Series
Introduction to Light Detection and Ranging (LiDAR) in R
The tutorials in this series introduces Light Detection and Ranging (LiDAR) datasets. Concepts covered include how LiDAR data is collected, LiDAR as gridded, raster data, and an introduction to digital models derived from LiDAR data, including Canopy Height Models (CHM), Digital Surface Models (DSM), and Digital Terrain Models (DTM). The series introduces the concepts through videos, graphical examples, and text. The series continues with visualization of LiDAR-derived raster data using plas.io, plot.ly and R, three free, open-source tools.
Data used in this series are from the National Ecological Observatory Network (NEON) and are in .las, GeoTIFF and .csv formats.
Series Objectives
After completing the series you will:
- Know what LiDAR data are
- Understand key attributes of LiDAR data
- Know what LiDAR-derived DTM, DSM, and CHM digital models are
- Be able to visualize LiDAR-derived data in .las format using plas.io
- Be able to create a Canopy Height Model in R
- Be able to create an interactive plot.ly map of LiDAR-derived data
Things You’ll Need To Complete This Series
Setup RStudio
To complete some of the tutorials in this series, you will need an updated version of R and, preferably, RStudio installed on your computer.
R is a programming language that specializes in statistical computing. It is a powerful tool for exploratory data analysis. To interact with R, we strongly recommend using RStudio, an interactive development environment (IDE).
Download Data
Data is available for download in those tutorials that focus on teaching data skills.
The Basics of LiDAR - Light Detection and Ranging - Remote Sensing
Last Updated: Apr 2, 2026
LiDAR or Light Detection and Ranging is an active remote sensing system that can be used to measure vegetation height across wide areas. This page will introduce fundamental LiDAR (or lidar) concepts including:
- What LiDAR data are.
- The key attributes of LiDAR data.
- How LiDAR data are used to measure trees.
The Story of LiDAR
Key Concepts
Why LiDAR
Scientists often need to characterize vegetation over large regions to answer research questions at the ecosystem or regional scale. Therefore, we need tools that can estimate key characteristics over large areas because we don’t have the resources to measure each and every tree or shrub.

Remote sensing means that we aren’t actually physically measuring things with our hands. We are using sensors which capture information about a landscape and record things that we can use to estimate conditions and characteristics. To measure vegetation or other data across large areas, we need remote sensing methods that can take many measurements quickly, using automated sensors.
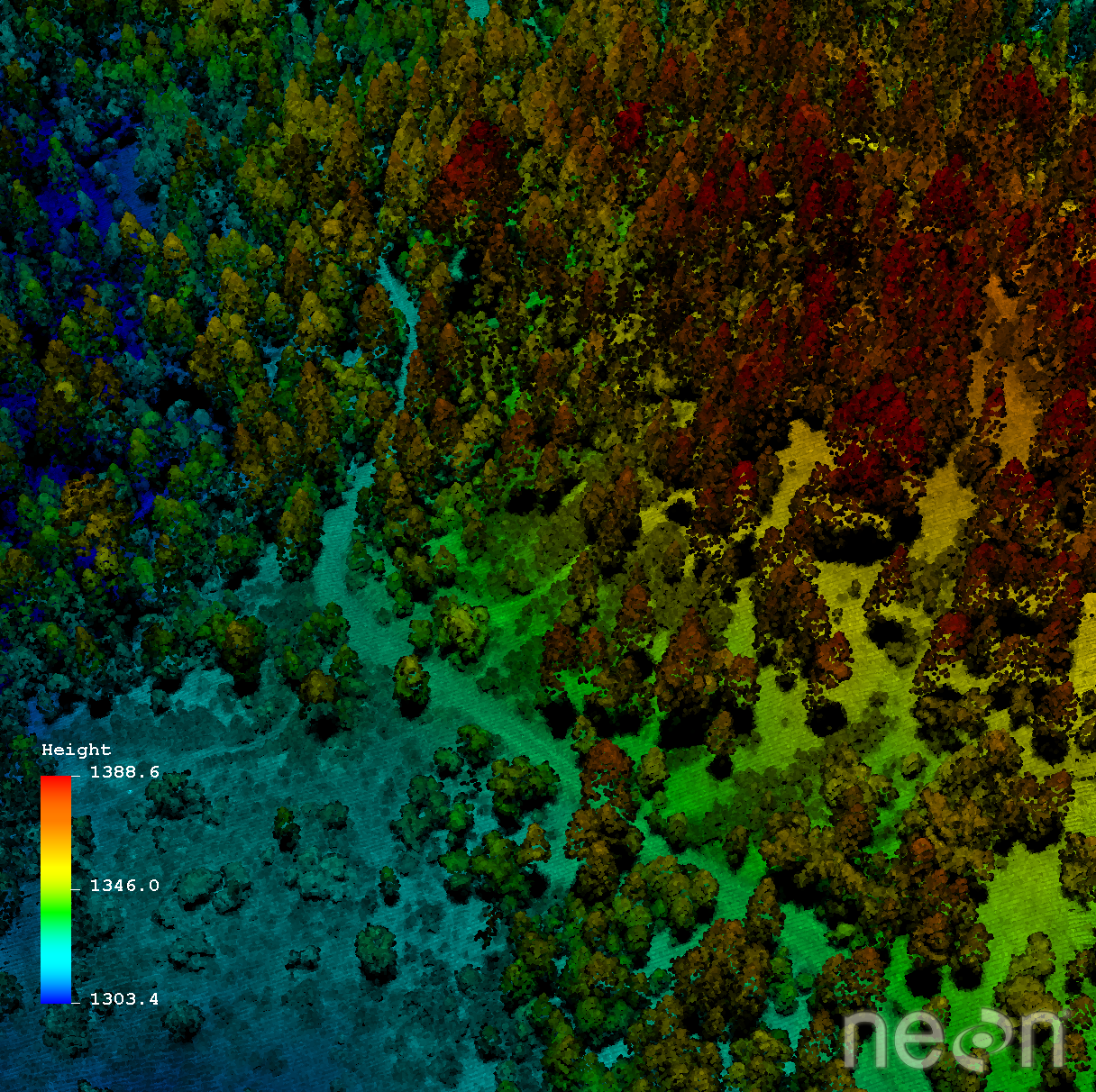
LiDAR, or Light Detection And Ranging (sometimes also referred to as active laser scanning) is one remote sensing method that can be used to map structure including vegetation height, density and other characteristics across a region. LiDAR directly measures the height and density of vegetation on the ground making it an ideal tool for scientists studying vegetation over large areas.
How LiDAR Works
How Does LiDAR Work?
LiDAR is an active remote sensing system. An active system means that the system itself generates energy - in this case, light - to measure things on the ground. In a LiDAR system, light is emitted from a rapidly firing laser. You can imagine light quickly strobing (or pulsing) from a laser light source. This light travels to the ground and reflects off of things like buildings and tree branches. The reflected light energy then returns to the LiDAR sensor where it is recorded.
A LiDAR system measures the time it takes for emitted light to travel to the ground and back, called the two-way travel time. That time is used to calculate distance traveled. Distance traveled is then converted to elevation. These measurements are made using the key components of a lidar system including a GPS that identifies the X,Y,Z location of the light energy and an Inertial Measurement Unit (IMU) that provides the orientation of the plane in the sky (roll, pitch, and yaw).
How Light Energy Is Used to Measure Trees
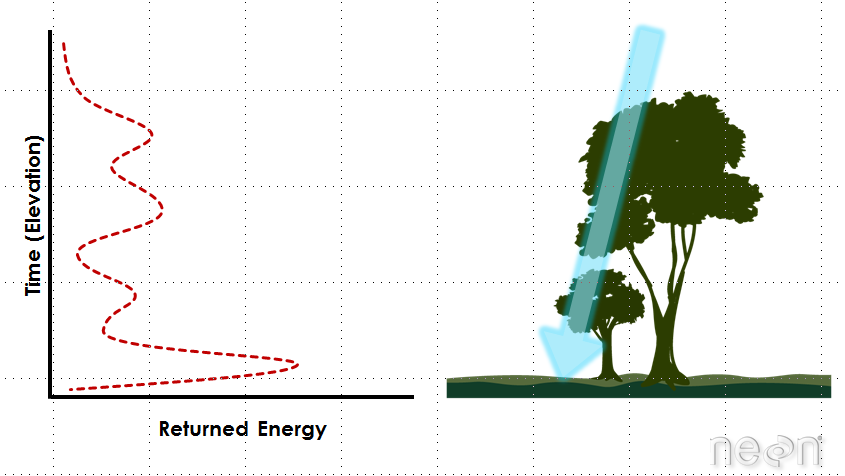
Light energy is a collection of photons. As photon that make up light moves towards the ground, they hit objects such as branches on a tree. Some of the light reflects off of those objects and returns to the sensor. If the object is small, and there are gaps surrounding it that allow light to pass through, some light continues down towards the ground. Because some photons reflect off of things like branches but others continue down towards the ground, multiple reflections (or "returns") may be recorded from one pulse of light.
LiDAR waveforms
The distribution of energy that returns to the sensor creates what we call a waveform. The amount of energy that returned to the LiDAR sensor is known as "intensity". The areas where more photons or more light energy returns to the sensor create peaks in the distribution of energy. Theses peaks in the waveform often represent objects on the ground like - a branch, a group of leaves or a building.
How Scientists Use LiDAR Data
There are many different uses for LiDAR data.
- LiDAR data classically have been used to derive high resolution elevation data models

- LiDAR data have also been used to derive information about vegetation structure including:
- Canopy Height
- Canopy Cover
- Leaf Area Index
- Vertical Forest Structure
- Species identification (if a less dense forests with high point density LiDAR)

Discrete vs. Full Waveform LiDAR
A waveform or distribution of light energy is what returns to the LiDAR sensor. However, this return may be recorded in two different ways.
- A Discrete Return LiDAR System records individual (discrete) points for the peaks in the waveform curve. Discrete return LiDAR systems identify peaks and record a point at each peak location in the waveform curve. These discrete or individual points are called returns. A discrete system may record 1-11+ returns from each laser pulse.
- A Full Waveform LiDAR System records a distribution of returned light energy. Full waveform LiDAR data are thus more complex to process, however they can often capture more information compared to discrete return LiDAR systems. One example research application for full waveform LiDAR data includes mapping or modelling the understory of a canopy.
LiDAR File Formats
Whether it is collected as discrete points or full waveform, most often LiDAR data are available as discrete points. A collection of discrete return LiDAR points is known as a LiDAR point cloud.
The commonly used file format to store LIDAR point cloud data is called ".las" which is a format supported by the American Society of Photogrammetry and Remote Sensing (ASPRS). Recently, the .laz format has been developed by Martin Isenberg of LasTools. The differences is that .laz is a highly compressed version of .las.
Data products derived from LiDAR point cloud data are often raster files that may be in GeoTIFF (.tif) formats.
LiDAR Data Attributes: X, Y, Z, Intensity and Classification
LiDAR data attributes can vary, depending upon how the data were collected and processed. You can determine what attributes are available for each lidar point by looking at the metadata. All lidar data points will have an associated X,Y location and Z (elevation) values. Most lidar data points will have an intensity value, representing the amount of light energy recorded by the sensor.
Some LiDAR data will also be "classified" -- not top secret, but with specifications about what the data represent. Classification of LiDAR point clouds is an additional processing step. Classification simply represents the type of object that the laser return reflected off of. So if the light energy reflected off of a tree, it might be classified as "vegetation" point. And if it reflected off of the ground, it might be classified as "ground" point.
Some LiDAR products will be classified as "ground/non-ground". Some datasets will be further processed to determine which points reflected off of buildings and other infrastructure. Some LiDAR data will be classified according to the vegetation type.
Exploring 3D LiDAR data in a free Online Viewer
Check out our tutorial on viewing LiDAR point cloud data using the Plas.io online viewer: Plas.io: Free Online Data Viz to Explore LiDAR Data. The Plas.io viewer used in this tutorial was developed by Martin Isenberg of Las Tools and his colleagues.
Summary
- A LiDAR system uses a laser, a GPS and an IMU to estimate the heights of objects on the ground.
- Discrete LiDAR data are generated from waveforms -- each point represent peak energy points along the returned energy.
- Discrete LiDAR points contain an x, y and z value. The z value is what is used to generate height.
- LiDAR data can be used to estimate tree height and even canopy cover using various methods.
Additional Resources
- What is the LAS format?
- Using .las with Python? las: python ingest
- Specifications for las v1.3
What is a CHM, DSM and DTM? About Gridded, Raster LiDAR Data
Last Updated: Apr 2, 2026
LiDAR Point Clouds
Each point in a LiDAR dataset has a X, Y, Z value and other attributes. The points may be located anywhere in space are not aligned within any particular grid.
LiDAR point clouds are typically available in a .las file format. The .las file format is a compressed format that can better handle the millions of points that are often associated with LiDAR data point clouds.
Common LiDAR Data Products
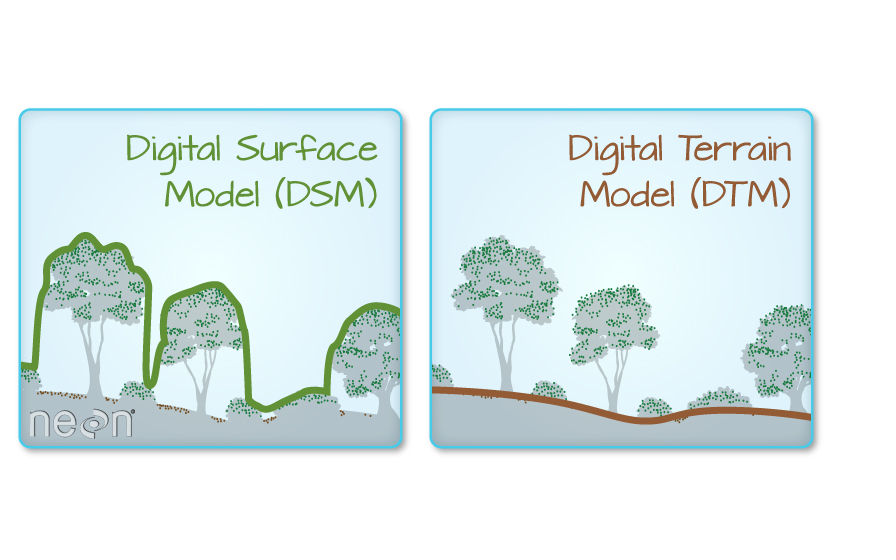
The Digital Terrain Model (DTM) product represents the elevation of the ground, while the Digital Surface Model (DSM) product represents the elevation of the tallest surfaces at that point. Imagine draping a sheet over the canopy of a forest, the Digital Elevation Model (DEM) contours with the heights of the trees where there are trees but the elevation of the ground when there is a clearing in the forest.
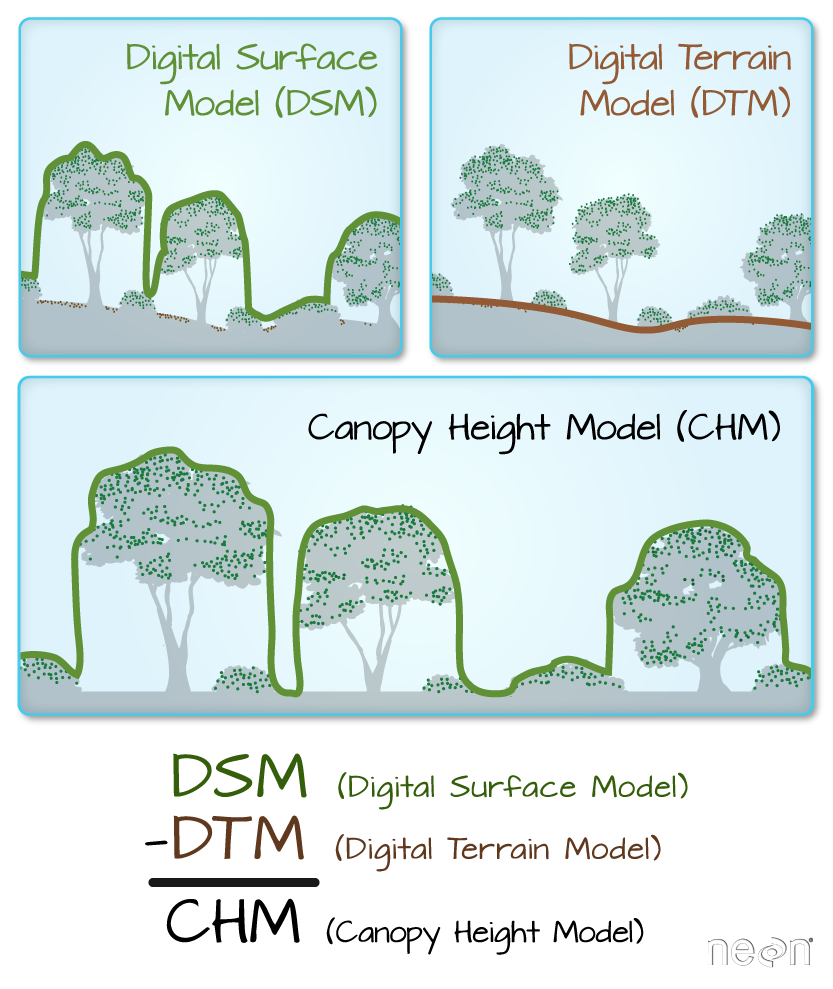
The Canopy height model represents the difference between a Digital Terrain Model and a Digital Surface Model (DSM - DTM = CHM) and gives you the height of the objects (in a forest, the trees) that are on the surface of the earth.
Free Point Cloud Viewers for LiDAR Point Clouds
For more on viewing LiDAR point cloud data using the Plas.io online viewer, see our tutorial Plas.io: Free Online Data Viz to Explore LiDAR Data.
Check out our Structural Diversity tutorial for another useful LiDAR point cloud viewer available through RStudio, Calculating Forest Structural Diversity Metrics from NEON LiDAR Data
3D Models of NEON Site: SJER (San Joaquin Experimental Range)
Click on the images to view interactive 3D models of San Joaquin Experimental Range site.
 |
 |
 |
Gridded, or Raster, LiDAR Data Products
LiDAR data products are most often worked within a gridded or raster data format. A raster file is a regular grid of cells, all of which are the same size.
A few notes about rasters:
- Each cell is called a pixel.
- And each pixel represents an area on the ground.
- The resolution of the raster represents the area that each pixel represents on the ground. So, for instance if the raster is 1 m resolution, that simple means that each pixel represents a 1m by 1m area on the ground.

Raster data can have attributes associated with them as well. For instance in a LiDAR-derived digital elevation model (DEM), each cell might represent a particular elevation value. In a LIDAR-derived intensity image, each cell represents a LIDAR intensity value.
LiDAR Related Metadata
In short, when you go to download LiDAR data the first question you should ask is what format the data are in. Are you downloading point clouds that you might have to process? Or rasters that are already processed for you. How do you know?
- Check out the metadata!
- Look at the file format - if you are downloading a .las file, then you are getting points. If it is .tif, then it is a post-processing raster file.
Create Useful Data Products from LiDAR Data
Classify LiDAR Point Clouds
LiDAR data points are vector data. LiDAR point clouds are useful because they tell us something about the heights of objects on the ground. However, how do we know whether a point reflected off of a tree, a bird, a building or the ground? In order to develop products like elevation models and canopy height models, we need to classify individual LiDAR points. We might classify LiDAR points into classes including:
- Ground
- Vegetation
- Buildings
LiDAR point cloud classification is often already done when you download LiDAR point clouds but just know that it’s not to be taken for granted! Programs such as lastools, fusion and terrascan are often used to perform this classification. Once the points are classified, they can be used to derive various LiDAR data products.
Create A Raster From LiDAR Point Clouds
There are different ways to create a raster from LiDAR point clouds.
Point to Raster Methods - Basic Gridding
Let's look one of the most basic ways to create a raster file points - basic gridding. When you perform a gridding algorithm, you are simply calculating a value, using point data, for each pixels in your raster dataset.
- To begin, a grid is placed on top of the LiDAR data in space. Each cell in the grid has the same spatial dimensions. These dimensions represent that particular area on the ground. If we want to derive a 1 m resolution raster from the LiDAR data, we overlay a 1m by 1m grid over the LiDAR data points.
- Within each 1m x 1m cell, we calculate a value to be applied to that cell, using the LiDAR points found within that cell. The simplest method of doing this is to take the max, min or mean height value of all lidar points found within the 1m cell. If we use this approach, we might have cells in the raster that don't contains any lidar points. These cells will have a "no data" value if we process our raster in this way.

Point to Raster Methods - Interpolation
A different approach is to interpolate the value for each cell.
- In this approach we still start with placing the grid on top of the LiDAR data in space.
- Interpolation considers the values of points outside of the cell in addition to points within the cell to calculate a value. Interpolation is useful because it can provide us with some ability to predict or calculate cell values in areas where there are no data (or no points). And to quantify the error associated with those predictions which is useful to know, if you are doing research.
For learning more on how to work with LiDAR and Raster data more generally in R, please refer to the Data Carpentry's Introduction to Geospatial Raster and Vector Data with R lessons.
Create a Canopy Height Model from Lidar-derived rasters in R
Last Updated: Jul 1, 2026
A common analysis using lidar data are to derive top of the canopy height values from the lidar data. These values are often used to track changes in forest structure over time, to calculate biomass, and even leaf area index (LAI). Let's dive into the basics of working with raster formatted lidar data in R!
Learning Objectives
After completing this tutorial, you will be able to:
- Work with digital terrain model (DTM) & digital surface model (DSM) raster files.
- Carry out basic raster math using the
terrapackage. - Create a canopy height model (CHM) raster from DTM & DSM rasters.
- Understand the basics of the pit-free CHM algoirthm used to generate NEON's Ecosystem Structure data product.
Things You’ll Need To Complete This Tutorial
You will need the most current version of R and, preferably, RStudio loaded
on your computer to complete this tutorial.
As of June 2026, NEON requires an API token for data downloads, to reduce bot scraping and improve user support. Tokens can be generated in NEON data portal user accounts - log in to your account or create one, and go to the API Tokens section. For best practices in storing and using tokens, follow the instructions here.
Install R Packages
-
terra:
install.packages("terra") -
neonUtilities:
install.packages("neonUtilities")
More on Packages in R - Adapted from Software Carpentry.
Download Data
Lidar elevation raster data are downloaded using the R neonUtilities::byTileAOP() function in the script.
These remote sensing data files provide information on the vegetation at the National Ecological Observatory Network's San Joaquin Experimental Range site. The entire datasets can be accessed from the NEON Data Portal.
R Script & Challenge Code: NEON data lessons often contain challenges to reinforce skills. If available, the code for challenge solutions is found in the downloadable R script of the entire lesson, available in the footer of each lesson page.
Recommended Reading
What is a CHM, DSM and DTM? About Gridded, Raster LiDAR DataCreate a Lidar-derived Canopy Height Model (CHM)
The National Ecological Observatory Network (NEON) provides lidar-derived data products including the 1) Digital Terrain Model and Digital Surface Model (DTM/DSM), 2) Slope and Aspect, and 3) Ecosystem Structure or Canopy Height Model (CHM). These products come in the GeoTIFF format, which is a .tif raster format that is spatially located on the earth.
In this tutorial, we create a Canopy Height Model. The Canopy Height Model (CHM), represents the heights of the trees on the ground. We can derive the CHM by subtracting the ground elevation from the elevation of the top of the surface (or the tops of the trees).
We will use the terra R package to work with the the lidar-derived Digital
Surface Model (DSM) and the Digital Terrain Model (DTM).
# Load needed packages and set API token
library(terra)
library(neonUtilities)
token <- Sys.getenv("NEON_TOKEN")
Set the data directory where downloaded data will be saved.
data_dir="~/data/" #This will depend on your local environment
We can use the neonUtilities function byTileAOP to download a single DTM and DSM tile at SJER. Both the DTM and DSM are delivered under the Elevation - LiDAR (DP3.30024.001) data product.
You can run help(byTileAOP) to see more details on what the various inputs are. For this exercise, we'll specify the UTM Easting and Northing to be (257500, 4112500), which will download the tile with the lower left corner (257000,4112000). By default, the function will check the size total size of the download and ask you whether you wish to proceed (y/n). You can set check.size=FALSE if you want to download without a prompt. This example will not be very large (~8MB), since it is only downloading two single-band rasters (plus some associated metadata).
byTileAOP(dpID='DP3.30024.001',
site='SJER',
year='2021',
easting=257500,
northing=4112500,
check.size=TRUE, # set to FALSE if you don't want to enter y/n
savepath = data_dir,
token=token)
## Downloading 2 files
##
|
| | 0%
|
|==============================================================================================| 100%
## Successfully downloaded 2 files to ~/data//DP3.30024.001
This file will be downloaded into a nested subdirectory under the ~/data folder, inside a folder named DP3.30024.001 (the Data Product ID). The files should show up in these locations: ~/data/DP3.30024.001/neon-aop-products/2021/FullSite/D17/2021_SJER_5/L3/DiscreteLidar/DSMGtif/NEON_D17_SJER_DP3_257000_4112000_DSM.tif and ~/data/DP3.30024.001/neon-aop-products/2021/FullSite/D17/2021_SJER_5/L3/DiscreteLidar/DTMGtif/NEON_D17_SJER_DP3_257000_4112000_DTM.tif.
Now we can read in the files. You can move the files to a different location (eg. shorten the path), but make sure to change the path that points to the file accordingly.
# Define the DSM and DTM file names, including the full path
dsm_file <- paste0(data_dir,"DP3.30024.001/neon-aop-products/2021/FullSite/D17/2021_SJER_5/L3/DiscreteLidar/DSMGtif/NEON_D17_SJER_DP3_257000_4112000_DSM.tif")
dtm_file <- paste0(data_dir,"DP3.30024.001/neon-aop-products/2021/FullSite/D17/2021_SJER_5/L3/DiscreteLidar/DTMGtif/NEON_D17_SJER_DP3_257000_4112000_DTM.tif")
First, we will read in the Digital Surface Model (DSM). The DSM represents the elevation of the top of the objects on the ground (trees, buildings, etc).
# assign raster to object
dsm <- rast(dsm_file)
# view info about the raster.
dsm
## class : SpatRaster
## size : 1000, 1000, 1 (nrow, ncol, nlyr)
## resolution : 1, 1 (x, y)
## extent : 257000, 258000, 4112000, 4113000 (xmin, xmax, ymin, ymax)
## coord. ref. : WGS 84 / UTM zone 11N (EPSG:32611)
## source : NEON_D17_SJER_DP3_257000_4112000_DSM.tif
## name : NEON_D17_SJER_DP3_257000_4112000_DSM
# plot the DSM
plot(dsm, main="Lidar Digital Surface Model \n SJER, California")
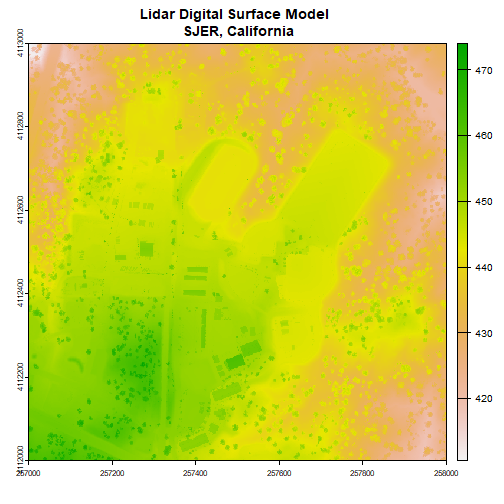
Note the resolution, extent, and coordinate reference system (CRS) of the raster. To do later steps, our DTM will need to be the same.
Next, we will import the Digital Terrain Model (DTM) for the same area. The DTM represents the ground (terrain) elevation.
# import the digital terrain model
dtm <- rast(dtm_file)
plot(dtm, main="Lidar Digital Terrain Model \n SJER, California")
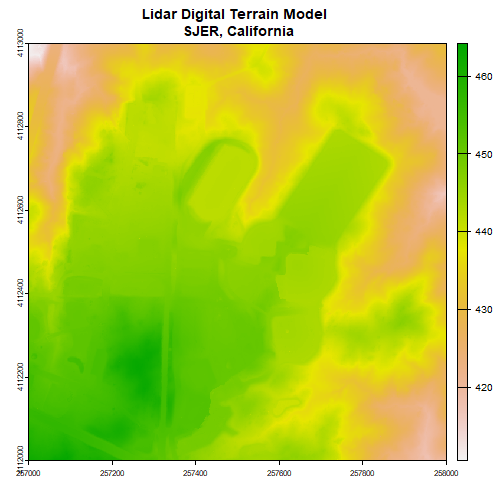
With both of these rasters now loaded, we can create the Canopy Height Model (CHM). The CHM represents the difference between the DSM and the DTM or the height of all objects on the surface of the earth.
To do this we perform some basic raster math to calculate the CHM. You can perform the same raster math in a GIS program like QGIS.
When you do the math, make sure to subtract the DTM from the DSM or you'll get trees with negative heights!
# use raster math to create CHM
chm <- dsm - dtm
# view CHM attributes
chm
## class : SpatRaster
## size : 1000, 1000, 1 (nrow, ncol, nlyr)
## resolution : 1, 1 (x, y)
## extent : 257000, 258000, 4112000, 4113000 (xmin, xmax, ymin, ymax)
## coord. ref. : WGS 84 / UTM zone 11N (EPSG:32611)
## source(s) : memory
## varname : NEON_D17_SJER_DP3_257000_4112000_DSM
## name : NEON_D17_SJER_DP3_257000_4112000_DSM
## min value : 0
## max value : 24.130005
plot(chm, main="Lidar CHM - SJER, California")
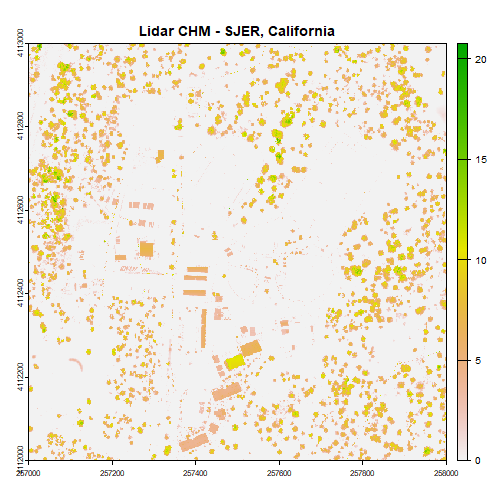
We've now created a CHM from our DSM and DTM. What do you notice about the canopy cover at this location in the San Joaquin Experimental Range?
Pit-Free Canopy Height Model
Note that NEON's Ecosystem Structure (or CHM) data product is not a simple difference between the DSM and DTM. Directly subtracting the DTM from the DSM to determine a CHM can introduce artifacts into the CHM known as data pits. Data pits manifest as abnormally low elevation pixels within a tree crown and underestimate the true canopy height, and are a commonly observed problem in CHMs derived from LiDAR. To address this issue, NEON uses a "pit-free" CHM algorithm, following the method of Khosravipour et al. (2014). To read more about how the NEON CHM is derived, please reference the Ecosystem Structure ATBD.
Challenge: Basic Raster Math
Convert the CHM from meters to feet and plot it.
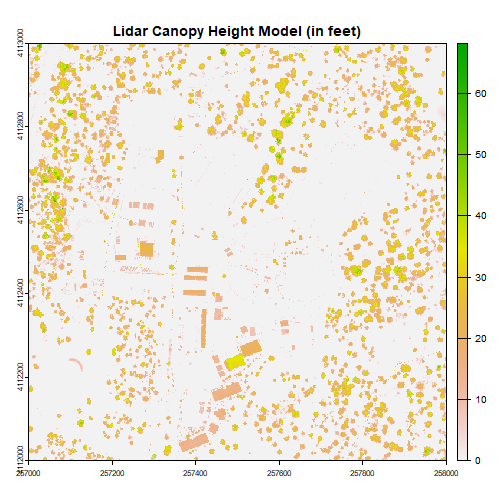
We can write out the CHM as a GeoTiff using the writeRaster() function.
# write out the CHM in tiff format.
writeRaster(chm,paste0(wd,"CHM_SJER.tif"),"GTiff")
We've now successfully created a canopy height model using basic raster math -- in
R! We can bring the CHM_SJER.tif file into QGIS (or any GIS program) and look
at it.
Consider checking out the tutorial Compare tree height measured from the ground to a Lidar-based Canopy Height Model to compare a LiDAR-derived CHM with ground-based observations!
References:
Khosravipour, A., Skidmore, A. K., Isenburg, M., Wang, T., & Hussin, Y. A. (2014). Generating pit-free canopy height models from airborne lidar. Photogrammetric Engineering & Remote Sensing, 80(9), 863–872.
Get Lesson Code
Going On The Grid -- An Intro to Gridding & Spatial Interpolation
Last Updated: Apr 2, 2026
In this tutorial was originally created for an ESA brown-bag workshop. Here we present the main graphics and topics covered in the workshop.
Additional Resources
- Learn more about LiDAR data in our tutorial The Basics of LiDAR - Light Detection and Ranging - Remote Sensing.
- Learn more about Digital Surface Models, Digital Terrain Models and Canopy Height Models in our tutorial What is a CHM, DSM and DTM? About Gridded, Raster LiDAR Data.
How Does LiDAR Works?
About Rasters
For a full tutorial on rasters & raster data, please go through the Intro to Raster Data in R tutorial which provides a foundational concepts even if you aren't working with R.
A raster is a dataset made up of cells or pixels. Each pixel represents a value associated with a region on the earth’s surface.
For more on raster resolution, see our tutorial on The Relationship Between Raster Resolution, Spatial Extent & Number of Pixels.
Creating Surfaces (Rasters) From Points
There are several ways that we can get from the point data collected by lidar to the surface data that we want for different Digital Elevation Models or similar data we use in analyses and mapping.
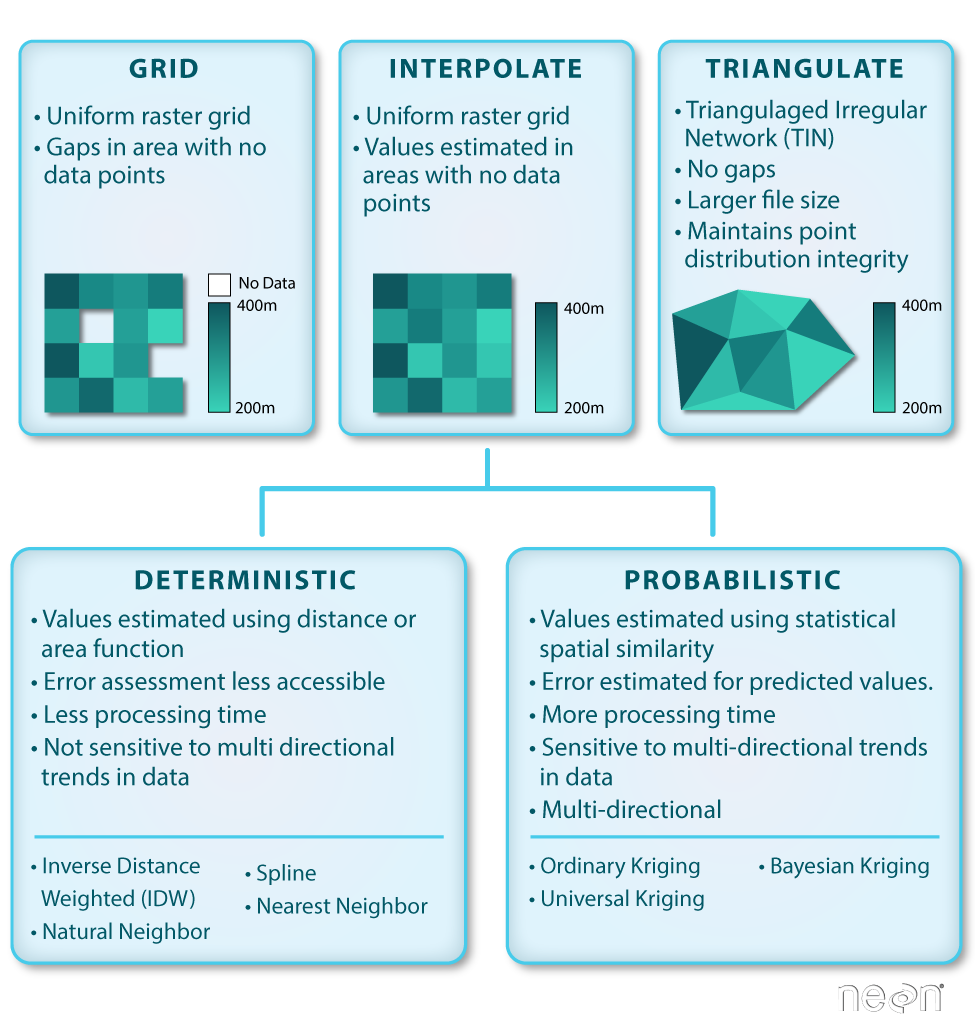
Basic gridding does not allow for the recovery/classification of data in any area where data are missing. Interpolation (including Triangulated Irregular Network (TIN) Interpolation) allows for gaps to be covered so that there are not holes in the resulting raster surface.
Interpolation can be done in a number of different ways, some of which are deterministic and some are probabilistic.
Gridding Points
When creating a raster, you may chose to perform a direct gridding of the data.
This means that you calculate one value for every cell in the raster where there
are sample points. This value may be a mean of all points, a max, min or some other
mathematical function. All other cells will then have no data values associated with
them. This means you may have gaps in your data if the point spacing is not well
distributed with at least one data point within the spatial coverage of each raster
cell.

We can create a raster from points through a process called gridding. Gridding is the process of taking a set of points and using them to create a surface composed of a regular grid.
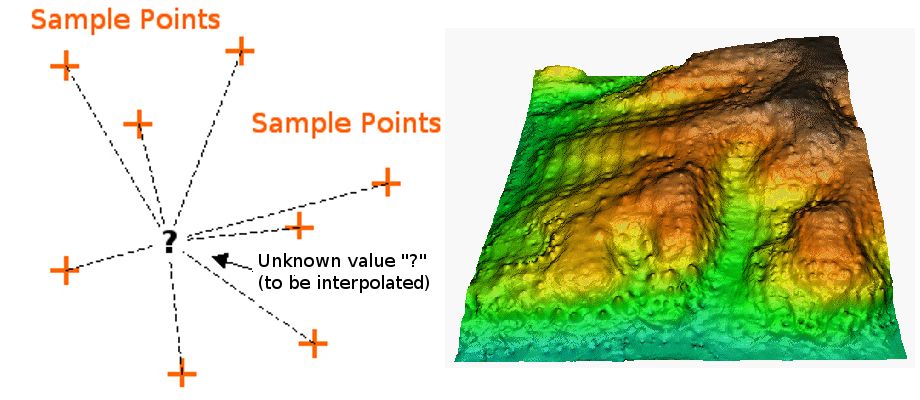
Spatial Interpolation
Spatial interpolation involves calculating the value for a query point (or a raster cell) with an unknown value from a set of known sample point values that are distributed across an area. There is a general assumption that points closer to the query point are more strongly related to that cell than those farther away. However this general assumption is applied differently across different interpolation functions.

Deterministic & Probabilistic Interpolators
There are two main types of interpolation approaches:
- Deterministic: create surfaces directly from measured points using a weighted distance or area function.
- Probabilistic (Geostatistical): utilize the statistical properties of the measured points. Probabilistic techniques quantify the spatial auto-correlation among measured points and account for the spatial configuration of the sample points around the prediction location.
Different methods of interpolation are better for different datasets. This table lays out the strengths of some of the more common interpolation methods.
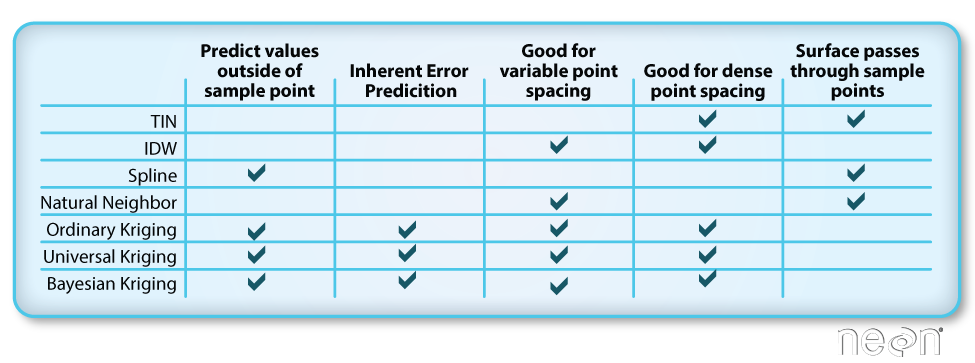
We will focus on deterministic methods in this tutorial.
Deterministic Interpolation Methods
Let's look at a few different deterministic interpolation methods to understand how different methods can affect an output raster.
Inverse Distance Weighted (IDW)
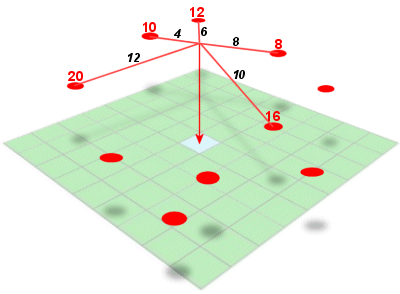
Inverse distance weighted (IDW) interpolation calculates the values of a query point (a cell with an unknown value) using a linearly weighted combination of values from nearby points.
Key Attributes of IDW Interpolation
- The raster is derived based upon an assumed linear relationship between the location of interest and the distance to surrounding sample points. In other words, sample points closest to the cell of interest are assumed to be more related to its value than those further away.ID
- Bounded/exact estimation, hence can not interpolate beyond the min/max range of data point values. This estimate within the range of existing sample point values can yield "flattened" peaks and valleys -- especially if the data didn't capture those high and low points.
- Interpolated points are average values
- Good for point data that are equally distributed and dense. Assumes a consistent trend or relationship between points and does not accommodate trends within the data(e.g. east to west, elevational, etc).
Power
The power value changes the "weighting" of the IDW interpolation by specifying how strongly points further away from the query point impact the calculated value for that point. Power values range from 0-3+ with a default settings generally being 2. A larger power value produces a more localized result - values further away from the cell have less impact on it's calculated value, values closer to the cell impact it's value more. A smaller power value produces a more averaged result where sample points further away from the cell have a greater impact on the cell's calculated value.
For visualizations of IDW interpolation, see Jochen Albrecht's Inverse Distance Weighted 3D Concepts Lecture.
The impacts of power:
-
lower power values more averaged result, potential for a smoother surface. As power decreases, the influence of sample points is larger. This yields a smoother surface that is more averaged.
-
greater power values: more localized result, potential for more peaks and valleys around sample point locations. As power increases, the influence of sample points falls off more rapidly with distance. The query cell values become more localized and less averaged.
IDW Take Home Points
IDW is good for:
- Data whose distribution is strongly (and linearly) correlated with distance. For example, noise falls off very predictably with distance.
- Providing explicit control over the influence of distance (compared to Spline or Kriging).
IDW is not so good for:
- Data whose distribution depends on more complex sets of variables because it can account only for the effects of distance.
Other features:
- You can create a smoother surface by decreasing the power, increasing the number of sample points used or increasing the search (sample points) radius.
- You can create a surface that more closely represents the peaks and dips of your sample points by decreasing the number of sample points used, decreasing the search radius or increasing the power.
- You can increase IDW surface accuracy by adding breaklines to the interpolation process that serve as barriers. Breaklines represent abrupt changes in elevation, such as cliffs.
Spline
Spline interpolation fits a curved surface through the sample points of your dataset. Imagine stretching a rubber sheet across your points and gluing it to each sample point along the way -- what you get is a smooth stretched sheet with bumps and valleys. Unlike IDW, spline can estimate values above and below the min and max values of your sample points. Thus it is good for estimating high and low values not already represented in your data.
For visualizations of Spline interpolation, see Jochen Albrecht's Spline 3D Concepts Lecture.
Regularized & Tension Spline
There are two types of curved surfaces that can be fit when using spline interpolation:
-
Tension spline: a flatter surface that forces estimated values to stay closer to the known sample points.
-
Regularized spline: a more elastic surface that is more likely to estimate above and below the known sample points.
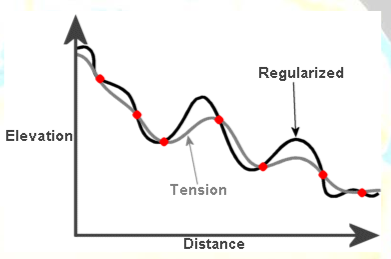
For more on spline interpolation, see ESRI's How Splines Work background materials.
Spline Take Home Points
Spline is good for:
- Estimating values outside of the range of sample input data.
- Creating a smooth continuous surface.
Spline is not so good for:
- Points that are close together and have large value differences. Slope calculations can yield over and underestimation.
- Data with large, sudden changes in values that need to be represented (e.g., fault lines, extreme vertical topographic changes, etc). NOTE: some tools like ArcGIS have introduced a spline with barriers function in recent years.
Natural Neighbor Interpolation
Natural neighbor interpolation finds the closest subset of data points to the query point of interest. It then applies weights to those points to calculate an average estimated value based upon their proportionate areas derived from their corresponding Voronoi polygons (see figure below for definition). The natural neighbor interpolator adapts locally to the input data using points surrounding the query point of interest. Thus there is no radius, number of points or other settings needed when using this approach.
This interpolation method works equally well on regular and irregularly spaced data.

Natural neighbor interpolation uses the area of each Voronoi polygon associated with the surrounding points to derive a weight that is then used to calculate an estimated value for the query point of interest.
To calculate the weighted area around a query point, a secondary Voronoi diagram is created using the immediately neighboring points and mapped on top of the original Voronoi diagram created using the known sample points (image below).

For more on natural neighbor interpolation, see ESRI's How Natural Neighbor Works documentation.
Natural Neighbor Take Home Points
Natural Neighbor Interpolation is good for:
- Data where spatial distribution is variable (and data that are equally distributed).
- Categorical data.
- Providing a smoother output raster.
Natural Neighbor Interpolation is not as good for:
- Data where the interpolation needs to be spatially constrained (to a particular number of points of distance).
- Data where sample points further away from or beyond the immediate "neighbor points" need to be considered in the estimation.
Other features:
- Good as a local interpolator
- Interpolated values fall within the range of values of the sample data
- Surface passes through input samples; not above or below
- Supports breaklines
Triangulated Irregular Network (TIN)
The Triangulated Irregular Network (TIN) is a vector based surface where sample points (nodes) are connected by a series of edges creating a triangulated surface. The TIN format remains the most true to the point distribution, density and spacing of a dataset. It also may yield the largest file size!

- For more on the TIN process see this information from ESRI: Overview of TINs
Interpolation in R, GrassGIS, or QGIS
These additional resources point to tools and information for gridding in R, GRASS GIS and QGIS.
R functions
The packages and functions maybe useful when creating grids in R.
-
gstat::idw() -
stats::loess() -
akima::interp() -
fields::Tps() -
fields::splint() -
spatial::surf.ls() -
geospt::rbf()
QGIS tools
- Check out the documentation on different interpolation plugins Interpolation
- Check out the documentation on how to convert a vector file to a raster: Rasterize (vector to raster).
The QGIS processing toolbox provides easy access to Grass commands.
GrassGIS commands
- Check out the documentation on GRASS GIS Integration Starting the GRASS plugin
The following commands may be useful if you are working with GrassGIS.
-
v.surf.idw- Surface interpolation from vector point data by Inverse Distance Squared Weighting -
v.surf.bspline- Bicubic or bilinear spline interpolation with Tykhonov regularization -
v.surf.rst- Spatial approximation and topographic analysis using regularized spline with tension -
v.to.rast.value- Converts (rasterize) a vector layer into a raster layer -
v.delaunay- Creates a Delaunay triangulation from an input vector map containing points or centroids -
v.voronoi- Creates a Voronoi diagram from an input vector layer containing points