publicationDate)
Filter to last editedDate
The individual (ind) table contains all instances that any of the location or
taxonomy data of an individual was updated. Therefore there are many rows for
some individuals. We only want the latest editedDate on ind.
# retain only the max of the date for each individualID
ind_last <- ind_noD %>%
group_by(individualID) %>%
filter(editedDate==max(editedDate))
# oh wait, duplicate dates, retain only the most recent editedDate
ind_lastnoD <- ind_last %>%
group_by(editedDate, individualID) %>%
filter(row_number()==1)
Join Dataframes
Now we can join the two data frames on all the variables with the same name.
We use a left_join() from the dpylr package because we want to match all the
rows from the "left" (first) dataframe to any rows that also occur in the "right"
(second) dataframe.
# Create a new dataframe "phe_ind" with all the data from status and some from ind_lastnoD
phe_ind <- left_join(status_noD, ind_lastnoD)
## Joining, by = c("namedLocation", "domainID", "siteID", "plotID", "individualID", "release")
Now that we have clean datasets we can begin looking into our particular data to
address our research question: do plants show patterns of changes in phenophase
across season?
Patterns in Phenophase
From our larger dataset (several sites, species, phenophases), let's create a
dataframe with only the data from a single site, species, and phenophase and
call it phe_1sp.
Select Site(s) of Interest
To do this, we'll first select our site of interest. Note how we set this up
with an object that is our site of interest. This will allow us to more easily change
which site or sites if we want to adapt our code later.
# set site of interest
siteOfInterest <- "SCBI"
# use filter to select only the site of Interest
## using %in% allows one to add a vector if you want more than one site.
## could also do it with == instead of %in% but won't work with vectors
phe_1st <- filter(phe_ind, siteID %in% siteOfInterest)
Select Species of Interest
Now we may only want to view a single species or a set of species. Let's first
look at the species that are present in our data. We could do this just by looking
at the taxonID field which give the four letter UDSA plant code for each
species. But if we don't know all the plant codes, we can get a bit fancier and
view both
# see which species are present - taxon ID only
unique(phe_1st$taxonID)
## [1] "JUNI" "MIVI" "LITU"
# or see which species are present with taxon ID + species name
unique(paste(phe_1st$taxonID, phe_1st$scientificName, sep=' - '))
## [1] "JUNI - Juglans nigra L."
## [2] "MIVI - Microstegium vimineum (Trin.) A. Camus"
## [3] "LITU - Liriodendron tulipifera L."
For now, let's choose only the flowering tree Liriodendron tulipifera (LITU).
By writing it this way, we could also add a list of species to the speciesOfInterest
object to select for multiple species.
speciesOfInterest <- "LITU"
#subset to just "LITU"
# here just use == but could also use %in%
phe_1sp <- filter(phe_1st, taxonID==speciesOfInterest)
# check that it worked
unique(phe_1sp$taxonID)
## [1] "LITU"
Select Phenophase of Interest
And, perhaps a single phenophase.
# see which phenophases are present
unique(phe_1sp$phenophaseName)
## [1] "Open flowers" "Breaking leaf buds"
## [3] "Colored leaves" "Increasing leaf size"
## [5] "Falling leaves" "Leaves"
phenophaseOfInterest <- "Leaves"
#subset to just the phenosphase of interest
phe_1sp <- filter(phe_1sp, phenophaseName %in% phenophaseOfInterest)
# check that it worked
unique(phe_1sp$phenophaseName)
## [1] "Leaves"
Select only Primary Plots
NEON plant phenology observations are collected along two types of plots.
Primary plots: an 800 meter square phenology loop transect
Phenocam plots: a 200 m x 200 m plot located within view of a canopy level,
tower-mounted, phenology camera
In the data, these plots are differentiated by the subtypeSpecification.
Depending on your question you may want to use only one or both of these plot types.
For this activity, we're going to only look at the primary plots.
**Data Tip:** How do I learn this on my own? Read
the Data Product User Guide and use the variables files with the data download
to find the corresponding variables names.
# what plots are present?
unique(phe_1sp$subtypeSpecification)
## [1] "primary" "phenocam"
# filter
phe_1spPrimary <- filter(phe_1sp, subtypeSpecification == 'primary')
# check that it worked
unique(phe_1spPrimary$subtypeSpecification)
## [1] "primary"
Total in Phenophase of Interest
The phenophaseState is recorded as "yes" or "no" that the individual is in that
phenophase. The phenophaseIntensity are categories for how much of the individual
is in that state. For now, we will stick with phenophaseState.
We can now calculate the total number of individuals with that state. We use
n_distinct(indvidualID) count the individuals (and not the records) in case
there are duplicate records for an individual.
But later on we'll also want to calculate the percent of the observed individuals
in the "leaves" status, therefore, we're also adding in a step here to retain the
sample size so that we can calculate % later.
Here we use pipes %>% from the dpylr package to "pass" objects onto the next
function.
# Calculate sample size for later use
sampSize <- phe_1spPrimary %>%
group_by(dateStat) %>%
summarise(numInd= n_distinct(individualID))
# Total in status by day for distinct individuals
inStat <- phe_1spPrimary%>%
group_by(dateStat, phenophaseStatus)%>%
summarise(countYes=n_distinct(individualID))
## `summarise()` has grouped output by 'dateStat'. You can override using the `.groups` argument.
inStat <- full_join(sampSize, inStat, by="dateStat")
# Retain only Yes
inStat_T <- filter(inStat, phenophaseStatus %in% "yes")
# check that it worked
unique(inStat_T$phenophaseStatus)
## [1] "yes"
Now that we have the data we can plot it.
Plot with ggplot
The ggplot() function within the ggplot2 package gives us considerable control
over plot appearance. Three basic elements are needed for ggplot() to work:
The data_frame: containing the variables that we wish to plot,
aes (aesthetics): which denotes which variables will map to the x-, y-
(and other) axes,
geom_XXXX (geometry): which defines the data's graphical representation
(e.g. points (geom_point), bars (geom_bar), lines (geom_line), etc).
The syntax begins with the base statement that includes the data_frame
(inStat_T) and associated x (date) and y (n) variables to be
plotted:
To successfully plot, the last piece that is needed is the geometry type.
To create a bar plot, we set the geom element from to geom_bar().
The default setting for a ggplot bar plot - geom_bar() - is a histogram
designated by stat="bin". However, in this case, we want to plot count values.
We can use geom_bar(stat="identity") to force ggplot to plot actual values.
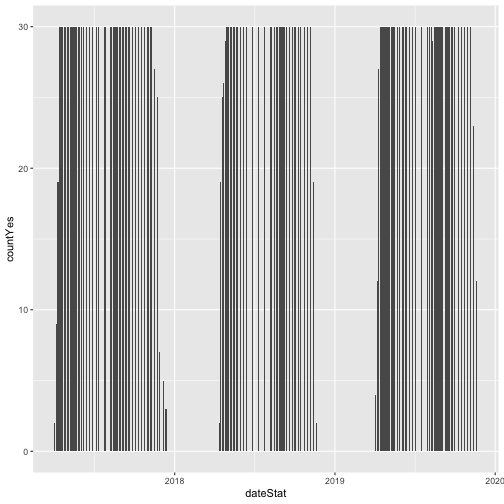
# plot number of individuals in leaf
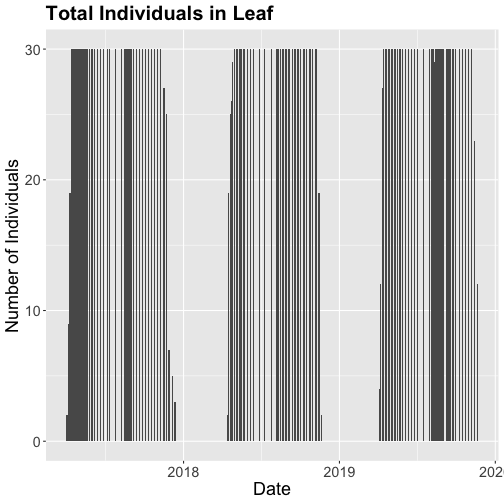
phenoPlot <- ggplot(inStat_T, aes(dateStat, countYes)) +
geom_bar(stat="identity", na.rm = TRUE)
phenoPlot
# Now let's make the plot look a bit more presentable
phenoPlot <- ggplot(inStat_T, aes(dateStat, countYes)) +
geom_bar(stat="identity", na.rm = TRUE) +
ggtitle("Total Individuals in Leaf") +
xlab("Date") + ylab("Number of Individuals") +
theme(plot.title = element_text(lineheight=.8, face="bold", size = 20)) +
theme(text = element_text(size=18))
phenoPlot
We could also covert this to percentage and plot that.
The plots demonstrate the nice expected pattern of increasing leaf-out, peak,
and drop-off.
Drivers of Phenology
Now that we see that there are differences in and shifts in phenophases, what
are the drivers of phenophases?
The NEON phenology measurements track sensitive and easily observed indicators
of biotic responses to climate variability by monitoring the timing and duration
of phenological stages in plant communities. Plant phenology is affected by forces
such as temperature, timing and duration of pest infestations and disease outbreaks,
water fluxes, nutrient budgets, carbon dynamics, and food availability and has
feedbacks to trophic interactions, carbon sequestration, community composition
and ecosystem function. (quoted from
Plant Phenology Observations user guide.)
Filter by Date
In the next part of this series, we will be exploring temperature as a driver of
phenology. Temperature date is quite large (NEON provides this in 1 minute or 30
minute intervals) so let's trim our phenology date down to only one year so that
we aren't working with as large a data.
Let's filter to just 2018 data.
# use filter to select only the date of interest
phe_1sp_2018 <- filter(inStat_T, dateStat >= "2018-01-01" & dateStat <= "2018-12-31")
# did it work?
range(phe_1sp_2018$dateStat)
## [1] "2018-04-13 GMT" "2018-11-20 GMT"
How does that look?
# Now let's make the plot look a bit more presentable
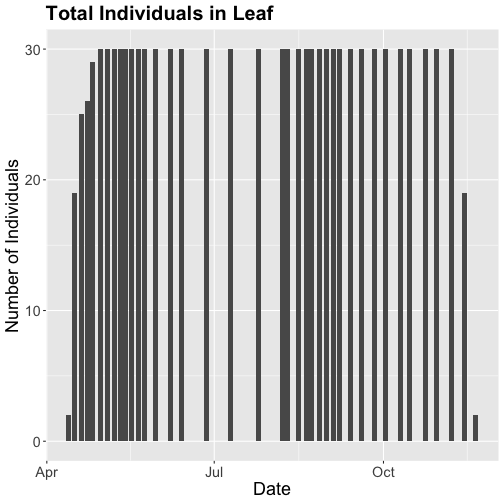
phenoPlot18 <- ggplot(phe_1sp_2018, aes(dateStat, countYes)) +
geom_bar(stat="identity", na.rm = TRUE) +
ggtitle("Total Individuals in Leaf") +
xlab("Date") + ylab("Number of Individuals") +
theme(plot.title = element_text(lineheight=.8, face="bold", size = 20)) +
theme(text = element_text(size=18))
phenoPlot18
Now that we've filtered down to just the 2018 data from SCBI for LITU in leaf,
we may want to save that subsetted data for another use. To do that you can write
the data frame to a .csv file.
You do not need to follow this step if you are continuing on to the next tutorials
in this series as you already have the data frame in your environment. Of course
if you close R and then come back to it, you will need to re-load this data and
instructions for that are provided in the relevant tutorials.
# Write .csv - this step is optional
# This will write to your current working directory, change as desired.
write.csv( phe_1sp_2018 , file="NEONpheno_LITU_Leaves_SCBI_2018.csv", row.names=F)
#If you are using the downloaded example date, this code will write it to the
# pheno data file. Note - this file is already a part of the download.
#write.csv( phe_1sp_2018 , file="NEON-pheno-temp-timeseries_v2/NEONpheno_LITU_Leaves_SCBI_2018.csv", row.names=F)
This is a tutorial in pulling data from the NEON API or Application
Programming Interface. The tutorial uses R and the R package httr, but the core
information about the API is applicable to other languages and approaches.
Objectives
After completing this activity, you will be able to:
Construct API calls to query the NEON API.
Access and understand data and metadata available via the NEON API.
Things You’ll Need To Complete This Tutorial
To complete this tutorial you will need the most current version of R and,
preferably, RStudio loaded on your computer.
If you are unfamiliar with the concept of an API, think of an API as a
‘middle person' that provides a communication path for a software application
to obtain information from a digital data source. APIs are becoming a very
common means of sharing digital information. Many of the apps that you use on
your computer or mobile device to produce maps, charts, reports, and other
useful forms of information pull data from multiple sources using APIs. In
the ecological and environmental sciences, many researchers use APIs to
programmatically pull data into their analyses. (Quoted from the NEON Observatory
Blog story:
API and data availability viewer now live on the NEON data portal.)
What is accessible via the NEON API?
The NEON API includes endpoints for NEON data and metadata, including
spatial data, taxonomic data, and samples (see Endpoints below). This
tutorial explores these sources of information using a specific data
product as a guide. The principles and rule sets described below can
be applied to other data products and metadata.
Specifics are appended to this in order to get the data or metadata you're
looking for, but all calls to an API will include the base URL. For the NEON
API, this is http://data.neonscience.org/api/v0 --
not clickable, because the base URL by itself will take you nowhere!
Your first thought is probably to use the /data endpoint. And we'll get
there. But notice above that the API call for the /data endpoint includes
the site and month of data to download. You don't want to have to guess sites
and months at random - first, you need to see which sites and months have
available data for the product you're interested in. That can be done either
through the /sites or the /products endpoint; here we'll use
/products.
Note: Checking for data availability can sometimes be skipped for the
streaming sensor data products. In general, they are available continuously,
and you could theoretically query a site and month of interest and expect
there to be data by default. However, there can be interruptions to sensor
data, in particular at aquatic sites, so checking availability first is the
most reliable approach.
Use the products endpoint to query for Woody vegetation data. The target is
the data product identifier, noted above, DP1.10098.001:
# Load the necessary libraries
library(httr)
library(jsonlite)
# Request data using the GET function & the API call
req <- GET("http://data.neonscience.org/api/v0/products/DP1.10098.001")
req
## Response [https://data.neonscience.org/api/v0/products/DP1.10098.001]
## Date: 2021-06-16 01:03
## Status: 200
## Content-Type: application/json;charset=UTF-8
## Size: 70.1 kB
The object returned from GET() has many layers of information. Entering the
name of the object gives you some basic information about what you accessed.
Status: 200 indicates this was a successful query; the status field can be
a useful place to look if something goes wrong. These are HTTP status codes,
you can google them to find out what a given value indicates.
The Content-Type parameter tells us we've accessed a json file. The easiest
way to translate this to something more manageable in R is to use the
fromJSON() function in the jsonlite package. It will convert the json into
a nested list, flattening the nesting where possible.
# Make the data readable by jsonlite
req.text <- content(req, as="text")
# Flatten json into a nested list
avail <- jsonlite::fromJSON(req.text,
simplifyDataFrame=T,
flatten=T)
A lot of the content here is basic information about the data product.
You can see all of it by running the line print(avail), but
this will result in a very long printout in your console. Instead, try viewing
list items individually. Here, we highlight a couple of interesting examples:
# View description of data product
avail$data$productDescription
## [1] "Structure measurements, including height, crown diameter, and stem diameter, as well as mapped position of individual woody plants"
# View data product abstract
avail$data$productAbstract
## [1] "This data product contains the quality-controlled, native sampling resolution data from in-situ measurements of live and standing dead woody individuals and shrub groups, from all terrestrial NEON sites with qualifying woody vegetation. The exact measurements collected per individual depend on growth form, and these measurements are focused on enabling biomass and productivity estimation, estimation of shrub volume and biomass, and calibration / validation of multiple NEON airborne remote-sensing data products. In general, comparatively large individuals that are visible to remote-sensing instruments are mapped, tagged and measured, and other smaller individuals are tagged and measured but not mapped. Smaller individuals may be subsampled according to a nested subplot approach in order to standardize the per plot sampling effort. Structure and mapping data are reported per individual per plot; sampling metadata, such as per growth form sampling area, are reported per plot. For additional details, see the user guide, protocols, and science design listed in the Documentation section in this data product's details webpage.\n\nLatency:\nThe expected time from data and/or sample collection in the field to data publication is as follows, for each of the data tables (in days) in the downloaded data package. See the Data Product User Guide for more information.\n\nvst_apparentindividual: 90\n\nvst_mappingandtagging: 90\n\nvst_perplotperyear: 300\n\nvst_shrubgroup: 90"
You may notice that some of this information is also accessible on the NEON
data portal. The portal uses the same data sources as the API, and in many
cases the portal is using the API on the back end, and simply adding a more
user-friendly display to the data.
We want to find which sites and months have available data. That is in the
siteCodes section. Let's look at what information is presented for each
site:
# Look at the first list element for siteCode
avail$data$siteCodes$siteCode[[1]]
## [1] "ABBY"
# And at the first list element for availableMonths
avail$data$siteCodes$availableMonths[[1]]
## [1] "2015-07" "2015-08" "2016-08" "2016-09" "2016-10" "2016-11" "2017-03" "2017-04" "2017-07" "2017-08"
## [11] "2017-09" "2018-07" "2018-08" "2018-09" "2018-10" "2018-11" "2019-07" "2019-09" "2019-10" "2019-11"
Here we can see the list of months with data for the site ABBY, which is
the Abby Road forest in Washington state.
The section $data$siteCodes$availableDataUrls provides the exact API
calls we need in order to query the data for each available site and month.
# Get complete list of available data URLs
wood.urls <- unlist(avail$data$siteCodes$availableDataUrls)
# Total number of URLs
length(wood.urls)
## [1] 535
# Show first 10 URLs available
wood.urls[1:10]
## [1] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2015-07"
## [2] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2015-08"
## [3] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2016-08"
## [4] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2016-09"
## [5] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2016-10"
## [6] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2016-11"
## [7] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2017-03"
## [8] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2017-04"
## [9] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2017-07"
## [10] "https://data.neonscience.org/api/v0/data/DP1.10098.001/ABBY/2017-08"
These URLs are the API calls we can use to find out what files are available
for each month where there are data. They are pre-constructed calls to the
/data endpoint of the NEON API.
Let's look at the woody plant data from the Rocky Mountain National Park
(RMNP) site from October 2019. We can do this by using the GET() function
on the relevant URL, which we can extract using the grep() function.
Note that if you want data from more than one site/month you need to iterate
this code, GET() fails if you give it more than one URL at a time.
# Get available data for RMNP Oct 2019
woody <- GET(wood.urls[grep("RMNP/2019-10", wood.urls)])
woody.files <- jsonlite::fromJSON(content(woody, as="text"))
# See what files are available for this site and month
woody.files$data$files$name
## [1] "NEON.D10.RMNP.DP1.10098.001.EML.20191010-20191017.20210123T023002Z.xml"
## [2] "NEON.D10.RMNP.DP1.10098.001.2019-10.basic.20210114T173951Z.zip"
## [3] "NEON.D10.RMNP.DP1.10098.001.vst_apparentindividual.2019-10.basic.20210114T173951Z.csv"
## [4] "NEON.D10.RMNP.DP1.10098.001.variables.20210114T173951Z.csv"
## [5] "NEON.D10.RMNP.DP0.10098.001.categoricalCodes.20210114T173951Z.csv"
## [6] "NEON.D10.RMNP.DP1.10098.001.readme.20210123T023002Z.txt"
## [7] "NEON.D10.RMNP.DP1.10098.001.vst_perplotperyear.2019-10.basic.20210114T173951Z.csv"
## [8] "NEON.D10.RMNP.DP1.10098.001.vst_mappingandtagging.basic.20210114T173951Z.csv"
## [9] "NEON.D10.RMNP.DP0.10098.001.validation.20210114T173951Z.csv"
If you've downloaded NEON data before via the data portal or the
neonUtilities package, this should look very familiar. The format
for most of the file names is:
NEON.[domain number].[site code].[data product ID].[file-specific name].
[year and month of data].[basic or expanded data package].
[date of file creation]
Some files omit the year and month, and/or the data package, since they're
not specific to a particular measurement interval, such as the data product
readme and variables files. The date of file creation uses the
ISO6801 format, for example 20210114T173951Z, and can be used to determine
whether data have been updated since the last time you downloaded.
Available files in our query for October 2019 at Rocky Mountain are all of the
following (leaving off the initial NEON.D10.RMNP.DP1.10098.001):
~.vst_perplotperyear.2019-10.basic.20210114T173951Z.csv: data table of
measurements conducted at the plot level every year
~.vst_apparentindividual.2019-10.basic.20210114T173951Z.csv: data table
containing measurements and observations conducted on woody individuals
~.vst_mappingandtagging.basic.20210114T173951Z.csv: data table
containing mapping data for each measured woody individual. Note year and
month are not in file name; these data are collected once per individual
and provided with every month of data downloaded
~.categoricalCodes.20210114T173951Z.csv: definitions of the values in
categorical variables
~.readme.20210123T023002Z.txt: readme for the data product (not specific
to dates or location)
~.EML.20191010-20191017.20210123T023002Z.xml: Ecological Metadata
Language (EML) file, describing the data product
~.validation.20210114T173951Z.csv: validation file for the data product,
lists input data and data entry validation rules
~.variables.20210114T173951Z.csv: variables file for the data product,
lists data fields in downloaded tables
~.2019-10.basic.20210114T173951Z.zip: zip of all files in the basic
package. Pre-packaged zips are planned to be removed; may not appear in
response to your query
This data product doesn't have an expanded package, so we only see the
basic package data files, and only one copy of each of the metadata files.
Let's get the data table for the mapping and tagging data. The list of files
doesn't return in the same order every time, so we shouldn't use the position
in the list to select the file name we want. Plus, we want code we can re-use
when getting data from other sites and other months. So we select file urls
based on the data table name in the file names.
Note that if there were an expanded package, the code above would return
two URLs. In that case you would need to specify the package as well in
selecting the URL.
Now we have the data and can access it in R. Just to show that the file we
pulled has actual data in it, let's make a quick graphic of the species
present and their abundances:
# Get counts by species
countBySp <- table(vst.maptag$taxonID)
# Reorder so list is ordered most to least abundance
countBySp <- countBySp[order(countBySp, decreasing=T)]
# Plot abundances
barplot(countBySp, names.arg=names(countBySp),
ylab="Total", las=2)
This shows us that the two most abundant species are designated with the
taxon codes PICOL and POTR5. We can look back at the data table, check the
scientificName field corresponding to these values, and see that these
are lodgepole pine and quaking aspen, as we might expect in the eastern
foothills of the Rocky mountains.
Let's say we're interested in how NEON defines quaking aspen, and
what taxon authority it uses for its definition. We can use the
/taxonomy endpoint of the API to do that.
Taxonomy
NEON maintains accepted taxonomies for many of the taxonomic identification
data we collect. NEON taxonomies are available for query via the API; they
are also provided via an interactive user interface, the Taxon Viewer.
NEON taxonomy data provides the reference information for how NEON
validates taxa; an identification must appear in the taxonomy lists
in order to be accepted into the NEON database. Additions to the lists
are reviewed regularly. The taxonomy lists also provide the author
of the scientific name, and the reference text used.
The taxonomy endpoint of the API has query options that are a bit more
complicated than what was described in the "Anatomy of an API Call"
section above. As described above, each endpoint has a single type of
target - a data product number, a named location name, etc. For taxonomic
data, there are multiple query options, and some of them can be used in
combination. Instead of entering a single target, we specify the query
type, and then the query parameter to search for. For example, a query
for taxa in the Pinaceae family:
The available types of queries are listed in the taxonomy section
of the API web page. Briefly, they are:
taxonTypeCode: Which of the taxonomies maintained by NEON are you
looking for? BIRD, FISH, PLANT, etc. Cannot be used in combination
with the taxonomic rank queries.
each of the major taxonomic ranks from genus through kingdom
scientificname: Genus + specific epithet (+ authority). Search is
by exact match only, see final example below.
verbose: Do you want the short (false) or long (true) response
offset: Skip this number of items at the start of the list.
limit: Result set will be truncated at this length.
For the first example, let's query for the loon family, Gaviidae, in the
bird taxonomy. Note that query parameters are case-sensitive.
And look at the $data element of the results, which contains:
The full taxonomy of each taxon
The short taxon code used by NEON (taxonID/acceptedTaxonID)
The author of the scientific name (scientificNameAuthorship)
The vernacular name, if applicable
The reference text used (nameAccordingToID)
The terms used for each field are matched to Darwin Core (dwc) and
the Global Biodiversity Information Facility (gbif) terms, where
possible, and the matches are indicated in the column headers.
loon.list$data
## taxonTypeCode taxonID acceptedTaxonID dwc:scientificName dwc:scientificNameAuthorship dwc:taxonRank
## 1 BIRD ARLO ARLO Gavia arctica (Linnaeus) species
## 2 BIRD COLO COLO Gavia immer (Brunnich) species
## 3 BIRD PALO PALO Gavia pacifica (Lawrence) species
## 4 BIRD RTLO RTLO Gavia stellata (Pontoppidan) species
## 5 BIRD YBLO YBLO Gavia adamsii (G. R. Gray) species
## dwc:vernacularName dwc:nameAccordingToID dwc:kingdom dwc:phylum dwc:class dwc:order dwc:family
## 1 Arctic Loon doi: 10.1642/AUK-15-73.1 Animalia Chordata Aves Gaviiformes Gaviidae
## 2 Common Loon doi: 10.1642/AUK-15-73.1 Animalia Chordata Aves Gaviiformes Gaviidae
## 3 Pacific Loon doi: 10.1642/AUK-15-73.1 Animalia Chordata Aves Gaviiformes Gaviidae
## 4 Red-throated Loon doi: 10.1642/AUK-15-73.1 Animalia Chordata Aves Gaviiformes Gaviidae
## 5 Yellow-billed Loon doi: 10.1642/AUK-15-73.1 Animalia Chordata Aves Gaviiformes Gaviidae
## dwc:genus gbif:subspecies gbif:variety
## 1 Gavia NA NA
## 2 Gavia NA NA
## 3 Gavia NA NA
## 4 Gavia NA NA
## 5 Gavia NA NA
To get the entire list for a particular taxonomic type, use the
taxonTypeCode query. Be cautious with this query, the PLANT taxonomic
list has several hundred thousand entries.
For an example, let's look up the small mammal taxonomic list, which
is one of the shorter ones, and use the verbose=true option to see
a more extensive list of taxon data, including many taxon ranks that
aren't populated for these taxa. For space here, we'll display only
the first 10 taxa:
mam.req <- GET("http://data.neonscience.org/api/v0/taxonomy/?taxonTypeCode=SMALL_MAMMAL&verbose=true")
mam.list <- jsonlite::fromJSON(content(mam.req, as="text"))
mam.list$data[1:10,]
## taxonTypeCode taxonID acceptedTaxonID dwc:scientificName dwc:scientificNameAuthorship
## 1 SMALL_MAMMAL AMHA AMHA Ammospermophilus harrisii Audubon and Bachman
## 2 SMALL_MAMMAL AMIN AMIN Ammospermophilus interpres Merriam
## 3 SMALL_MAMMAL AMLE AMLE Ammospermophilus leucurus Merriam
## 4 SMALL_MAMMAL AMLT AMLT Ammospermophilus leucurus tersus Goldman
## 5 SMALL_MAMMAL AMNE AMNE Ammospermophilus nelsoni Merriam
## 6 SMALL_MAMMAL AMSP AMSP Ammospermophilus sp. <NA>
## 7 SMALL_MAMMAL APRN APRN Aplodontia rufa nigra Taylor
## 8 SMALL_MAMMAL APRU APRU Aplodontia rufa Rafinesque
## 9 SMALL_MAMMAL ARAL ARAL Arborimus albipes Merriam
## 10 SMALL_MAMMAL ARLO ARLO Arborimus longicaudus True
## dwc:taxonRank dwc:vernacularName taxonProtocolCategory dwc:nameAccordingToID
## 1 species Harriss Antelope Squirrel opportunistic isbn: 978 0801882210
## 2 species Texas Antelope Squirrel opportunistic isbn: 978 0801882210
## 3 species Whitetailed Antelope Squirrel opportunistic isbn: 978 0801882210
## 4 subspecies <NA> opportunistic isbn: 978 0801882210
## 5 species Nelsons Antelope Squirrel opportunistic isbn: 978 0801882210
## 6 genus <NA> opportunistic isbn: 978 0801882210
## 7 subspecies <NA> non-target isbn: 978 0801882210
## 8 species Sewellel non-target isbn: 978 0801882210
## 9 species Whitefooted Vole target isbn: 978 0801882210
## 10 species Red Tree Vole target isbn: 978 0801882210
## dwc:nameAccordingToTitle
## 1 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## 2 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## 3 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## 4 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## 5 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## 6 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## 7 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## 8 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## 9 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## 10 Wilson D. E. and D. M. Reeder. 2005. Mammal Species of the World; A Taxonomic and Geographic Reference. Third edition. Johns Hopkins University Press; Baltimore, MD.
## dwc:kingdom gbif:subkingdom gbif:infrakingdom gbif:superdivision gbif:division gbif:subdivision
## 1 Animalia NA NA NA NA NA
## 2 Animalia NA NA NA NA NA
## 3 Animalia NA NA NA NA NA
## 4 Animalia NA NA NA NA NA
## 5 Animalia NA NA NA NA NA
## 6 Animalia NA NA NA NA NA
## 7 Animalia NA NA NA NA NA
## 8 Animalia NA NA NA NA NA
## 9 Animalia NA NA NA NA NA
## 10 Animalia NA NA NA NA NA
## gbif:infradivision gbif:parvdivision gbif:superphylum dwc:phylum gbif:subphylum gbif:infraphylum
## 1 NA NA NA Chordata NA NA
## 2 NA NA NA Chordata NA NA
## 3 NA NA NA Chordata NA NA
## 4 NA NA NA Chordata NA NA
## 5 NA NA NA Chordata NA NA
## 6 NA NA NA Chordata NA NA
## 7 NA NA NA Chordata NA NA
## 8 NA NA NA Chordata NA NA
## 9 NA NA NA Chordata NA NA
## 10 NA NA NA Chordata NA NA
## gbif:superclass dwc:class gbif:subclass gbif:infraclass gbif:superorder dwc:order gbif:suborder
## 1 NA Mammalia NA NA NA Rodentia NA
## 2 NA Mammalia NA NA NA Rodentia NA
## 3 NA Mammalia NA NA NA Rodentia NA
## 4 NA Mammalia NA NA NA Rodentia NA
## 5 NA Mammalia NA NA NA Rodentia NA
## 6 NA Mammalia NA NA NA Rodentia NA
## 7 NA Mammalia NA NA NA Rodentia NA
## 8 NA Mammalia NA NA NA Rodentia NA
## 9 NA Mammalia NA NA NA Rodentia NA
## 10 NA Mammalia NA NA NA Rodentia NA
## gbif:infraorder gbif:section gbif:subsection gbif:superfamily dwc:family gbif:subfamily gbif:tribe
## 1 NA NA NA NA Sciuridae Xerinae Marmotini
## 2 NA NA NA NA Sciuridae Xerinae Marmotini
## 3 NA NA NA NA Sciuridae Xerinae Marmotini
## 4 NA NA NA NA Sciuridae Xerinae Marmotini
## 5 NA NA NA NA Sciuridae Xerinae Marmotini
## 6 NA NA NA NA Sciuridae Xerinae Marmotini
## 7 NA NA NA NA Aplodontiidae <NA> <NA>
## 8 NA NA NA NA Aplodontiidae <NA> <NA>
## 9 NA NA NA NA Cricetidae Arvicolinae <NA>
## 10 NA NA NA NA Cricetidae Arvicolinae <NA>
## gbif:subtribe dwc:genus dwc:subgenus gbif:subspecies gbif:variety gbif:subvariety gbif:form
## 1 NA Ammospermophilus <NA> NA NA NA NA
## 2 NA Ammospermophilus <NA> NA NA NA NA
## 3 NA Ammospermophilus <NA> NA NA NA NA
## 4 NA Ammospermophilus <NA> NA NA NA NA
## 5 NA Ammospermophilus <NA> NA NA NA NA
## 6 NA Ammospermophilus <NA> NA NA NA NA
## 7 NA Aplodontia <NA> NA NA NA NA
## 8 NA Aplodontia <NA> NA NA NA NA
## 9 NA Arborimus <NA> NA NA NA NA
## 10 NA Arborimus <NA> NA NA NA NA
## gbif:subform speciesGroup dwc:specificEpithet dwc:infraspecificEpithet
## 1 NA <NA> harrisii <NA>
## 2 NA <NA> interpres <NA>
## 3 NA <NA> leucurus <NA>
## 4 NA <NA> leucurus tersus
## 5 NA <NA> nelsoni <NA>
## 6 NA <NA> sp. <NA>
## 7 NA <NA> rufa nigra
## 8 NA <NA> rufa <NA>
## 9 NA <NA> albipes <NA>
## 10 NA <NA> longicaudus <NA>
Now let's go back to our question about quaking aspen. To get
information about a single taxon, use the scientificname
query. This query will not do a fuzzy match, so you need to query
the exact name of the taxon in the NEON taxonomy. Because of this,
the query will be most useful in cases like the current one, where
you already have NEON data in hand and are looking for more
information about a specific taxon. Querying on scientificname
is unlikely to be an efficient way to figure out if NEON recognizes
a particular taxon.
In addition, scientific names contain spaces, which are not
allowed in a URL. The spaces need to be replaced with the URL
encoding replacement, %20.
Looking up the POTR5 data in the woody vegetation product, we
see that the scientific name is Populus tremuloides Michx.
This means we need to search for Populus%20tremuloides%20Michx.
to get the exact match.
This shows us the definition for Populus tremuloides Michx. does
not include a subspecies or variety, and the authority for the
taxon information (nameAccordingToID) is the USDA PLANTS
database. This means NEON taxonomic definitions are aligned with
the USDA, and is true for the large majority of plants in the
NEON taxon system.
Spatial data
How to get spatial data and what to do with it depends on which type of
data you're working with.
Instrumentation data (both aquatic and terrestrial)
The sensor_positions files, which are included in the list of available files,
contain spatial coordinates for each sensor in the data. See the final section
of the Geolocation tutorial for guidance in using these files.
Observational data - Aquatic
Latitude, longitude, elevation, and associated uncertainties are included in
data downloads. Most products also include an "additional coordinate uncertainty"
that should be added to the provided uncertainty. Additional spatial data, such
as northing and easting, can be downloaded from the API.
Observational data - Terrestrial
Latitude, longitude, elevation, and associated uncertainties are included in
data downloads. These are the coordinates and uncertainty of the sampling plot;
for many protocols it is possible to calculate a more precise location.
Instructions for doing this are in the respective data product user guides, and
code is in the geoNEON package on GitHub.
Querying a single named location
Let's look at a specific sampling location in the woody vegetation structure
data we downloaded above. To do this, look for the field called namedLocation,
which is present in all observational data products, both aquatic and
terrestrial. This field matches the exact name of the location in the NEON
database.
Here we see the first six entries in the namedLocation column, which tells us
the names of the Terrestrial Observation plots where the woody plant surveys
were conducted.
We can query the locations endpoint of the API for the first named location,
RMNP_043.basePlot.vst.
req.loc <- GET("http://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst")
vst.RMNP_043 <- jsonlite::fromJSON(content(req.loc, as="text"))
vst.RMNP_043
## $data
## $data$locationName
## [1] "RMNP_043.basePlot.vst"
##
## $data$locationDescription
## [1] "Plot \"RMNP_043\" at site \"RMNP\""
##
## $data$locationType
## [1] "OS Plot - vst"
##
## $data$domainCode
## [1] "D10"
##
## $data$siteCode
## [1] "RMNP"
##
## $data$locationDecimalLatitude
## [1] 40.27683
##
## $data$locationDecimalLongitude
## [1] -105.5454
##
## $data$locationElevation
## [1] 2740.39
##
## $data$locationUtmEasting
## [1] 453634.6
##
## $data$locationUtmNorthing
## [1] 4458626
##
## $data$locationUtmHemisphere
## [1] "N"
##
## $data$locationUtmZone
## [1] 13
##
## $data$alphaOrientation
## [1] 0
##
## $data$betaOrientation
## [1] 0
##
## $data$gammaOrientation
## [1] 0
##
## $data$xOffset
## [1] 0
##
## $data$yOffset
## [1] 0
##
## $data$zOffset
## [1] 0
##
## $data$offsetLocation
## NULL
##
## $data$locationProperties
## locationPropertyName locationPropertyValue
## 1 Value for Coordinate source GeoXH 6000
## 2 Value for Coordinate uncertainty 0.09
## 3 Value for Country unitedStates
## 4 Value for County Larimer
## 5 Value for Elevation uncertainty 0.1
## 6 Value for Filtered positions 300
## 7 Value for Geodetic datum WGS84
## 8 Value for Horizontal dilution of precision 1
## 9 Value for Maximum elevation 2743.43
## 10 Value for Minimum elevation 2738.52
## 11 Value for National Land Cover Database (2001) evergreenForest
## 12 Value for Plot dimensions 40m x 40m
## 13 Value for Plot ID RMNP_043
## 14 Value for Plot size 1600
## 15 Value for Plot subtype basePlot
## 16 Value for Plot type tower
## 17 Value for Positional dilution of precision 1.8
## 18 Value for Reference Point Position 41
## 19 Value for Slope aspect 0
## 20 Value for Slope gradient 0
## 21 Value for Soil type order Alfisols
## 22 Value for State province CO
## 23 Value for UTM Zone 13N
##
## $data$locationParent
## [1] "RMNP"
##
## $data$locationParentUrl
## [1] "https://data.neonscience.org/api/v0/locations/RMNP"
##
## $data$locationChildren
## [1] "RMNP_043.basePlot.vst.41" "RMNP_043.basePlot.vst.43" "RMNP_043.basePlot.vst.49"
## [4] "RMNP_043.basePlot.vst.51" "RMNP_043.basePlot.vst.59" "RMNP_043.basePlot.vst.57"
## [7] "RMNP_043.basePlot.vst.25" "RMNP_043.basePlot.vst.21" "RMNP_043.basePlot.vst.23"
## [10] "RMNP_043.basePlot.vst.33" "RMNP_043.basePlot.vst.31" "RMNP_043.basePlot.vst.39"
## [13] "RMNP_043.basePlot.vst.61"
##
## $data$locationChildrenUrls
## [1] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.41"
## [2] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.43"
## [3] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.49"
## [4] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.51"
## [5] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.59"
## [6] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.57"
## [7] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.25"
## [8] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.21"
## [9] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.23"
## [10] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.33"
## [11] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.31"
## [12] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.39"
## [13] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst.61"
Note spatial information under $data$[nameOfCoordinate] and under
$data$locationProperties. These coordinates represent the centroid of
plot RMNP_043, and should match the coordinates for the plot in the
vst_perplotperyear data table. In rare cases, spatial data may be
updated, and if this has happened more recently than the data table
was published, there may be a small mismatch in the coordinates. In
those cases, the data accessed via the API will be the most up to date.
Also note $data$locationChildren: these are the
point and subplot locations within plot RMNP_043. And
$data$locationChildrenUrls provides pre-constructed API calls for
querying those child locations. Let's look up the location data for
point 31 in plot RMNP_043.
req.child.loc <- GET(grep("31",
vst.RMNP_043$data$locationChildrenUrls,
value=T))
vst.RMNP_043.31 <- jsonlite::fromJSON(content(req.child.loc, as="text"))
vst.RMNP_043.31
## $data
## $data$locationName
## [1] "RMNP_043.basePlot.vst.31"
##
## $data$locationDescription
## [1] "31"
##
## $data$locationType
## [1] "Point"
##
## $data$domainCode
## [1] "D10"
##
## $data$siteCode
## [1] "RMNP"
##
## $data$locationDecimalLatitude
## [1] 40.27674
##
## $data$locationDecimalLongitude
## [1] -105.5455
##
## $data$locationElevation
## [1] 2741.56
##
## $data$locationUtmEasting
## [1] 453623.7
##
## $data$locationUtmNorthing
## [1] 4458616
##
## $data$locationUtmHemisphere
## [1] "N"
##
## $data$locationUtmZone
## [1] 13
##
## $data$alphaOrientation
## [1] 0
##
## $data$betaOrientation
## [1] 0
##
## $data$gammaOrientation
## [1] 0
##
## $data$xOffset
## [1] 0
##
## $data$yOffset
## [1] 0
##
## $data$zOffset
## [1] 0
##
## $data$offsetLocation
## NULL
##
## $data$locationProperties
## locationPropertyName locationPropertyValue
## 1 Value for Coordinate source GeoXH 6000
## 2 Value for Coordinate uncertainty 0.16
## 3 Value for Elevation uncertainty 0.28
## 4 Value for Geodetic datum WGS84
## 5 Value for National Land Cover Database (2001) evergreenForest
## 6 Value for Point ID 31
## 7 Value for UTM Zone 13N
##
## $data$locationParent
## [1] "RMNP_043.basePlot.vst"
##
## $data$locationParentUrl
## [1] "https://data.neonscience.org/api/v0/locations/RMNP_043.basePlot.vst"
##
## $data$locationChildren
## list()
##
## $data$locationChildrenUrls
## list()
Looking at the easting and northing coordinates, we can see that point
31 is about 10 meters away from the plot centroid in both directions.
Point 31 has no child locations.
For the records with pointID=31 in the vst.maptag table we
downloaded, these coordinates are the reference location that could be
used together with the stemDistance and stemAzimuth fields to
calculate the precise locations of individual trees. For detailed
instructions in how to do this, see the data product user guide.
Alternatively, the geoNEON package contains functions to make this
calculation for you, including accessing the location data from the
API. See below for details and links to tutorials.
R Packages
NEON provides two customized R packages that can carry out many of the
operations described above, in addition to other data transformations.
neonUtilities
The neonUtilities package contains functions that download data
via the API, and that merge the individual files for each site and
month in a single continuous file for each type of data table in the
download.
For a guide to using neonUtilities to download and stack data files,
check out the Download and Explore tutorial.
geoNEON
The geoNEON package contains functions that access spatial data
via the API, and that calculate precise locations for terrestrial
observational data. As in the case of woody vegetation structure,
terrestrial observational data products are published with
spatial data at the plot level, but more precise sampling locations
are usually possible to calculate.
For a guide to using geoNEON to calculate sampling locations,
check out the Geolocation tutorial.
In this tutorial, we demonstrate how to remove parts of a raster based on pixel values using a mask we create. A mask raster layer contains pixel values of either 1 or 0 to where 1 represents pixels that will be used in the analysis and 0 are pixels that are assigned a value of nan (not a number). This can be useful in a number of scenarios, when you are interested in only a certain portion of the data, or need to remove poor-quality data, for example.
Objectives
After completing this tutorial, you will be able to:
User rasterio to read in NEON lidar aspect and vegetation indices geotiff files
Plot a raster tile and histogram of the data values
Create a mask based on values from the aspect and ndvi data
Install Python Packages
gdal
rasterio
requests
zipfile
Download Data
For this lesson, we will read in Canopy Height Model data collected at NEON's Lower Teakettle (TEAK) site in California. This data is downloaded in the first part of the tutorial, using the Python requests package.
import os
import copy
import numpy as np
import numpy.ma as ma
import rasterio as rio
from rasterio.plot import show, show_hist
import requests
import zipfile
import matplotlib.pyplot as plt
from matplotlib import colors
import matplotlib.patches as mpatches
%matplotlib inline
Read in the datasets
Download Lidar Elevation Models and Vegetation Indices from TEAK
To start, we will download the NEON Lidar Aspect and Spectrometer Vegetation Indices (including the NDVI) which are provided in geotiff (.tif) format. Use the download_url function below to download the data directly from the cloud storage location.
# function to download data stored on the internet in a public url to a local file
def download_url(url,download_dir):
if not os.path.isdir(download_dir):
os.makedirs(download_dir)
filename = url.split('/')[-1]
r = requests.get(url, allow_redirects=True)
file_object = open(os.path.join(download_dir,filename),'wb')
file_object.write(r.content)
# define the urls for downloading the Aspect and NDVI geotiff tiles
aspect_url = "https://storage.googleapis.com/neon-aop-products/2021/FullSite/D17/2021_TEAK_5/L3/DiscreteLidar/AspectGtif/NEON_D17_TEAK_DP3_320000_4092000_aspect.tif"
ndvi_url = "https://storage.googleapis.com/neon-aop-products/2021/FullSite/D17/2021_TEAK_5/L3/Spectrometer/VegIndices/NEON_D17_TEAK_DP3_320000_4092000_VegetationIndices.zip"
# download the raster data using the download_url function
download_url(aspect_url,'.\data')
download_url(ndvi_url,'.\data')
# display the contents in the ./data folder to confirm the download completed
os.listdir('./data')
We can use zipfile to unzip the VegetationIndices folder in order to read the NDVI file (which is included in the zipped folder).
with zipfile.ZipFile("./data/NEON_D17_TEAK_DP3_320000_4092000_VegetationIndices.zip","r") as zip_ref:
zip_ref.extractall("./data")
os.listdir('./data')
Now that the files are downloaded, we can read them in using rasterio.
aspect_file = os.path.join("./data",'NEON_D17_TEAK_DP3_320000_4092000_aspect.tif')
aspect_dataset = rio.open(aspect_file)
aspect_data = aspect_dataset.read(1)
# preview the aspect data
aspect_data
Define and view the spatial extent so we can use this for plotting later on.
aspect_reclass = aspect_data.copy()
# classify North and South as 1 & 2
aspect_reclass[np.where(((aspect_data>=0) & (aspect_data<=45)) | (aspect_data>=315))] = 1 #North - Class 1
aspect_reclass[np.where((aspect_data>=135) & (aspect_data<=225))] = 2 #South - Class 2
# West and East are unclassified (nan)
aspect_reclass[np.where(((aspect_data>45) & (aspect_data<135)) | ((aspect_data>225) & (aspect_data<315)))] = np.nan
Plot the classified aspect map to highlight the north and south facing slopes.
# Plot classified aspect (N-S) array
fig, ax = plt.subplots(1, 1, figsize=(6,6))
cmap_NS = colors.ListedColormap(['blue','white','red'])
plt.imshow(aspect_reclass,extent=ext,cmap=cmap_NS)
plt.title('TEAK North & South Facing Slopes')
ax=plt.gca(); ax.ticklabel_format(useOffset=False, style='plain') #do not use scientific notation
rotatexlabels = plt.setp(ax.get_xticklabels(),rotation=90) #rotate x tick labels 90 degrees
# Create custom legend to label N & S
white_box = mpatches.Patch(facecolor='white',label='East, West, or NaN')
blue_box = mpatches.Patch(facecolor='blue', label='North')
red_box = mpatches.Patch(facecolor='red', label='South')
ax.legend(handles=[white_box,blue_box,red_box],handlelength=0.7,bbox_to_anchor=(1.05, 0.45),
loc='lower left', borderaxespad=0.);
Mask Data by Aspect and NDVI
Now that we have imported and converted the classified aspect and NDVI rasters to arrays, we can use information from these to find create a new raster consisting of pixels are North facing and have an NDVI > 0.4.
#Mask out pixels that are north facing:
# first make a copy of the ndvi array so we can further select a subset
ndvi_gtpt4 = ndvi_data.copy()
ndvi_gtpt4[ndvi_data<0.4]=np.nan
fig, ax = plt.subplots(1, 1, figsize=(6,6))
plt.imshow(ndvi_gtpt4,extent=ext)
plt.colorbar(); plt.set_cmap('RdYlGn');
plt.title('TEAK NDVI > 0.4')
ax=plt.gca(); ax.ticklabel_format(useOffset=False, style='plain') #do not use scientific notation
rotatexlabels = plt.setp(ax.get_xticklabels(),rotation=90) #rotate x tick labels 90 degrees
#Now include additional requirement that slope is North-facing (i.e. aspectNS_array = 1)
ndvi_gtpt4_north = ndvi_gtpt4.copy()
ndvi_gtpt4_north[aspect_reclass != 1] = np.nan
fig, ax = plt.subplots(1, 1, figsize=(6,6))
plt.imshow(ndvi_gtpt4_north,extent=ext)
plt.colorbar(); plt.set_cmap('RdYlGn');
plt.title('TEAK, North Facing & NDVI > 0.4')
ax=plt.gca(); ax.ticklabel_format(useOffset=False, style='plain') #do not use scientific notation
rotatexlabels = plt.setp(ax.get_xticklabels(),rotation=90) #rotate x tick labels 90 degrees
It looks like there aren't that many parts of the North facing slopes where the NDVI > 0.4. Can you think of why this might be?
Hint: consider both ecological reasons and how the flight acquisition might affect NDVI.
Let's also look at where NDVI > 0.4 on south facing slopes.
#Now include additional requirement that slope is Sorth-facing (i.e. aspect_reclass = 2)
ndvi_gtpt4_south = ndvi_gtpt4.copy()
ndvi_gtpt4_south[aspect_reclass != 2] = np.nan
fig, ax = plt.subplots(1, 1, figsize=(6,6))
plt.imshow(ndvi_gtpt4_south,extent=ext)
plt.colorbar(); plt.set_cmap('RdYlGn');
plt.title('TEAK, South Facing & NDVI > 0.4')
ax=plt.gca(); ax.ticklabel_format(useOffset=False, style='plain') #do not use scientific notation
rotatexlabels = plt.setp(ax.get_xticklabels(),rotation=90) #rotate x tick labels 90 degrees
Export Masked Raster to Geotiff
We can also use rasterio to write out the geotiff file. In this case, we will just copy over the metadata from the NDVI raster so that the projection information and everything else is correct. You could create your own metadata dictionary and change the coordinate system, etc. if you chose, but we will keep it simple for this example.
out_meta = ndvi_dataset.meta.copy()
with rio.open('TEAK_NDVIgtpt4_South.tif', 'w', **out_meta) as dst:
dst.write(ndvi_gtpt4_south, 1)
For peace of mind, let's read back in this raster that we generated and confirm that the contents are identical to the array that we used to generate it. We can do this visually, by plotting it, and also with an equality test.
# use np.array_equal to check that the contents of the file we read back in is the same as the original array
np.array_equal(new_dataset.read(1),ndvi_gtpt4_south,equal_nan=True)
In this tutorial, we will calculate the biomass for a section of the SJER site. We
will be using the Canopy Height Model discrete LiDAR data product as well as NEON
field data on vegetation data. This tutorial will calculate Biomass for individual
trees in the forest.
Objectives
After completing this tutorial, you will be able to:
Learn how to apply a Gaussian smoothing kernel for high-frequency spatial filtering
Apply a watershed segmentation algorithm for delineating tree crowns
Calculate biomass predictor variables from a CHM
Set up training data for biomass predictions
Apply a Random Forest machine learning model to calculate biomass
Install Python Packages
gdal
scipy
scikit-learn
scikit-image
The following packages should be part of the standard conda installation:
os
sys
numpy
matplotlib
Download Data
If you have already downloaded the data set for the Data Institute, you have the
data for this tutorial within the SJER directory. If you would like to just
download the data for this tutorial use the following links.
In this tutorial, we will calculate the biomass for a section of the SJER site. We will be using the Canopy Height Model discrete LiDAR data product as well as NEON field data on vegetation data. This tutorial will calculate biomass for individual
trees in the forest.
The calculation of biomass consists of four primary steps:
Delineate individual tree crowns
Calculate predictor variables for all individual trees
Collect training data
Apply a Random Forest regression model to estimate biomass from the predictor variables
In this tutorial we will use a watershed segmentation algorithm for delineating tree crowns (step 1) and and a Random Forest (RF) machine learning algorithm for relating the predictor variables to biomass (part 4). The predictor variables were
selected following suggestions by Gleason et al. (2012) and biomass estimates were determined from DBH (diameter at breast height) measurements following relationships given in Jenkins et al. (2003).
Get Started
First, we will import some Python packages required to run various parts of the script:
import os, sys
import gdal, osr
import numpy as np
import matplotlib.pyplot as plt
from scipy import ndimage as ndi
%matplotlib inline
Next, we will add libraries from scikit-learn which will help with the watershed delination, determination of predictor variables and random forest algorithm
#Import biomass specific libraries
from skimage.morphology import watershed
from skimage.feature import peak_local_max
from skimage.measure import regionprops
from sklearn.ensemble import RandomForestRegressor
We also need to specify the directory where we will find and save the data needed for this tutorial. You may need to change this line to follow a different working directory structure, or to suit your local machine. I have decided to save my data in the following directory:
raster2array: function to conver rasters to an array
def raster2array(geotif_file):
metadata = {}
dataset = gdal.Open(geotif_file)
metadata['array_rows'] = dataset.RasterYSize
metadata['array_cols'] = dataset.RasterXSize
metadata['bands'] = dataset.RasterCount
metadata['driver'] = dataset.GetDriver().LongName
metadata['projection'] = dataset.GetProjection()
metadata['geotransform'] = dataset.GetGeoTransform()
mapinfo = dataset.GetGeoTransform()
metadata['pixelWidth'] = mapinfo[1]
metadata['pixelHeight'] = mapinfo[5]
metadata['ext_dict'] = {}
metadata['ext_dict']['xMin'] = mapinfo[0]
metadata['ext_dict']['xMax'] = mapinfo[0] + dataset.RasterXSize/mapinfo[1]
metadata['ext_dict']['yMin'] = mapinfo[3] + dataset.RasterYSize/mapinfo[5]
metadata['ext_dict']['yMax'] = mapinfo[3]
metadata['extent'] = (metadata['ext_dict']['xMin'],metadata['ext_dict']['xMax'],
metadata['ext_dict']['yMin'],metadata['ext_dict']['yMax'])
if metadata['bands'] == 1:
raster = dataset.GetRasterBand(1)
metadata['noDataValue'] = raster.GetNoDataValue()
metadata['scaleFactor'] = raster.GetScale()
# band statistics
metadata['bandstats'] = {} # make a nested dictionary to store band stats in same
stats = raster.GetStatistics(True,True)
metadata['bandstats']['min'] = round(stats[0],2)
metadata['bandstats']['max'] = round(stats[1],2)
metadata['bandstats']['mean'] = round(stats[2],2)
metadata['bandstats']['stdev'] = round(stats[3],2)
array = dataset.GetRasterBand(1).ReadAsArray(0,0,
metadata['array_cols'],
metadata['array_rows']).astype(np.float)
array[array==int(metadata['noDataValue'])]=np.nan
array = array/metadata['scaleFactor']
return array, metadata
else:
print('More than one band ... function only set up for single band data')
crown_geometric_volume_pct: function to get the tree height and crown volume percentiles
def crown_geometric_volume_pct(tree_data,min_tree_height,pct):
p = np.percentile(tree_data, pct)
tree_data_pct = [v if v < p else p for v in tree_data]
crown_geometric_volume_pct = np.sum(tree_data_pct - min_tree_height)
return crown_geometric_volume_pct, p
get_predictors: function to get the predictor variables from the biomass data
With everything set up, we can now start working with our data by define the file path to our CHM file. Note that you will need to change this and subsequent filepaths according to your local machine.
#Plot the original CHM
plt.figure(1)
#Plot the CHM figure
plot_band_array(chm_array,chm_array_metadata['extent'],
'Canopy Height Model',
'Canopy Height (m)',
'Greens',[0, 9])
plt.savefig(os.path.join(data_path,chm_name.replace('.tif','.png')),dpi=300,orientation='landscape',
bbox_inches='tight',
pad_inches=0.1)
It looks like SJER primarily has low vegetation with scattered taller trees.
Create Filtered CHM
Now we will use a Gaussian smoothing kernal (convolution) across the data set to remove spurious high vegetation points. This will help ensure we are finding the treetops properly before running the watershed segmentation algorithm.
For different forest types it may be necessary to change the input parameters. Information on the function can be found in the SciPy documentation.
Of most importance are the second and fifth inputs. The second input defines the standard deviation of the Gaussian smoothing kernal. Too large a value will apply too much smoothing, too small and some spurious high points may be left behind. The fifth, the truncate value, controls after how many standard deviations the Gaussian kernal will get cut off (since it theoretically goes to infinity).
#Smooth the CHM using a gaussian filter to remove spurious points
chm_array_smooth = ndi.gaussian_filter(chm_array,2,mode='constant',cval=0,truncate=2.0)
chm_array_smooth[chm_array==0] = 0
Now save a copy of filtered CHM. We will later use this in our code, so we'll output it into our data directory.
#Save the smoothed CHM
array2raster(os.path.join(data_path,'chm_filter.tif'),
(chm_array_metadata['ext_dict']['xMin'],chm_array_metadata['ext_dict']['yMax']),
1,-1,np.array(chm_array_smooth,dtype=float),32611)
Determine local maximums
Now we will run an algorithm to determine local maximums within the image. Setting indices to False returns a raster of the maximum points, as opposed to a list of coordinates. The footprint parameter is an area where only a single peak can be found. This should be approximately the size of the smallest tree. Information on more sophisticated methods to define the window can be found in Chen (2006).
#Calculate local maximum points in the smoothed CHM
local_maxi = peak_local_max(chm_array_smooth,indices=False, footprint=np.ones((5, 5)))
Our new object local_maxi is an array of boolean values where each pixel is identified as either being the local maximum (True) or not being the local maximum (False).
This is helpful, but it can be difficult to visualize boolean values using our typical numeric plotting procedures as defined in the plot_band_array function above. Therefore, we will need to convert this boolean array to an numeric format to use this function. Booleans convert easily to integers with values of False=0 and True=1 using the .astype(int) method.
Next we can plot the raster of local maximums by coercing the boolean array into an array of integers inline. The following figure shows the difference in finding local maximums for a filtered vs. non-filtered CHM.
We will save the graphics (.png) in an outputs folder sister to our working directory and data outputs (.tif) to our data directory.
#Plot the local maximums
plt.figure(2)
plot_band_array(local_maxi.astype(int),chm_array_metadata['extent'],
'Maximum',
'Maxi',
'Greys',
[0, 1])
plt.savefig(data_path+chm_name[0:-4]+ '_Maximums.png',
dpi=300,orientation='landscape',
bbox_inches='tight',pad_inches=0.1)
array2raster(data_path+'maximum.tif',
(chm_array_metadata['ext_dict']['xMin'],chm_array_metadata['ext_dict']['yMax']),
1,-1,np.array(local_maxi,dtype=np.float32),32611)
If we were to look at the overlap between the tree crowns and the local maxima from each method, it would appear a bit like this raster.
The difference in finding local maximums for a filtered vs. un-filtered CHM.
Source: National Ecological Observatory Network (NEON)
Apply labels to all of the local maximum points
#Identify all the maximum points
markers = ndi.label(local_maxi)[0]
Next we will create a mask layer of all of the vegetation points so that the watershed segmentation will only occur on the trees and not extend into the surrounding ground points. Since 0 represent ground points in the CHM, setting the mask to 1 where the CHM is not zero will define the mask
#Create a CHM mask so the segmentation will only occur on the trees
chm_mask = chm_array_smooth
chm_mask[chm_array_smooth != 0] = 1
Watershed segmentation
As in a river system, a watershed is divided by a ridge that divides areas. Here our watershed are the individual tree canopies and the ridge is the delineation between each one.
A raster classified based on watershed segmentation.
Source: National Ecological Observatory Network (NEON)
Next, we will perform the watershed segmentation which produces a raster of labels.
Now we will get several properties of the individual trees will be used as predictor variables.
#Get the properties of each segment
tree_properties = regionprops(labels,chm_array)
Now we will get the predictor variables to match the (soon to be loaded) training data using the get_predictors function defined above. The first column will be segment IDs, the rest will be the predictor variables, namely the tree label, area, major_axis_length, maximum height, minimum height, height percentiles (p50, p60, p70), and crown geometric volume percentiles (full and percentiles 50, 60, and 70).
predictors_chm = np.array([get_predictors(tree, chm_array, labels) for tree in tree_properties])
X = predictors_chm[:,1:]
tree_ids = predictors_chm[:,0]
Training data
We now bring in the training data file which is a simple CSV file with no header. If you haven't yet downloaded this, you can scroll up to the top of the lesson and find the Download Data section. The first column is biomass, and the remaining columns are the same predictor variables defined above. The tree diameter and max height are defined in the NEON vegetation structure data along with the tree DBH. The field validated values are used for training, while the other were determined from the CHM and camera images by manually delineating the tree crowns and pulling out the relevant information from the CHM.
Biomass was calculated from DBH according to the formulas in Jenkins et al. (2003).
#Get the full path + training data file
training_data_file = os.path.join(data_path,'SJER_Biomass_Training.csv')
#Read in the training data csv file into a numpy array
training_data = np.genfromtxt(training_data_file,delimiter=',')
#Grab the biomass (Y) from the first column
biomass = training_data[:,0]
#Grab the biomass predictors from the remaining columns
biomass_predictors = training_data[:,1:12]
Random Forest classifiers
We can then define parameters of the Random Forest classifier and fit the predictor variables from the training data to the Biomass estimates.
#Define parameters for the Random Forest Regressor
max_depth = 30
#Define regressor settings
regr_rf = RandomForestRegressor(max_depth=max_depth, random_state=2)
#Fit the biomass to regressor variables
regr_rf.fit(biomass_predictors,biomass)
We will now apply the Random Forest model to the predictor variables to estimate biomass
#Apply the model to the predictors
estimated_biomass = regr_rf.predict(X)
To output a raster, pre-allocate (copy) an array from the labels raster, then cycle through the segments and assign the biomass estimate to each individual tree segment.
#Set an out raster with the same size as the labels
biomass_map = np.array((labels),dtype=float)
#Assign the appropriate biomass to the labels
biomass_map[biomass_map==0] = np.nan
for tree_id, biomass_of_tree_id in zip(tree_ids, estimated_biomass):
biomass_map[biomass_map == tree_id] = biomass_of_tree_id
Calculate Biomass
Collect some of the biomass statistics and then plot the results and save an output geotiff.
#Get biomass stats for plotting
mean_biomass = np.mean(estimated_biomass)
std_biomass = np.std(estimated_biomass)
min_biomass = np.min(estimated_biomass)
sum_biomass = np.sum(estimated_biomass)
print('Sum of biomass is ',sum_biomass,' kg')
# Plot the biomass!
plt.figure(5)
plot_band_array(biomass_map,chm_array_metadata['extent'],
'Biomass (kg)','Biomass (kg)',
'winter',
[min_biomass+std_biomass, mean_biomass+std_biomass*3])
# Save the biomass figure; use the same name as the original file, but replace CHM with Biomass
plt.savefig(os.path.join(data_path,chm_name.replace('CHM.tif','Biomass.png')),
dpi=300,orientation='landscape',
bbox_inches='tight',
pad_inches=0.1)
# Use the array2raster function to create a geotiff file of the Biomass
array2raster(os.path.join(data_path,chm_name.replace('CHM.tif','Biomass.tif')),
(chm_array_metadata['ext_dict']['xMin'],chm_array_metadata['ext_dict']['yMax']),
1,-1,np.array(biomass_map,dtype=float),32611)
In this exercise we will analyze the several NEON level 3 lidar rasters to assess
the uncertainty between days.
Objectives
After completing this tutorial, you will be able to:
Load several tif files with metadata
Difference tif files
Create histograms
Remove areas of DSM & DTMs through logical indexing of the CHM
Install Python Packages
numpy
gdal
matplotlib.pyplot
h5py
Download Data
The link below contains all the data from the 2017 Data Institute (17 GB). For this tutorial, we
need ONLY the data in the CHEQ, F07A, and PRIN subfolders. To minimize the size of your
download, please select only these subdirectories to download.
In 2016 the NEON AOP flew the PRIN site in D11 on a poor weather day to
ensure coverage of the site. The following day, the weather improved and the
site was flown again to collect good weather spectrometer data. Having
collections only one day apart provides an opportunity to assess LiDAR
uncertainty because we should expect that nothing has chnaged between the
two collects. In this exercise we will analyze the several NEON Level 3 lidar
rasters to assess the uncertainty.
Set up system
First, we'll set up our system and load needed packages.
import sys
sys.version
'3.7.7 (default, Mar 23 2020, 17:31:31) \n[Clang 4.0.1 (tags/RELEASE_401/final)]'
import gdal
import h5py
import numpy as np
from math import floor
import os
import matplotlib.pyplot as plt
Define functions
Next, we'll define a few functions that we will use throughout the code.
def raster2array(geotif_file):
metadata = {}
dataset = gdal.Open(geotif_file)
metadata['array_rows'] = dataset.RasterYSize
metadata['array_cols'] = dataset.RasterXSize
metadata['bands'] = dataset.RasterCount
metadata['driver'] = dataset.GetDriver().LongName
metadata['projection'] = dataset.GetProjection()
metadata['geotransform'] = dataset.GetGeoTransform()
mapinfo = dataset.GetGeoTransform()
metadata['pixelWidth'] = mapinfo[1]
metadata['pixelHeight'] = mapinfo[5]
metadata['ext_dict'] = {}
metadata['ext_dict']['xMin'] = mapinfo[0]
metadata['ext_dict']['xMax'] = mapinfo[0] + dataset.RasterXSize/mapinfo[1]
metadata['ext_dict']['yMin'] = mapinfo[3] + dataset.RasterYSize/mapinfo[5]
metadata['ext_dict']['yMax'] = mapinfo[3]
metadata['extent'] = (metadata['ext_dict']['xMin'],metadata['ext_dict']['xMax'],
metadata['ext_dict']['yMin'],metadata['ext_dict']['yMax'])
if metadata['bands'] == 1:
raster = dataset.GetRasterBand(1)
metadata['noDataValue'] = raster.GetNoDataValue()
metadata['scaleFactor'] = raster.GetScale()
# band statistics
metadata['bandstats'] = {} #make a nested dictionary to store band stats in same
stats = raster.GetStatistics(True,True)
metadata['bandstats']['min'] = round(stats[0],2)
metadata['bandstats']['max'] = round(stats[1],2)
metadata['bandstats']['mean'] = round(stats[2],2)
metadata['bandstats']['stdev'] = round(stats[3],2)
array = dataset.GetRasterBand(1).ReadAsArray(0,0,metadata['array_cols'],metadata['array_rows']).astype(np.float)
array[array==int(metadata['noDataValue'])]=np.nan
array = array/metadata['scaleFactor']
return array, metadata
elif metadata['bands'] > 1:
print('More than one band ... need to modify function for case of multiple bands')
This next piece of code just helps identify where the script portion of our code starts. It is not essential to the code but can be useful when running scripts.
print('Start Uncertainty Script')
Start Uncertainty Script
To start, we can define all of the input files. This will include two Digital Surface Model (DSMs) tifs from the flight days, two Digital Terrain Models (DTMs) from the flight days, and a single Canopy Height Model (CHM). In this case, all input GeoTiff rasters are a single tile of the site that measures 1000 m by 1000 m.
Since we want to know what the changed between the two days, we will create an array with any of the pixel differneces across the two arrays. To do this let's subtract the two DSMs.
Let's get some summary statistics for this DSM differences array.
diff_dsm_array_mean = np.mean(diff_dsm_array)
diff_dsm_array_std = np.std(diff_dsm_array)
print('Mean difference in DSMs: ',round(diff_dsm_array_mean,3),' (m)')
print('Standard deviations of difference in DSMs: ',round(diff_dsm_array_std,3),' (m)')
Mean difference in DSMs: 0.019 (m)
Standard deviations of difference in DSMs: 0.743 (m)
As a result we get the following:
Mean difference in DSMs: 0.019 (m)
Standard deviations of difference in DSMs: 0.743 (m)
The mean is close to zero indicating there was very little systematic bias between the two days. However, we notice that the standard deviation of the data is quite high at 0.743 meters. Generally we expect NEON LiDAR data to have an error below 0.15 meters! Let's take a look at a histogram of the DSM difference. We use the flatten function on the 2D diff_dsm_array to convert it into a 1D array which allows the hist() function to run faster.
plt.figure(1)
plt.hist(diff_dsm_array.flatten(),100)
plt.title('Histogram of PRIN DSM')
plt.xlabel('Height Difference(m)'); plt.ylabel('Frequency')
plt.show()
The histogram has long tails, obscuring the distribution near the center. To constrain the x-limits of the histogram we will use the mean and standard deviation just calculated. Since the data appears to be normally distributed, we can constrain the histogram to 95% of the data by including 2 standard deviations above and below the mean.
plt.figure(1)
plt.hist(diff_dsm_array.flatten(),100,range=[diff_dsm_array_mean-2*diff_dsm_array_std, diff_dsm_array_mean+2*diff_dsm_array_std])
plt.title('Histogram of PRIN DSM')
plt.xlabel('Height Difference(m)'); plt.ylabel('Frequency')
plt.show()
The histogram shows a wide variation in DSM differences, with those at the 95% limit at around +/- 1.5 m. Let's take a look at the spatial distribution of the errors by plotting a map of the difference between the two DSMs. Here we'll also use the extra variable in the plot function to constrain the limits of the colorbar to 95% of the observations.
It seems that there is a spatial pattern in the distribution of errors. Now let's take a look at the histogram and map for the difference in DTMs.
diff_dtm_array_mean = np.nanmean(diff_dtm_array)
diff_dtm_array_std = np.nanstd(diff_dtm_array)
print('Mean difference in DTMs: ',round(diff_dtm_array_mean,3),' (m)')
print('Standard deviations of difference in DTMs: ',round(diff_dtm_array_std,3),' (m)')
plt.figure(4)
plt.hist(diff_dtm_array.flatten()[~np.isnan(diff_dtm_array.flatten())],100,range=[diff_dtm_array_mean-2*diff_dtm_array_std, diff_dtm_array_mean+2*diff_dtm_array_std])
plt.title('Histogram of PRIN DTM')
plt.xlabel('Height Difference(m)'); plt.ylabel('Frequency')
plt.show()
plt.figure(5)
plot_band_array(diff_dtm_array,dtm1_array_metadata['extent'],'DTM Difference','Difference (m)','bwr',[diff_dtm_array_mean-2*diff_dtm_array_std, diff_dtm_array_mean+2*diff_dtm_array_std])
plt.show()
Mean difference in DTMs: 0.014 (m)
Standard deviations of difference in DTMs: 0.102 (m)
The overall magnitude of differences are smaller than in the DSM but the same spatial pattern of the error is evident.
Now, we'll plot the Canopy Height Model (CHM) of the same area. In the CHM, the tree heights above ground are represented, with all ground pixels having zero elevation. This time we'll use a colorbar which shows the ground as light green and the highest vegetation as dark green. We can set the lower limit of the color bar to zero and the upper limit to the mean canopy height to get a good color variation.
From the CHM, it appears the spatial distribution of error patterns follow the location of vegetation.
Now let's isolate only the pixels in the difference DSM that correspond to vegetation location, calcualte the mean and standard deviation and plot the associated histogram. Before displaying the histogram, we'll remove the no data values from the difference DSM and the non-zero pixels from the CHM. To keep the number of elements the same in each vector to allow element-wise logical operations in Python, we have to remove the difference DSM no data elements from the CHM array as well.
diff_dsm_array_veg_mean = np.nanmean(diff_dsm_array[chm_array!=0.0])
diff_dsm_array_veg_std = np.nanstd(diff_dsm_array[chm_array!=0.0])
plt.figure(7)
print('Mean difference in DSMs on veg points: ',round(diff_dsm_array_veg_mean,3),' (m)')
print('Standard deviations of difference in DSMs on veg points: ',round(diff_dsm_array_veg_std,3),' (m)')
plt.figure(8)
diff_dsm_array_nodata_removed = diff_dsm_array[~np.isnan(diff_dsm_array)]
chm_dsm_nodata_removed = chm_array[~np.isnan(diff_dsm_array)]
plt.hist(diff_dsm_array_nodata_removed[chm_dsm_nodata_removed!=0.0],100,range=[diff_dsm_array_veg_mean-2*diff_dsm_array_veg_std, diff_dsm_array_veg_mean+2*diff_dsm_array_veg_std])
plt.title('Histogram of PRIN DSM (veg)')
plt.xlabel('Height Difference(m)'); plt.ylabel('Frequency')
plt.show()
Mean difference in DSMs on veg points: 0.064 (m)
Standard deviations of difference in DSMs on veg points: 1.381 (m)
<Figure size 432x288 with 0 Axes>
The results show a similar mean difference of near zero, but an extremely high standard deviation of 1.381 m! Since the DSM represents the top of the tree canopy, this provides the level of uncertainty we can expect in the canopy height in forests characteristic of the PRIN site using NEON LiDAR data.
Next we'll calculate the statistics and plot the histogram of the DTM vegetated areas
diff_dtm_array_veg_mean = np.nanmean(diff_dtm_array[chm_array!=0.0])
diff_dtm_array_veg_std = np.nanstd(diff_dtm_array[chm_array!=0.0])
plt.figure(9)
print('Mean difference in DTMs on veg points: ',round(diff_dtm_array_veg_mean,3),' (m)')
print('Standard deviations of difference in DTMs on veg points: ',round(diff_dtm_array_veg_std,3),' (m)')
plt.figure(10)
diff_dtm_array_nodata_removed = diff_dtm_array[~np.isnan(diff_dtm_array)]
chm_dtm_nodata_removed = chm_array[~np.isnan(diff_dtm_array)]
plt.hist((diff_dtm_array_nodata_removed[chm_dtm_nodata_removed!=0.0]),100,range=[diff_dtm_array_veg_mean-2*diff_dtm_array_veg_std, diff_dtm_array_veg_mean+2*diff_dtm_array_veg_std])
plt.title('Histogram of PRIN DTM (veg)')
plt.xlabel('Height Difference(m)'); plt.ylabel('Frequency')
plt.show()
Mean difference in DTMs on veg points: 0.023 (m)
Standard deviations of difference in DTMs on veg points: 0.163 (m)
<Figure size 432x288 with 0 Axes>
Here we can see that the mean difference is almost zero at 0.023 m, and the variation in less than the DSM at 0.163 m.
Although the variation is reduced, it is still larger than expected for LiDAR. This is because under vegetation there may not be much laser energy reaching the ground, and those points that do may return with lower signal. The sparsity of points leads to surface interpolation over larger areas which can miss variations in the topography. Since the distribution of LIDAR and their location varied for each day, this resulted in different terrain representations and a uncertianty in the ground surface. This shows that the accuracy of LiDAR DTMs is reduced when under vegetation.
Finally, let's look at the DTM difference on only the ground points (where CHM = 0).
diff_dtm_array_ground_mean = np.nanmean(diff_dtm_array[chm_array==0.0])
diff_dtm_array_ground_std = np.nanstd(diff_dtm_array[chm_array==0.0])
print('Mean difference in DTMs on ground points: ',round(diff_dtm_array_ground_mean,3),' (m)')
print('Standard deviations of difference in DTMs on ground points: ',round(diff_dtm_array_ground_std,3),' (m)')
plt.figure(11)
plt.hist((diff_dtm_array_nodata_removed[chm_dtm_nodata_removed==0.0]),100,range=[diff_dtm_array_ground_mean-2*diff_dtm_array_ground_std, diff_dtm_array_ground_mean+2*diff_dtm_array_ground_std])
plt.title('Histogram of PRIN DTM (ground)')
plt.xlabel('Height Difference(m)'); plt.ylabel('Frequency')
plt.show()
Mean difference in DTMs on ground points: 0.011 (m)
Standard deviations of difference in DTMs on ground points: 0.068 (m)
In the open ground scenario we are able to produce the error chatracteristics we expect with a mean difference of only 0.011 m and a variation of 0.068 m.
This shows that the uncertainty we expect in the NEON LiDAR system (~0.15 m) is only valid in bare, open, hard surface scenarios. We cannot expect the accuracy of the LiDAR to reach this level when vegetation is present. Quantifying the top of the canopy is particularly difficult and can lead to uncertainty in excess of 1 m for any given pixel.
This tutorial covers how to create a hillshade from a terrain raster in Python, and demonstrates a few options for visualizing lidar-derived Digital Elevation Models.
Objectives
After completing this tutorial, you will be able to:
Understand how to read in and visualize Lidar elevation models (DTM, DSM) in Python
Plot a contour map of the DTM
Create a hillshade from the DTM
Calculate and plot Canopy Height along with hillshade and elevation
Install Python Packages
gdal
rasterio
requests
Download Data
For this lesson, we will read in Digital Terrain Model (DTM) data collected at NEON's Lower Teakettle (TEAK) site in California. This data is downloaded in the first part of the tutorial, using the Python requests package.
Additional Resources
NEON'S Airborne Observation Platform provides Algorithm Theoretical Basis Documents (ATBDs) for all of their data products. Please refer to the ATBDs below for a more in-depth understanding of how the Lidar-derived rasters are generated.
import os
import numpy as np
import requests
import rasterio as rio
from rasterio.plot import show
import matplotlib.pyplot as plt
Read in the datasets
Download Lidar Elevation Models from TEAK
To start, we will download the NEON Elevation Models (DTM and DSM) which are provided in geotiff (.tif) format. Use the download_url function below to download the data directly from the cloud storage location.
For more information on these data products, refer to the NEON Data Portal page, linked below:
# function to download data stored on the internet in a public url to a local file
def download_url(url,download_dir):
if not os.path.isdir(download_dir):
os.makedirs(download_dir)
filename = url.split('/')[-1]
r = requests.get(url, allow_redirects=True)
file_object = open(os.path.join(download_dir,filename),'wb')
file_object.write(r.content)
# define the urls for downloading the Aspect and NDVI geotiff tiles
dtm_url = "https://storage.googleapis.com/neon-aop-products/2021/FullSite/D17/2021_TEAK_5/L3/DiscreteLidar/DTMGtif/NEON_D17_TEAK_DP3_320000_4092000_DTM.tif"
dsm_url = "https://storage.googleapis.com/neon-aop-products/2021/FullSite/D17/2021_TEAK_5/L3/DiscreteLidar/DSMGtif/NEON_D17_TEAK_DP3_320000_4092000_DSM.tif"
# download the raster data using the download_url function
download_url(dtm_url,'.\data')
download_url(dsm_url,'.\data')
# display the contents in the ./data folder to confirm the download completed
os.listdir('./data')
Calculate Hillshade
Hillshade is used to visualize the hypothetical illumination value (from 0-255) of each pixel on a surface given a specified light source. To calculate hillshade, we need the zenith (altitude) and azimuth of the illumination source, as well as the slope and aspect of the terrain. The formula for hillshade is:
fig, ax = plt.subplots(1, 1, figsize=(6,6))
dtm_map = show(dtm_dataset,title='Digital Terrain Model',ax=ax);
show(dtm_dataset,contour=True, ax=ax); #overlay the contours
im = dtm_map.get_images()[0]
fig.colorbar(im, label = 'Elevation (m)', ax=ax) # add a colorbar
ax.ticklabel_format(useOffset=False, style='plain') # turn off scientific notation
Now that we have a function to generate hillshade, we need to read in the DTM raster using rasterio and then calculate hillshade using the hillshade function. We can then plot both.
# Use hillshade function on the DTM data array
hs_data = hillshade(dtm_data,225,45)
Canopy Height can be simply calculated by subtracting the Digital Terrain Model from the Digital Surface Model. While NEON's CHM is calculated using a slightly more sophisticated "pit-free" algorithm (see the ATBD linked at the top of this tutorial), in this example, we'll calculate the CHM with the simple difference formula. First, read in the DSM data set, which we previously downloaded into the data folder.